本文来自微信公众号“半导体产业纵横”,作者/丰宁。
在人工智能计算架构的布局中,CPU与加速芯片协同工作的模式已成为一种典型的AI部署方案。CPU扮演基础算力的提供者角色,而加速芯片则负责提升计算性能,助力算法高效执行。常见的AI加速芯片按其技术路径,可划分为GPU、FPGA和ASIC三大类别。在这场竞争中,GPU凭借其独特的优势成为主流的AI芯片。那么,GPU是如何在众多选项中脱颖而出的呢?展望AI的未来,GPU是否仍是唯一解呢?
GPU如何制胜当下?
AI与GPU之间存在着密切的关系。
1.1强大的并行计算能力
AI大模型指的是规模庞大的深度学习模型,它们需要处理海量的数据和进行复杂的计算。GPU的核心优势就在于其强大的并行计算能力。与传统的CPU相比,GPU能够同时处理多个任务,特别适合处理大规模数据集和复杂计算任务。在深度学习等需要大量并行计算的领域,GPU展现出了无可比拟的优势。
1.2完善的生态系统
其次,为了便于开发者充分利用GPU的计算能力,各大厂商提供了丰富的软件库、框架和工具。例如,英伟达的CUDA平台就为开发者提供了丰富的工具和库,使得AI应用的开发和部署变得相对容易。这使得GPU在需要快速迭代和适应新算法的场景中更具竞争力。
1.3通用性好
GPU最初是用于图形渲染的,但随着时间的推移,它的应用领域逐渐扩大。如今,GPU不仅在图形处理中发挥着核心作用,还广泛应用于深度学习、大数据分析等领域。这种通用性使得GPU能够满足多种应用需求,而ASIC和FPGA等专用芯片则局限于特定场景。
有人将GPU比作一把通用的多功能厨具,适用于各种烹饪需求。因此在AI应用的大多数情况下,GPU都被视为最佳选择。相应的,功能多而广的同时往往伴随着特定领域不够“精细”,接下来看一下,相较其他类型的加速芯片,GPU需要面临哪些掣肘?
GPU的掣肘
常见的AI加速芯片根据其技术路径,可以划分为GPU、FPGA和ASIC三大类别。
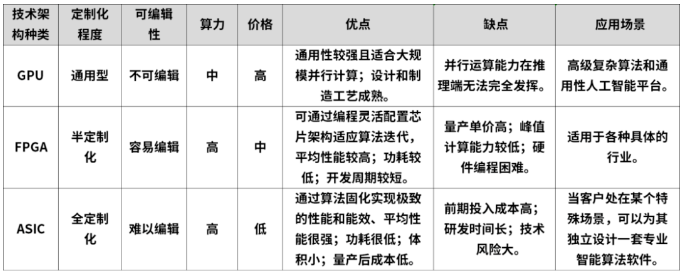
FPGA(Field Programmable Gate Array,现场可编程门阵列),是一种半定制芯片。用户可以根据自身的需求进行重复编程。FPGA的优点是既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点,对芯片硬件层可以灵活编译,功耗小于CPU、GPU;缺点是硬件编程语言较难,开发门槛较高,芯片成本、价格较高。FPGA比GPU、CPU更快是因为其具有定制化的结构。
ASIC(Application Specific Integrated Circuit特定用途集成电路)根据产品的需求进行特定设计和制造的集成电路,其定制程度相比于GPU和FPGA更高。ASIC算力水平一般高于GPU、FPGA,但初始投入大,专业性强缩减了其通用性,算法一旦改变,计算能力会大幅下降,需要重新定制。
再看GPU相较于这两类芯片存在哪些劣势。
第一点,GPU的单位成本理论性能低于FPGA、ASIC。
从成本角度看,GPU、FPGA、ASIC三种硬件从左到右,从软件到硬件,通用性逐渐降低、越专用,可定制化逐渐提高,相应的设计、开发成本逐渐提高,但是单位成本理论性能越高。举个例子,对于还在实验室阶段的经典算法或深度学习算法,使用GPU做软件方面的探索就很合适;对于已经逐渐成为标准的技术,适合使用FPGA做硬件加速部署;对于已经成为标准的计算任务,则直接推出专用芯片ASIC。
第二点,GPU的运算速度要逊色于FPGA和ASIC。
FPGA、ASIC和GPU内都有大量的计算单元,因此它们的计算能力都很强。在进行神经网络运算的时候,三者的速度会比CPU快很多。但是GPU由于架构固定,硬件原生支持的指令也就固定了,而FPGA和ASIC则是可编程的,其可编程性是关键,因为它让软件与终端应用公司能够提供与其竞争对手不同的解决方案,并且能够灵活地针对自己所用的算法修改电路。
因此在很多场景的应用中,FPGA和ASIC的运算速度要大大优于GPU。
具体到场景应用,GPU浮点运算能力很强,适合高精度的神经网络计算;FPGA并不擅长浮点运算,但是对于网络数据包、视频流可以做到很强的流水线处理;ASIC则根据成本有几乎无限的算力,取决于硬件设计者。
第三点,GPU的功耗远远大于FPGA和ASIC。
再看功耗。GPU的功耗,是出了名的高,单片可以达到250W,甚至450W(RTX4090)。而FPGA一般只有30~50W。这主要是因为内存读取。GPU的内存接口(GDDR5、HBM、HBM2)带宽极高,大约是FPGA传统DDR接口的4-5倍。但就芯片本身来说,读取DRAM所消耗的能量,是SRAM的100倍以上。GPU频繁读取DRAM的处理,产生了极高的功耗。另外,FPGA的工作主频(500MHz以下)比CPU、GPU(1~3GHz)低,也会使得自身功耗更低。
再看ASIC,ASIC的性能和功耗优化是针对特定应用进行的,因此在特定任务上性能更高、功耗更低。由于设计是针对特定功能的,ASIC在执行效率和能效比方面通常优于FPGA。
举个例子,在智能驾驶这样的领域,环境感知、物体识别等深度学习应用要求计算响应方面必须更快的同时,功耗也不能过高,否则就会对智能汽车的续航里程造成较大影响。
第四点,GPU时延高于FPGA、ASIC。FPGA相对于GPU具有更低的延迟。GPU通常需要将不同的训练样本,划分成固定大小的“Batch(批次)”,为了最大化达到并行性,需要将数个Batch都集齐,再统一进行处理。
FPGA的架构,是无批次的。每处理完成一个数据包,就能马上输出,时延更有优势。ASIC也是实现极低延迟的另一种技术。在针对特定任务进行优化后,ASIC通常能够实现比FPGA更低的延迟,因为它可以消除FPGA中可能存在的额外编程和配置开销。
既如此,为什么GPU还会成为现下AI计算的大热门呢?
在当前的市场环境下,由于各大厂商对于成本和功耗的要求尚未达到严苛的程度,加之在GPU领域的长期投入和积累,使得GPU成为了当前最适合大模型应用的硬件产品。尽管FPGA和ASIC在理论上具有潜在的优势,但它们的开发过程相对复杂,目前在实际应用中仍面临诸多挑战,难以广泛普及,因此,众多厂商纷纷选择GPU作为解决方案,这也导致高端GPU的产能吃紧问题,所以也亟需寻求替代方案。
