本文来自微信公众号“半导体行业观察”,来源 | theregister。
来源:内容编译自theregister,谢谢。
根据Omdia的估计,Nvidia在2024年占据了人工智能领域的主导地位,其Hopper GPU在其12大客户的出货量将增长两倍多,达到200多万台。
然而,尽管Nvidia仍然是AI基础设施巨头,但它正面临着来自竞争对手AMD的激烈竞争。在早期采用其Instinct MI300系列GPU的公司中,AMD的市场份额正在迅速扩大。
Omdia估计,微软在2024年购买了约581,000块GPU,是全球所有云或超大规模客户中购买量最大的。其中,六分之一由AMD制造。
根据Omdia的调查结果,在Meta(迄今为止对刚推出一年的加速器最热衷的采用者)中,AMD占据了GPU出货量的43%,为173,000块,而Nvidia的出货量为224,000块。与此同时,在Oracle,AMD占据了这家数据库巨头163,000块GPU出货量的23%。
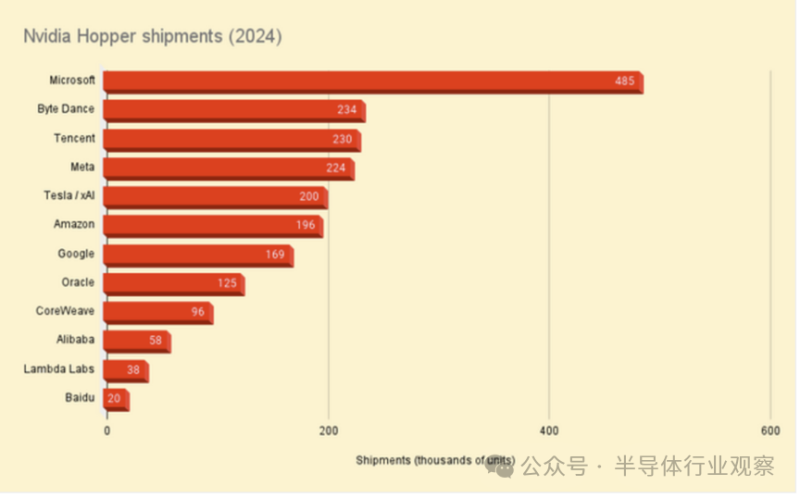
尽管在微软和Meta等主要客户中的份额不断增长,但AMD在更广泛的GPU市场中的份额与Nvidia相比仍然相对较小。
Omdia的估计追踪了四家供应商(微软、Meta、甲骨文和GPU bit barn TensorWave)的MI300X出货量,总计327,000台。
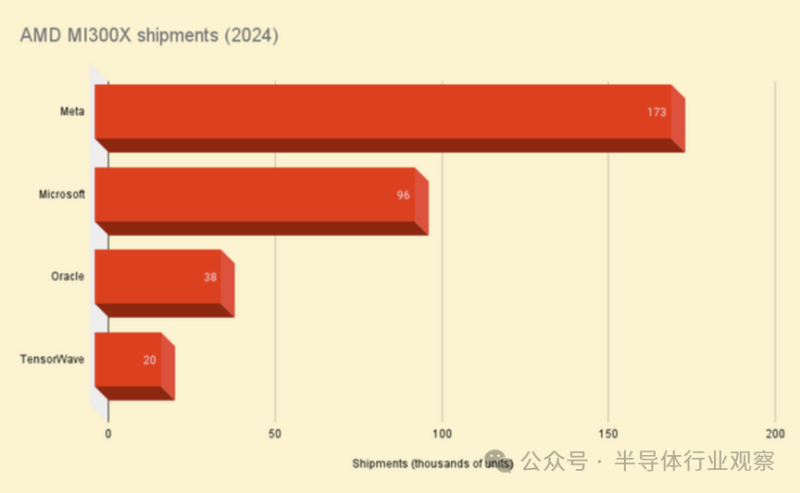
AMD的MI300系列加速器上市才一年,因此其发展速度同样引人注目。在此之前,AMD的GPU主要用于更传统的高性能计算应用,例如橡树岭国家实验室(ORNL)的1.35 exaFLOPS Frontier超级计算机。
Omdia云计算和数据中心研究总监Vladimir Galabov向The Register表示:“他们去年成功地通过HPC领域证明了GPU的有效性,我认为这很有帮助。我确实认为人们渴望找到Nvidia的替代品。”
为什么选择AMD?
这种需求在多大程度上是由Nvidia硬件供应有限所导致的很难说,但至少从纸面上看,AMD的MI300X加速器提供了许多优势。MI300X于一年前推出,声称其AI工作负载浮点性能比老牌H100高1.3倍,内存带宽高60%,容量高2.4倍。
后两点使得该部件对于推理工作负载特别有吸引力,其性能通常取决于内存的数量和速度,而不是GPU可以抛出多少FLOPS。
一般来说,当今大多数AI模型都是以16位精度进行训练的,这意味着为了运行它们,每10亿个参数需要大约2 GB的vRAM。每台GPU配备192 GB的HBM3,单台服务器拥有1.5 TB的vRAM。这意味着大型模型(如Meta的Llama 3.1 405B前沿模型)可以在单个节点上运行。另一方面,配备类似设备的H100节点缺乏以全分辨率运行模型所需的内存。141 GB的H200不受同样的限制,但容量并不是MI300X的唯一亮点。
MI300X拥有5.3 TBps的内存带宽,而H100为3.3 TBps,141 GB H200为4.8 TBps。总而言之,这意味着MI300X理论上应该能够比Nvidia的Hopper GPU更快地为更大的模型提供服务。
尽管Nvidia的Blackwell才刚刚开始面向客户推出,但在性能和内存带宽方面遥遥领先,AMD的新款MI325X仍然以每GPU 256 GB的容量优势占据优势。其功能更强大的MI355X将于明年年底发布,将容量提升至288 GB。
因此,微软和Meta都选择AMD的加速器也就不足为奇了,这两家公司都在部署数千亿甚至数万亿个参数的大型前沿模型。
Galabov指出,这一点已反映在AMD的业绩指引中,该指引每个季度都在稳步上升。截至第三季度,AMD现在预计Instinct将在2024财年带来50亿美元的收入。
进入新的一年,Galabov相信AMD有机会获得更多的市场份额。“AMD执行力强。它与客户沟通良好,善于透明地谈论自己的优势和劣势,”他说。
一个潜在的驱动因素是GPU比特库的出现,例如CoreWeave,它们每年部署数万台加速器。Galabov表示:“其中一些公司会刻意尝试围绕Nvidia替代方案建立商业模式”,他指出TensorWave就是其中一个例子。
定制硅片大步前进
不仅仅是AMD在蚕食Nvidia的帝国。在云计算和超大规模企业大量购买GPU的同时,许多企业也在部署自己的定制AI芯片。
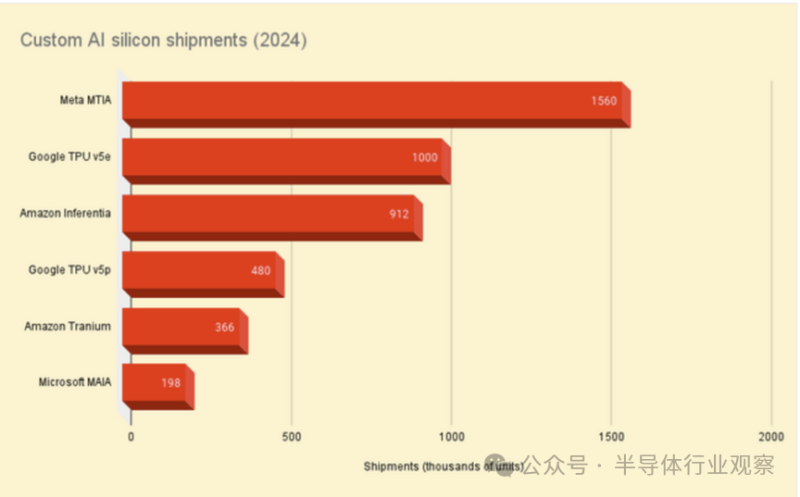
Omdia估计,Meta定制MTIA加速器的出货量(我们在今年早些时候对其进行了更详细的研究)将在2024年达到150万台,而亚马逊则订购了90万台Inferentia芯片。
这是否对Nvidia构成挑战在很大程度上取决于工作量。这是因为这些部件旨在运行更传统的机器学习任务,例如用于将广告与用户匹配、将产品与买家匹配的推荐系统。
虽然Inferentia和MTIA在设计时可能并未考虑到LLM,但谷歌的TPU肯定曾被用于训练该搜索巨头的许多语言模型,包括其专有的Gemini和开放的Gemma模型。
据Omdia所知,谷歌今年订购了约一百万个TPU v5e和48万个TPU v5p加速器。
除了Inferentia,AWS还拥有Trainium芯片,尽管名称如此,但这些芯片已针对训练和推理工作负载进行了重新调整。Omdia估计,到2024年,亚马逊将订购约366,000个此类部件。这与其Rainier项目计划相一致,该项目将在2025年为模型构建者Anthropic提供“数十万”个Trainium2加速器。
最后还有微软的MAIA部件,这些部件在AMD推出MI300X前不久首次亮相。与Trainium类似,这些部件针对推理和训练进行了调整,微软作为OpenAI的主要硬件合作伙伴和模型构建者,显然在这方面做得不错。Omdia认为微软在2024年订购了大约198,000个此类部件。
人工智能市场比硬件更大
过去两年中,英伟达的巨额营收增长理所当然地让人们关注到了人工智能背后的基础设施,但这只是一个更大谜团中的一块碎片。
Omdia预计,随着AMD、英特尔和云服务提供商推出替代硬件和服务,Nvidia将在未来一年努力扩大其在AI服务器市场的份额。
“如果我们从英特尔身上学到了什么,那就是一旦市场份额达到90%以上,就不可能继续增长。人们会立即寻找替代方案,”Galabov说道。
然而,Galabov怀疑,Nvidia不会在竞争日益激烈的市场中争夺份额,而是会专注于通过让技术更容易获得来扩大整个潜在市场。
Nvidia推理微服务(NIM)的引入只是这一转变的一个例子,NIM是一种容器化模型,其功能类似于构建复杂AI系统的拼图。
“这是史蒂夫·乔布斯的策略。智能手机的成功归功于应用商店。因为它让技术更容易使用,”Galabov谈到NIM时说道。“人工智能也是如此;建立一个应用商店,人们就会下载并使用它。”
话虽如此,Nvidia仍然扎根于硬件。云提供商、超大规模计算提供商和GPU比特库已经宣布基于Nvidia强大的新型Blackwell加速器打造大规模集群,至少在性能方面,该加速器远远领先于AMD或英特尔目前提供的任何产品。
与此同时,Nvidia加快了其产品路线图,以支持每年推出新芯片的节奏,从而保持领先地位。看来,尽管Nvidia将继续面临来自竞争对手的激烈竞争,但它短期内不会失去王冠。
参考链接
https://www.theregister.com/2024/12/23/nvidia_ai_hardware_competition/
