本文来自微信公众号“半导体行业观察”,作者/李飞。
今天,人工智能毫无疑问是全球最火热的技术,同时也成为了半导体行业最炙手可热的新市场。在人工智能技术中,目前看来影响力最大的技术将会是大模型技术,其核心特点就是通过使用规模巨大(参数可达百亿到千亿数量级)的模型,并且在海量的数据上训练,来实现人工智能能力的突破,并且赋能新的应用,其中典型的例子就是去年下半年开始获得万众关注的ChatGPT;而在未来,大模型的复杂度预计会进一步提升,以满足应用的需求。
训练和部署大模型需要强而有力的硬件支持,而这也是人工智能时代芯片成为核心技术的原因,因为大模型需要的算力归根到底来自于芯片,同时人工智能市场的发展也极大地推动了芯片行业的市场规模,以及相关芯片技术的演进。
在给人工智能大模型提供足够的算力用于训练和部署的核心芯片技术中,数据互联正在占据越来越重要的位置。芯片互联越来越重要主要出于两个原因:
首先,随着大模型的参数规模和训练数据容量快速提升,训练和部署最新的大模型一定会使用分布式计算,因为单机几乎不可能提供运行大模型的足够算力。在分布式计算中,随着分布式计算节点数量提升,理想情况下计算能力是随着计算节点数量线性提升,但是现实中由于不同计算节点间的数据交互需要额外的开销,因此只能接近而无法真正实现计算能力随着计算节点增加而线性增加。换句话说,随着模型规模越来越大,需要的分布式节点数量越来越多,对于这类分布式计算节点间的数据互联需求(带宽,延迟,成本等)也就越来越高,否则这类分布式计算中的数据互联将会成为整体计算中的效率瓶颈。
其次,从芯片层面考虑,随着摩尔定律越来越接近物理极限,目前以chiplet(芯片粒)为代表的高级封装技术正在成为芯片性能提升的重要方式。使用chiplet可以把单个复杂的大芯片系统分成多个小的芯片粒,每个芯片粒都可以用最合适的工艺去单独制造,因此确保复杂的芯片系统可以以合理的成本和良率来制造。对于人工智能大模型而言,用于训练和部署的芯片的规模都非常大,因此chiplet将会成为支持人工智能芯片的核心技术。而在chiplet方案中,多个chiplet之间的数据通信也需要数据互联技术,换句话说高带宽、高密度的数据互联将会成为使用chiplet搭建的人工智能加速芯片中的核心组件。
如上所述,在人工智能时代,数据互联将会成为核心技术,而其中最关键同时也是未来将会有最多发展的数据互联方案,就是用于分布式计算中的中长距离数据互联,以及用于chiplet场景中的超短距离数据互联。
用于分布式计算的数据互联:硅光子技术成为关键
人工智能大模型的分布式计算,包括训练和部署,通常都在数据中心中完成。我们在数据中心数据互联中看到两个重要趋势,即常规长距离通信的进一步规模化,以及新的短距离应用的崛起。
在常规的长距离数据中心数据互联领域,目前为了满足人工智能等应用的需求,互联速度正在快速提升,从今天主流的100/200/400Gbps光互联技术快速进展到800Gbps光互联技术,而到2026年更是预期会使用上1.6Tbps光数据互联。除了数据率提升之外,在人工智能时代,数据中心中每台服务器上对于数据互联的需求也在提升,因此单台服务器会需要更多的光数据互联模块。与传统的分立式光互联模块相比,基于硅光技术的光互联模块能实现更高的集成度:在硅光技术中,波导器件、光栅和调制器等核心模块都可以集成在同一块芯片上,从而可以大大降低光互联模块的成本,这对于人工智能应用来说是一个重要优势,因为训练大模型中需要大量的高带宽数据互联同时也不能提高太多成本。
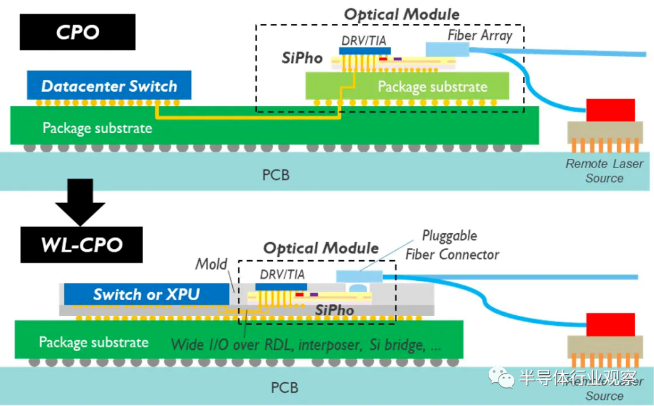
随着对于数据互联带宽的要求进一步提升,数据中心中的光互联带宽也需要进一步提升,功耗则需要进一步降低,而从这个角度,硅光子技术搭配共封装光学(co-packaged optics,CPO)也会成为下一代光互联带宽和功耗优化的核心技术。

在共封装光学技术中,使用硅光子技术实现的光互联模块和使用传统CMOS技术实现的数字逻辑(例如光互联模块后接的网络模块)将会使用高级封装技术集成在同一个封装里——而在传统的实现中,光互联模块和其他CMOS芯片并不会集成在同一个封装里。通过使用共封装光学技术,光互联模块和其他芯片之间的互联距离大大缩小,从而减小了光互联模块与电信号接口的信号传输衰减,而这对于超高带宽通信至关重要,因为在这些超高数据率的应用中,真正限制数据率的往往不是光信号,而是光信号在转换成电信号之后的信号衰减(即last-mile问题)。另一方面,通过减小信号衰减,光互联模块的整体功耗可以减小。而共封装光学是基于硅光技术之上的,因为传统的分立式光模块因为体积太大,无法使用共封装光技术和其他芯片集成到同一个封装里。
除了目前已经为人熟知的数据中心中长距离光互联模块之外,在人工智能时代将会崛起的另一个光互联技术将是计算集群中的中短距离光互联。如前所述,在大模型时代,分布式计算将会得到广泛应用,而在具体的大规模分布式计算拓扑结构中,常用的结构就是首先由物理位置相邻的服务器组成一个集群(cluster),在这样的计算集群中执行需要大量数据交换的任务,而计算集群之间再使用长距离数据互联连接在一起以提升计算规模。在这样的计算集群中,目前常规的数据互联是使用铜绞线的互联;但是随着对于数据带宽、延迟和功耗的需求越来越高,使用在计算集群中的光互联正在成为越来越重要的技术路径。
与长距离通信不同,计算集群间的数据互联需要延迟极低、功耗也较低,但是由于互联距离较小(即色散效应较小)因此可以允许更多的波分复用,因此光互联可以考虑多个波分复用信道,每个信道的数据率较小(例如16-64Gbps),这样做可以尽可能减小对于数字矫正技术的依赖(使用数字矫正技术将会提升延迟,同时也增加功耗),以满足对于功耗和延迟的需求。此外,在计算集群中,我们会预期光模块和CMOS芯片(例如GPU或者HBM)更紧密地集成在一起,因此在共封装光学CPO技术之上,我们可能会看到集成度更高的晶圆级共封装光学(WL-CPO)技术,该技术可以为光学互联模块和CMOS芯片之间提供更多互联接口,从而进一步增加通信带宽。
用于chiplet的超短距离数据互联
除了长距离光互连之外,另一个人工智能时代的重要数据互联技术是用于chiplet之间通信的超短距离数据互联。
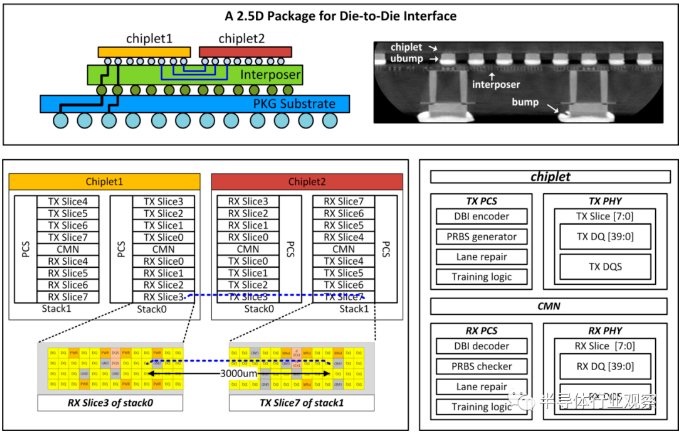
随着摩尔定律接近物理极限,使用chiplet来实现复杂芯片系统已经是业界共识。在人工智能时代,随着对算力需求的进一步提升,单芯片系统预计会用到越来越多的chiplet,同时chiplet之间的互相通信需求也会越来越大。长距离光通信数据互联的主要演进方向是共封装光学这类的新封装工艺,而与之相对地超短距离chiplet数据互联演进更多是依赖电路设计和系统设计。我们可以看到chiplet对于数据互联需求的两大方向:
1
更高的数据带宽,更长的通信距离(从毫米级别上升到厘米级别),更严格的功耗要求
2
更复杂的通信协议需求
先看第一个方向,这条需求对于chiplet数据互联的电路设计提出了越来越多的需求。随着chiplet数量越来越多,系统越来越复杂,势必chiplet之间的互连距离会越来越长,这也就意味着互联线上的衰减会更大,会需要更强的收发机;另一方面,随着人工智能对于chiplet间数据通信带宽的要求提升,每个chiplet上的数据互联模块数量也会增加,这就意味着单个数据互联模块的功耗不能过大以满足总功耗的限制。另外,随着数据互联需求的快速提升,单个数据互联模块的芯片面积又不能太大,这样才能满足chiplet上总互联接口的需求。因此,chiplet数据互联电路主要有两大指标,一个是能效比(J/bit),用来衡量数据率与功耗之间的关系;另一个指标则是数据率密度(bit/s/mm),用来衡量数据率与芯片面积之间的关系。随着chiplet数据互联需求的提升,未来我们可望会看到越来越高的数据率密度,同时越来越好的能效比。
第二个方向则是通信协议需求,这里涉及了chiplet之间协同工作的方式,例如在处理器系统中,如何确保chiplet之间缓存一致性的问题。未来随着chiplet系统越来越复杂,传输的复杂度也会提升,未来甚至可能会把目前NoC的模式搬到chiplet上。这对于chiplet数据互联IP的设计也是一个新的发展方向。
总体来说,对于chiplet的数据互联来说,随着人工智能相关需求的兴起,未来它可望会成为芯片IP领域一个越来越重要的品类,而具体的技术方向,则会沿着电路设计的优化和系统/传输协议复杂度提升的方向去演进。
