
本文来自微信公众号“半导体产业纵横”。
相同任务下,该芯片实现片上学习的能耗仅为先进工艺下专用集成电路(ASIC)系统的3%。
当前,生成式人工智能已引爆新一轮智能革命的发展浪潮,大算力支撑下的人工智能技术极大改变着人类的生产生活方式。可随之而来的海量参数令算力需求持续攀升,如何解决庞大的算力缺口,实现能效比的大幅提升,正在变得日益迫切。高算力、高能效芯片作为算力的具体载体,已成为驱动本轮智能革命发展的核心底座,更是推动人类社会不断发展的动力源泉。
面向传统存算分离架构制约算力提升的重大挑战,清华大学集成电路学院吴华强教授、高滨副教授聚焦忆阻器存算一体技术研究,探索实现计算机系统新范式。
忆阻器存算一体技术从底层器件、电路架构和计算理论全面颠覆了冯·诺依曼传统计算架构,可实现算力和能效的跨越式提升,同时,该技术还可利用底层器件的学习特性,支持实时片上学习,赋能基于本地学习的边缘训练新场景。当前国际上的相关研究主要集中在忆阻器阵列层面的学习功能演示,然而实现全系统集成的、支持高效片上学习的忆阻器芯片仍面临较大挑战,至今还未实现,主要在于传统的反向传播训练算法所要求的高精度权重更新方式与忆阻器实际特性的适配性较差。
为解决上述难题,清华大学集成电路学院教授吴华强、副教授高滨基于存算一体计算范式,研制出全球首颗全系统集成的、支持高效片上学习(机器学习能在硬件端直接完成)的忆阻器存算一体芯片,在支持片上学习的忆阻器存算一体芯片领域取得重大突破,有望促进人工智能、自动驾驶可穿戴设备等领域发展。相关成果在线发表于最新一期的《科学》。

忆阻器存算一体学习芯片及测试系统
据介绍,该芯片实现片上学习的能耗仅为先进工艺下专用集成电路(ASIC)系统的1/35,同时有望实现75倍的能效提升。
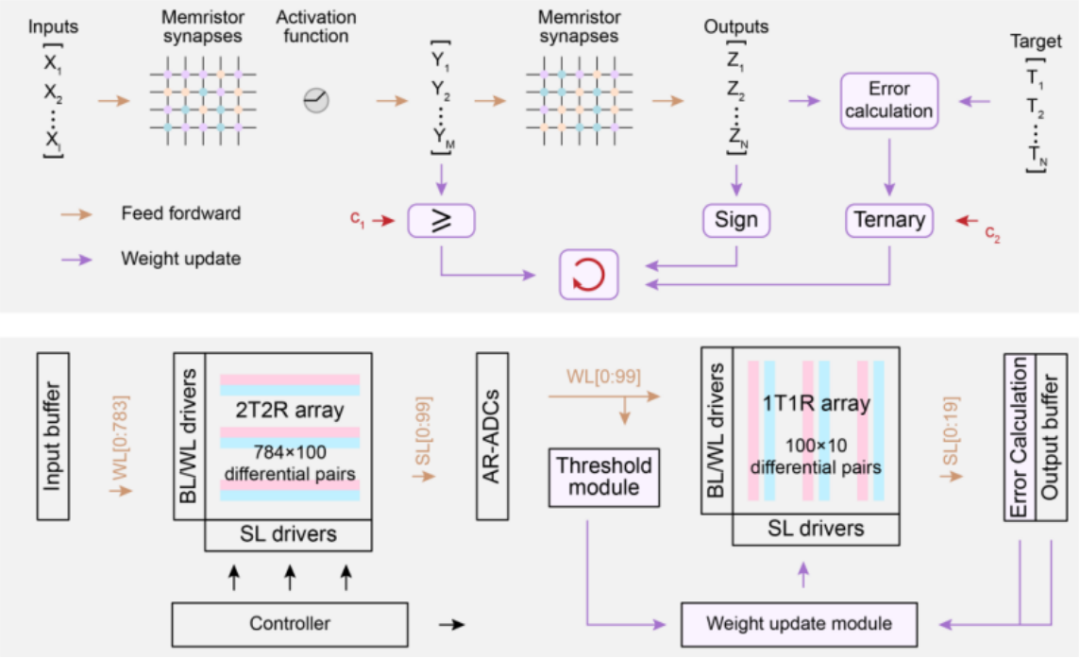
基于忆阻器存算一体实现高效片上学习的通用算法和架构
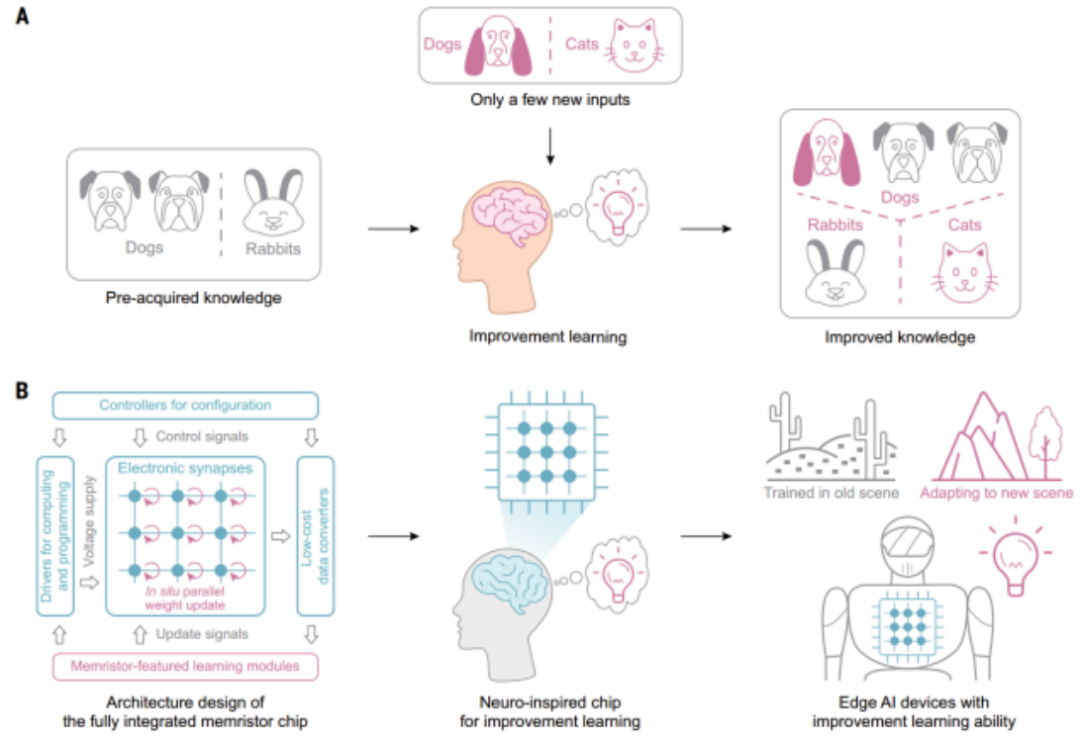
利用神经启发的忆阻器芯片进行边缘学习

小车自动追踪控制的增量学习演示
相同任务下,该芯片实现片上学习的能耗仅为先进工艺下专用集成电路(ASIC)系统的3%,展现出卓越的能效优势,极具满足人工智能时代高算力需求的应用潜力,为突破冯·诺依曼传统计算架构下的能效瓶颈提供了一种创新发展路径。
“存算一体片上学习在实现更低延迟和更小能耗的同时,能够有效保护用户隐私和数据。”博士后姚鹏介绍,该芯片参照仿生类脑处理方式,可实现不同任务的快速“片上训练”与“片上识别”,能够有效完成边缘计算场景下的增量学习任务,以极低的耗电适应新场景、学习新知识,以满足用户的个性化需求。
比如,有些人习惯在数字“7”的中间加一短横。一开始,智能芯片并不认识这个符号,然而训练了两三个这样书写的“7”后,它就能准确将其识别为数字“7”。
在复杂多变的国际形势下,突破“卡脖子”技术仍是当下的重点。
面对先进研发设备短缺等现实问题,团队成员都有着些许的茫然,每一步走的是否正确,结果能否达到预期,工艺还能否更加优化……这些都是压在每个人身上的巨石。
首先,是技术挑战。忆阻器芯片的研发涉及到材料科学、物理学、电子工程等多学科的前沿知识。在诸多技术难题中,首先要解决的是如何实现忆阻器件的大规模集成。通过大量实验和理论研究,团队提出了架构-电路-工艺协同优化方法,为存算一体系统的设计提供了指导。
其次,是工程挑战。有了大规模集成的工艺、关键的电路设计,如何克服底层多尺度非理想导致的误差,集合成一个高效的系统芯片?在团队老师和学生的共同努力下,研究提出STELLAR架构,完成算法优化及仿真实验,制备出全系统集成的高效存算一体学习芯片,实现速度和能效的大幅提升。

“路不好走,却意义非凡,它是当前全球高科技领域较量的重要战场。”高滨认为,芯片研究是一件久久为功的事情,前方找不到的突破口,却能在日积月累的研究学习中获得。
张文彬、姚鹏作为学术论文的第一作者,博士期间接触了大量如半导体、微电子、软件算法和类脑计算等不同方向的科研知识,积累了丰硕的研发成果和丰富的工程建设经验。
从无到有、从弱到强。在科研这条没有捷径的路上,“芯青年”们无数次制备观察后放弃,又在无数次归零后重新开始,跨越一座又一座险峰。
放眼未来,吴华强希望团队的方案、技术能够走出实验室,切切实实推动科研成果转化,致力服务国家所需、社会所需。
