本文来自钛媒体(www.tmtpost.com),来源 | HiEV大蒜粒车研所,作者 | 肖恩。
在8月小鹏MONA M03的发布会上,何小鹏宣布自研的图灵芯片流片成功,这使其成为继蔚来之后第二家正式公布自研智驾芯片的主机厂。
早在去年的9月份,蔚来就对外公布了自研的智驾芯片——神玑NX9031,号称1颗更比4颗强,并在7月份的蔚来科技日上宣布流片成功。
理想内部也在推进自研芯片项目,代号「舒马赫」,虽然项目开始的时间相对晚一些,但是预计也将于年内流片。
除此之外,比亚迪、Momenta也有自研智驾芯片项目正在进行。
芯片是个高投入、长周期的行业,研发周期最少需要2-3年。除了高昂的研发成本外,后续还要投入巨额的流片费用,单次流片的成本至少需要几千万元,如果要设计一颗5nm的芯片,最终的研发成本可能高达20-30亿元。
除了高额的投入之外,还要面对技术上的风险,流片失败、良品率低、性能不达标等都是第一次踏足芯片行业的公司可能会碰到的问题。
尽管如此,国内智驾行业的头部公司却都不约而同地走上了自研芯片的道路。
这篇文章,你将看到:
- 新势力执着自研芯片的原因;
- 特斯拉、英伟达设计大算力芯片的两种不同路径;
- 为什么一代FSD算力不大,却能跑端到端大模型;
- 蔚来神玑一颗顶四颗,到底是多少算力?
- 1颗小鹏图灵芯片,相当于3颗OrinX。
01 新势力为什么执着自研智驾芯片?
最直接的原因是成本。
以市场上高阶智驾车型普遍使用的英伟达Orin X为例,刚发售时单颗售价超过500美金,即使现在也需要400美金一颗,支持城区高阶辅助驾驶的功能至少需要2颗Orin X,而像蔚来这样全系标配4颗Orin X的车型,仅仅采购芯片的成本就超过了1万元。
一颗高阶自研芯片的研发投入虽然超过20亿元,如果生命周期的用量超过100万片,那么单片的成本可以降至2000元。
按照蔚来公布的信息,一颗自研的NX9031能够替代4颗Orin X,即使一车使用2片,也能有上千元的成本节约,而随着出货量的提升,自研芯片的成本优势会进一步放大。
因此对于蔚来和小鹏这样高阶智驾芯片需求量大的车企来说,自研芯片是一笔非常划算的「生意」。
第二个重要的原因是性能。
特斯拉作为智驾行业的先驱,也经历了智驾芯片从外采到自研的过程。
在最早的Model S上使用的是Mobileye的EyeQ芯片,由于Mobileye是业内出名的「小黑盒」,特斯拉很快就转向了英伟达,而随着算法的不断进化,英伟达的芯片已经无法满足特斯拉的要求,因此自研芯片就顺理成章。
特斯拉第一代的FSD芯片于2019年量产,单颗算力达到了72 TOPs。那时英伟达的Orin X还未上市,FSD芯片的性能秒杀市面上所有的智驾芯片。
从这时候开始,特斯拉的算法加速进化,从Transformer到占用格栅网络,再到现在的端到端大模型,每一次升级都带领智驾行业向前跃进。
在算法上,国内的智驾公司一直紧跟特斯拉的步伐。
进入端到端的阶段后,各家对算法也有着自己的理解,蔚来利用生成式AI设计了NWM世界模型,理想为了解决端到端大模型可解释性差的问题,将架构升级为「端到端+VLM」,而小鹏则和特斯拉一样坚信纯视觉才是智能驾驶的终局,发布了下一代AI鹰眼纯视觉方案。
但是要最大限度的发挥算法的能力,必须要有和软件深度融合的硬件,自研芯片则是最理想的方式。
还有一个原因是出于供应链的考虑,2020年正是美国开始全面制裁华为的时候,经过几轮的制裁,华为无法生产高端芯片,手机业务受到重创。
彼时半导体市场还面临缺芯的问题,芯片的供应非常不稳定,经历过这段时间的主机厂都深有体会,为了保证生产有时会需要数倍的价格来采购芯片。
芯片是智驾的核心,从这时候开始以智驾为核心的主机厂意识到自研芯片的战略意义,纷纷开始推进自研的计划。
除了上面几个原因之外,中国芯片产业的成熟也是主机厂开始自研芯片的基础,特别是芯片设计行业,华为海思几乎以一己之力将中国高端芯片的设计能力提高到了世界领先的水平。
虽然受到美国的制裁后,海思的芯片之路遇到了很大的困难,但是却为中国的芯片设计行业输送了大量的人才,蔚来和小鹏的自研芯片项目的负责人均来自华为海思,可谓是中国芯片行业的黄埔军校。
02 强大的芯片是「设计」出来的
在对比各家自研芯片的参数之前,我们需要了解一些智驾芯片的基础知识。
芯片是半导体行业中一个非常广义的概念,CPU、MCU、GPU、PMIC等等这些都属于芯片中的一种,而我们通常所说的智驾芯片则属于SOC(system on chip),也就是系统级芯片。
它集成了CPU、GPU、NPU、ISP、和内存等多个模块,是一种集成度非常高的芯片。

图片来源:特斯拉图
以特斯拉的FSD芯片为例,内部集成了一个12核的CPU、一个GPU、两个NPU以及ISP和解码器等模块。
其中ISP和解码器负责处理输入的视频数据,而CPU、GPU和NPU则是SOC中负责计算任务的模块,但是所处理的任务类型不同。
算力
在讨论智驾芯片性能强弱的时候,我们习惯用算力单位TOPs来衡量,它的含义是每秒执行1万亿次操作。
例如英伟达的OrinX,被公认是目前市场上性能最强的智驾芯片,单颗芯片的最大算力达到了254 TOPs,而特斯拉的FSD芯片单颗算力只有72 TOPs,从这个数字上看,OrinX的算力确实很强,那么是否意味着TOPs越大的智驾芯片,性能就越好呢?
评价一个芯片性能的时候有很多算力单位,比如DMIPs、TFLOPs、TOPs。
但我们习惯用TOPs来衡量智驾芯片的性能,这是因为现在自动驾驶算法对算力消耗最大的部分是感知端的CV算法,CV算法的核心是卷积神经网络(CNN),它的本质是累积累加运算MAC(Multiply Accumulate),而TOPs可以很好地评价芯片在1s内完成MAC操作的次数。
- CPU
CPU也就是我们常说的中央处理器,能处理各种不同类型的任务和指令,它的设计遵循冯·诺依曼架构,这个架构主要由运算器、控制器、存储器、输入设备、输出设备等五个主要部分组成。
每个核心都可以独立处理指令,但是CPU采用的是串行运算方式,每个CPU核心一次只能执行一个计算指令,完成后才能进行下一个计算。
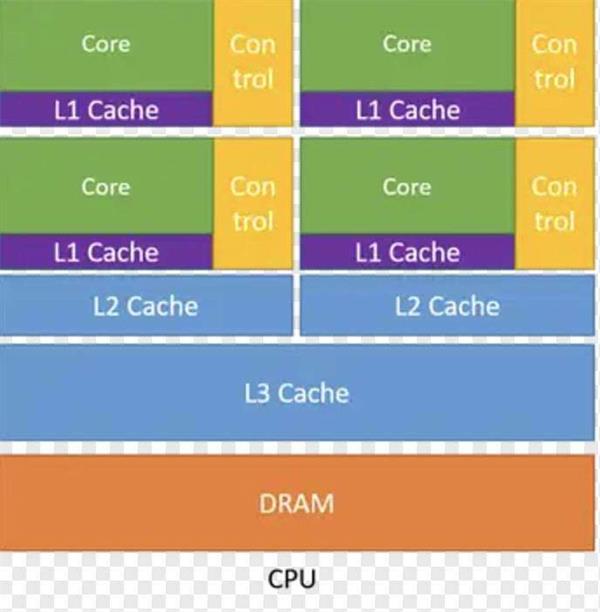
上图是一个4核CPU的典型架构,每个核心都可以独立处理指令,但是CPU采用的是串行运算方式,每个CPU核心一次只能执行一个计算指令,完成后才能进行下一个计算。
它的特点是通用性和逻辑控制力好,能够处理各种复杂的计算需求,但是缺点也很明显,不擅长处理计算量大的并行计算。
在CPU上我们经常会听到X86和ARM的概念,他们分别对应了两种CPU架构,X86采用的是CISC复杂指令集,性能强大但是功耗较高,而ARM采用的RISV精简指令集,追求的是性能和功耗的平衡。
因此,移动端和车端的CPU一般都是采用ARM架构。
最后聊一下CPU的算力单位DMIPs(Dhrystone Million Instructions Per Second)。
由于不同的指令集和架构对CPU的性能都有影响,因此不能简单的用CPU的主频来评价,Dhrystone是一个基准测试程序,通过测量CPU每秒能运行多少次Dhrystone程序来评价不同CPU的性能,例如100DMIPs代表每秒能运行1亿次Dhrystone程序。
自动驾驶中的传感器融合、路径规划和决策等算法都需要强大的CPU性能支持。
- GPU
CPU能处理复杂的计算任务但是不擅长并行计算,为了解决这个问题,GPU出现了,最开始是为了处理图形任务而设计的,它拥有成百上千个计算单元,每个单元能独立执行指令,能够并行处理大量的计算任务。
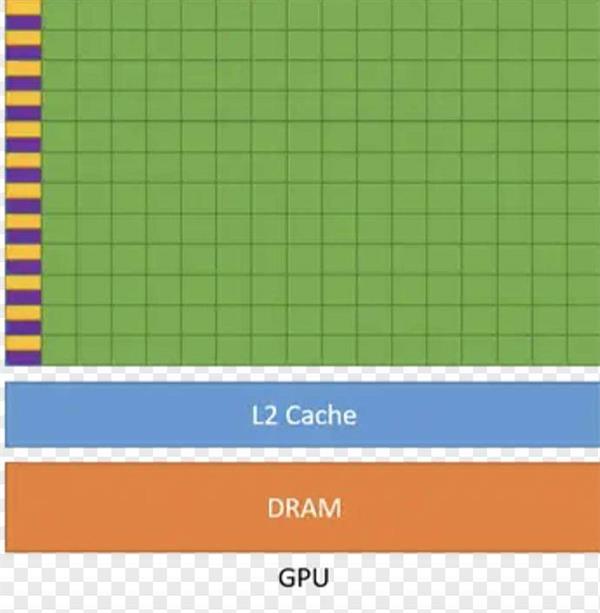
上图是一个GPU的典型架构,和CPU相比它的逻辑控制单元和缓存都比较简单,大部分空间都留给了计算单元。
因此GPU适合处理大量并行计算任务,但是不能处理复杂的指令,更适合处理逻辑简单、类型统一的任务,例如图形处理和渲染。
由于图形处理和渲染大需要大量的浮点运算,因此GPU的算力一般用TFLOPs来衡量。英伟达最新一代的显卡RTX 4090的算力大约为48 TFLOPs,作为对比OrinX的算力是5.2 TFLOPs。
和图形处理类似,神经网络的训练也需要大量的并行计算,因此GPU的架构也非常适合用于深度学习的计算。
OrinX的架构就是以GPU为核心,可以实现int8精度下最大254TOPs的算力。
- NPU
既然GPU可以很好地处理AI算法中的矩阵和卷积运算,为什么还需要NPU呢?
GPU虽然性能强大,但是也有功耗高、成本昂贵等问题,而NPU是专为深度学习和AI算法设计的专用处理器,在运行神经网络算法时,NPU比GPU计算速度更快,功耗更低。
但是NPU的缺点也很明显,它的通用性较差,能处理的计算任务类型有限,在软件生态上也相对封闭。
而GPU已经发展了很多年,有更为完善的软件生态,特别是英伟达的CUDA架构,有非常丰富的应用和第三方的工具支持,开发人员可以非常方便地使用C/C++语言在这个架构上编写程序,运行在英伟达支持CUDA的芯片上。
一个有趣的现象是,英伟达作为AI时代的领军者,在SOC中并没有使用NPU的架构,而是使用GPU作为AI计算的核心,但是苹果和高通的SOC设计中都加入了单独的NPU模块。

因为英伟达的GPU在性能上足够强大,不需要单独增加NPU模块来。
但是对于其他厂商来说,无法使用英伟达这样性能强大的GPU内核,因此单独设计一个NPU模块来处理AI算法则是更好的选择。
- ISP
ISP(Image Signal Processor),即图像信号处理器,主要作用是对前端图像传感器输出的信号做后期处理,主要功能有线性纠正、噪声去除、坏点去除、内插、白平衡、自动曝光控制等。
ISP分为外置和内置两种,现在大部分自动驾驶芯片都将ISP集成到了SOC内部,摄像头的原始图像经过ISP处理后,输入给感知算法。
一般会用像素处理能力来评价一个ISP的性能。
例如OrinX内置的ISP模块处理像素的速度是1.85 Gpixel/s,pixel/s越高代表能处理的摄像头像素越高,在不考虑图像压缩的情况下,3.2 Gpixel/s可以处理大约一亿像素。
另一个非常重要但是容易被忽略的参数是位宽,它代表了每个像素包含的数据量,位宽越大单个像素里包含的数据量越大,可以表示的颜色也越多。
例如位宽为8bit时,一个像素可以表示256种颜色,而24bit时则可以表示1600万种颜色。
- 内存带宽
最后聊一下内存带宽,这是我们在讨论智能驾驶芯片性能时经常忽略的一个参数。
神经网络算法的本质是矩阵的乘积累加运算,这个过程中需要频繁的读取数据,使用的算法模型参数越多,在内存中需要保存的数据量越大。
不论是智能驾驶还是人工智能,都在走向大模型的技术路线,对于存储带宽的要求也会越来越高。
自动驾驶领域非常火热的Transformer模型,它的参数量在10亿左右,而GPT-4的参数规模则超过1.5万亿。
我们在手机领域常见的内存方案是LPDDR,这是一种用于移动端的低功耗内存技术,目前主流的自动驾驶芯片也是使用这个技术,最新的标准是LPDDR5X,最高带宽8533MT/s,这里的MT/s指的是每秒传输一百万次,实际能传输的数据量还取决于位宽。
除了LPDDR之外,还有两种带宽更高的技术:GDDR和HBM。
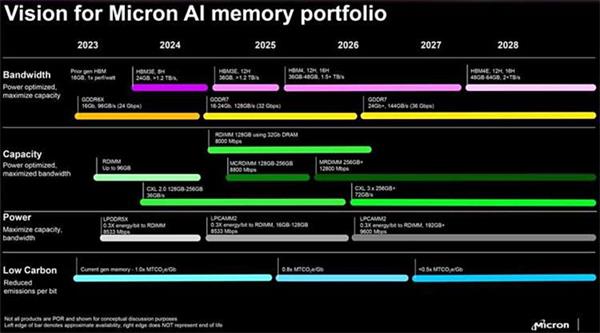
HBM是一种使用了3D堆叠架构和硅通孔技术的动态随机存储技术,主要用于高性能计算和AI领域,目前已发展到HBM3。
采用这个技术的英伟达H100 NVL显卡,最大带宽能达到7800GB/s。
但是HBM的缺点就是太贵,汽车领域无法承受这么高的成本。
GDDR可以算是廉价版的HBM,主要用于显卡领域,目前发展到GDDR6x,例如英伟达最新的RTX4090显卡采用的就是GDDR6x,最大带宽能达到1008GB/s。
GDDR的成本虽然远低于HBM,但是也要达到LPDDR的3倍以上。
在汽车行业有一家OEM就把GDDR技术用在了自动驾驶的芯片上,特斯拉最新的FSD二代芯片支持GDDR6,为了支持大模型特斯拉也是下了血本。
03 英伟达、特斯拉,大算力芯片的设计
在智能驾驶技术爆发之前,市场上的智驾芯片都是小算力,最高支持到L2的ADAS功能,最经典的芯片是Mobileye的EyeQ系列。
从英伟达进入自动驾驶领域开始,智驾芯片进入大算力时代。
英伟达的OrinX和特斯拉的FSD芯片分别代表了大算力智驾芯片的两种设计思路:
一个是在硬件上堆料来打破算力的天花板,大力出奇迹;
另一个是算法和硬件深度融合,最大效率的利用芯片的性能。
- OrinX
虽然英伟达已经发布了最大算力超过1000 TOPs的Thor,但是距离量产还有一段时间。
目前已量产的智驾芯片中,纸面算力最大的还是OrinX,先来看一下它的架构。
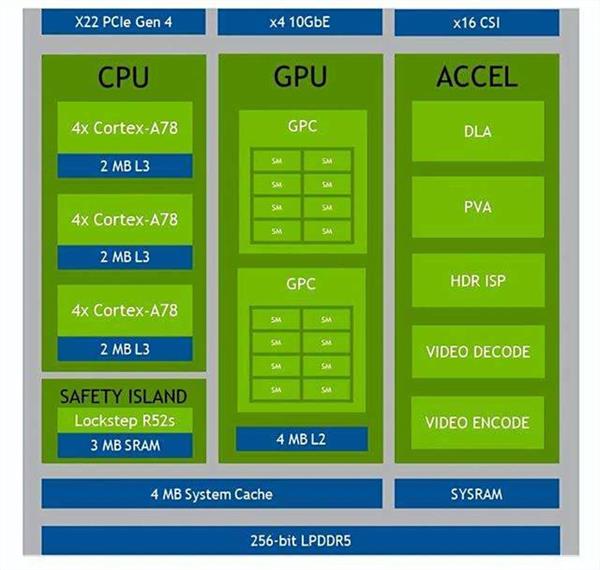
CPU部分采用了12核的ARM Cortex-A78AE,这是ARM专为车载和移动端设计的架构,算力为240 KDMIPS,同时基于Cortex-R52s提供了功能安全岛。
GPU部分使用的英伟达的Ampere架构,由2个图形处理集群(GPC,Graphic Processing Cluster)组成,每个GPC有8个流处理器(SM,Streaming Multiprocessors),每个SM拥有128个CUDA核心和4个Tensor核心,OrinX总计拥有2048个CUDA核心和64个Tensor核心,在FP32精度下的GPU算力为5.2 TFLOPs。
OrinX没有专门的NPU,但是提供了两个加速器PVA和DLA,PVA是计算机视觉算法的加速器,DLA则是专门针对深度神经网络中卷积计算的加速器。通过GPU和DLA,OrinX在int8精度下最大可以提供254 TOPs的算力。
ISP最大的像素处理能力是1.85 Gpixel/s,位宽没有明确的数据,可能是16 bit。
内存部分采用的是256 bit的LPDDR5,最高带宽6400 MT/s,对应的内存带宽是204.8 GB/s。
从架构上看,OrinX的CPU性能中规中矩,但是GPU性能强大,依靠英伟达强大的技术实力,不需要额外的NPU模块,直接通过CUDA和Tensor核来满足AI算法的需求,加上英伟达成熟的工具链和生态,不愧为市场上占有率最高的大算力智驾芯片。
- FSD芯片
特斯拉最新的HW4.0已经搭载了FSD二代芯片,但是没有公开具体的参数。
这里还是以第一代FSD芯片为例,来看看特斯拉自研芯片的思路,先上架构图。

CPU用的是ARM Coretex-A72,一共有12个核心,A72单核心的CPU算力为5.5 DMIPs/MHz,主频是2.2 GHz,12个核心的总算力大约为146 KDMIPs。
GPU部分使用的是ARM Mali-G71,算力只有600 GFLOPs,但GPU不是FSD芯片主要的计算核心,影响不大。
FSD芯片最核心的部分是NPU,每个芯片上有两个NPU,专为神经网络计算中的MAC设计,每个NPU在int8精度下的最大算力为36 TOPs,单颗FSD芯片的最大算力为72 TOPs。
从数字上看并不是很大,与OrinX单颗254 TOPs看起来有差距,但是OrinX的这个数字是稀疏算力,而且是把CUDA和Tensor核心加在一起的综合算力,实际上参与MAC计算的主要是Tensor核心,它的稠密算力只有54 TOPs。
这也是为什么第一代FSD芯片虽然算力数字不大,但是Transformer和端到端大模型依然能够跑起来的原因。
从FSD芯片的设计可以看到自研的好处,专为神经网络算法而设计的NPU模块,能够最大限度的发挥芯片的性能,能效比拉满。
- 地平线J6P
最后来看看国内的后起之秀——地平线。
作为中国智驾芯片的一哥,地平线进步的速度也非常快。最新的征程6系列芯片包含了从低阶到高阶的多款产品,其中的旗舰产品J6P的算力更是达到了560 TOPs。
虽然地平线没有公布详细的架构,但是从一些数据可以看出这颗芯片拥有非常强大的性能。
CPU采用的是18核心的ARM Cortex-A78E,算力超过400DMIPs,接近OrinX的两倍。GPU算力不高,只有200GFLOPs;同时内置功能安全岛,大概率使用的是ARM Cortex-R52内核,实现ASIL-D等级。
NPU部分使用的是地平线自研的BPU架构,目前已经发展到了第三代,地平线命名为纳什。
这一代BPU最大的特点是针对Transformer、BEV等算法做了针对性的优化,同时在架构上使用了三级存储架构,可以降低大规模参数下带宽的瓶颈问题,加上浮点向量加速单元和数据变换引擎等技术,J6P在int8精度下的最大算力达到了560 TOPs。
存储方面使用了LPDDR5,最高带宽205GB/s,和OrinX保持一致。
J6P的晶体管数量达到了370亿,相比之下英伟达OrinX是170亿,而FSD芯片只有60亿。
强大的CPU和NPU算力,加上对神经网络算法的特殊优化,J6一发布就获得了极大的关注,国内主流的OEM都官宣将基于J6开发新一代自动驾驶域控,J6的最终表现让人期待。
04 谁是自研最强芯片?
在去年的NIO DAY上,蔚来就率先公布了自研芯片神玑NX9031,并于今年7月份流片成功,随后小鹏也在8月份宣布自研芯片图灵流片成功,两家都走的是大算力路线。
下面就从已知的参数上,来看看谁才是自研的最强芯片。
- 蔚来神玑NX9031
发布会上斌哥称这是全球第一颗5nm的智驾芯片,可见蔚来是下了血本。
现在有能力代工5nm芯片的只有台积电和三星,而且资源紧张,代工费不菲。晶体管数量超过500亿,是OrinX的两倍以上,加上5nm的先进制程,芯片的性能表现令人期待。
CPU部分采用的大小核设计,总共是32个核心,这里面包含三种核心,大核是ARM Cortex-A78AE,小核是A65AE,内部集成了功能安全岛,使用的是R52。总的CPU算力达到了615K DMIPs。
GPU没有公开数据,发布会上也没有做介绍,有可能是没有单独的GPU模块,把图形渲染的部分都交给座舱来完成。
内存使用的是LPDDR5x,这是2021年最新的DDR标准,最高带宽8533Mbps,位宽按照256bit来计算的话,带宽可以达到273GB/s。
NPU没有公布具体的架构,预计有2个核心。
蔚来特别强调了对算法的优化,Transformer类算法性能有6.5倍的提升,Lidar类算法性能有4倍的提升,BEV算法性能4.3倍提升,但是蔚来没有提是和哪个芯片相比,大概率是以当前OrinX的平台性能为参考。
蔚来没有公布具体的算力,但是发布会上斌哥说一颗神玑的性能相当于四颗OrinX,有些人就认为算力能超过1000 TOPs,这个显然是错误的。两个芯片并联的算力并不能直接相加,因为会受到带宽的限制。
Orin模组之间是通过以太网连接,4个OrinX并联最多也就能增加20%的算力,所以当前蔚来平台的最大算力在300 TOPs左右。如果按照这个数字来看,斌哥所说的一颗顶四颗就可以理解了,估计神玑的实际算力在500 TOPs左右。
发布会上斌哥特别强调了ISP的性能,位宽26bit,像素处理能力达到了6.5Gpixel/s,前面介绍ISP参数的时候提到过,位宽24bit代表一个像素可以表示1600万种颜色,26bit则是6700万种颜色。
作为对比OrinX则是16bit左右,而像素处理能力OrinX也只有1.85Gpixel/s,可以说神玑的ISP性能是非常强大,从发布会演示的视频来看,在画面细节和暗光表现上都有巨大的提升。
但是有个小问题是发布会上展示的图像是给人眼观看的,并不是实际输入给算法的色彩格式,神玑这颗强大的ISP对算法的实际提升还需要时间验证。
从这些性能参数可以看出蔚来自研芯片的思路,不惜成本采用了5nm的工艺,换来的是断层领先的CPU和ISP性能,加上专为算法设计的NPU架构,最终可以实现1颗顶4颗OrinX的表现。
可以说在Thor正式上车之前,神玑NX9031就是当下最强的智驾芯片,第一次设计芯片就能达到这样的水平,让人叹服。
- 小鹏图灵
蔚来宣布自研芯片流片成功的一个月后,小鹏也正式公布了自己的自研芯片——图灵,一颗专为AI大模型定制的芯片,能用于智能驾驶、飞行汽车和智能机器人等多个领域。
小鹏没有公布非常详细的参数,我们可以从已知的几个数据上大概推测出它的性能表现。

小鹏公布了总的核心数是40个,这其中包含了CPU和功能安全岛,考虑到这颗芯片还要用于其它场景,需要考虑芯片的通用性,因此大概率是包含了GPU模块的。
CPU大核预计采用的是ARM Cortex-A78AE,核心数量在24个左右,会有2-4个Cortex-R52作为功能安全岛,整体CPU算力会在500 kDMIPs左右。
GPU部分可能使用的是ARM MALI-G78AE,核心数量在12个左右,预计GPU算力在1000 GFLOPs左右。
NPU部分有2个核心。
小鹏在发布会上介绍图灵芯片在本地最高可运行300亿个参数的大模型,结合小鹏未来的智驾路线,可以看出这颗芯片的NPU是专为端到端大模型而设计的。
虽然没有公布具体的算力,但是何小鹏在发布会上也提到1颗图灵芯片相当于3颗OrinX芯片的算力,预计它的算力也能达到400 TOPs左右。
ISP部分比较特别,有2个独立的ISP核心,一个负责AI算法的图像处理,另一个负责图像的合成,可能是考虑到其它应用场景里不一定有汽车座舱芯片那样强大的ISP模块,所以单独增加一个图像处理的ISP核心,可以大大的提高芯片的通用性。
小鹏没有公布具体的制程,但是提到了这颗芯片性价比非常高,因此大概率还是采用7nm的制程。
从这些参数上可以看出小鹏在自研芯片的设计路线上与蔚来有很大的不同。
首先是性能和价格的取舍,小鹏没有追求高制程,而是采用性价比较高的7nm,而蔚来为了追求性能,不惜成本也要采用5nm制程;
其次是为大模型而定制的NPU模块,从这里也能看出蔚来和小鹏在智驾路线上的不同。
蔚来的智驾路线里激光雷达还是重要的部分,因此神玑芯片对Lidar的算法做了特殊的优化,而小鹏则是走纯视觉路线,押注端到端大模型。
最后一点是非常高的通用性,图灵芯片集成了GPU模块和2个ISP核心,能应用于多个类型的产品,是小鹏AI版图中非常重要的一部分。
而蔚来的神玑芯片则专为智驾而设计,舍弃了GPU模块,把芯片上的空间留给了其它模块。
从理论性能上来说蔚来的神玑无疑是当下自研的最强芯片,但是自研芯片是为算法而定制的,性能强大并不代表全部,最终还是要看系统的实际表现。
明年Q1上市的蔚来ET9将会搭载2颗神玑NX9031,小鹏的图灵芯片也将于明年上车,地平线与J6P深度软硬结合的智驾方案SuperDrive预计明年Q3量产。
还有传闻中的理想、比亚迪、Momenta,自研芯片和软硬一体将是智驾行业的下一个趋势,明年各个头部大厂在智驾上的表现让人期待。
