本文来自微信公众号“twt企业IT社区”,作者/李登昊,某金融单位人工智能工程师,长期从事金融领域人工智能服务落地应用工作,曾负责建设云端自然语言处理模型服务系统,服务用户超三十万人;参与研发大模型智能产品,对大模型推理服务性能优化及RAG、Agent等技术有深入研究。
一、引言
随着大语言模型的快速发展,不同场景对大语言模型的需求差异日益显现。特别是对手机、PC以及汽车等终端智能系统来说,出于对轻量敏捷、安全稳定和成本等方面的考虑,传统的云端大语言模型服务并不能完全满足需求。因此,端侧大模型在这些领域的热度日益提升,逐渐成为新的行业趋势。本文旨在通过介绍端侧大语言模型的发展现状、关键技术和应用场景,帮助读者了解端侧大语言模型的技术路线和发展趋势。
二、端侧大语言模型概述
2.1大语言模型概述
大语言模型(Large Language Model,LLM)是一种人工智能模型,旨在理解和生成自然语言。基于深度神经网络的自然语言模型架构演进经历了早期的循环神经网络(Recurrent Neural Networks,RNN)和长短期记忆(Long Short Term Memory,LSTM)时代,在Transformer架构出现后,其迅速成为语言模型的主流架构。在基于Transformer的架构中,早期以Google BERT为代表的Encoder-only架构在各项下游任务上表现优于Encoder-Decoder架构和Decoder-only架构。而随着算力的不断发展,模型规模不断提升,自然语言生成能力也迎来涌现时刻,以OpenAI GPT系列模型为代表的Decoder-only架构在近两年成为大语言模型主流技术架构。与传统的语言模型相比,大语言模型的特点是规模庞大,包含数十亿乃至上千亿参数,在TB级别的大量文本数据上进行训练,这使得它们掌握了自然语言中的复杂模式,产生涌现能力,可以执行包括文本总结、翻译、分类等广泛的任务。
在大语言模型发展的早期,其应用普遍以调用云端部署的模型服务接口形式开展。而随着其在各类自然语言处理任务中应用范围的扩展,面向云端服务接口仅仅通过设计提示词(Prompt)对接口进行包装的模式逐渐无法满足企业级应用对场景复杂度和响应时效性不断增长的要求。因而端侧大模型的受重视程度逐渐提升,AIPC、AI手机和AI车机等软硬件结合的端侧大模型落地应用案例如雨后春笋般发布,又进一步推动端侧软硬件技术的快速发展,形成新时代的适用于大模型的摩尔定律。
2.2软硬件技术现状
由于大语言模型庞大的体量,适用于传统深度学习的通用软硬件技术在性能方面遭遇了前所未有的挑战。因而多种软硬件技术被提出,以优化大语言模型的训练、微调和推理阶段的速度和资源消耗,降低其研究和应用的门槛。
由于训练所需要的巨量算力资源,仅有少数企业和机构会选择从头训练大模型,因而相关技术开源程度和通用程度低。主流大模型训练,算力硬件通常为Nvidia A100或更先进的H100和B100 GPU;而Nvidia Megatron和Microsoft Deepspeed为大模型训练提供了集成先进优化技术的软件支持。在国内,华为昇腾910 NPU同样支持大规模算力集群的构建和调度,被广泛用于大语言模型的训练;而国内GPGPU方向的领头羊海光与多数企业的ASIC技术路线不同,推出的深算二号DCU采用“类CUDA”通用并行计算架构,能够较好地适配和适应国际主流商业计算软件和人工智能软件,产品性能达到国内领先。
相比之下,利用LoRA等参数高效算法,基于开源大模型底座进行微调所需算力接近于传统深度学习任务,因而得以在更多企业和机构中开展。主流的深度学习框架如Meta Pytorch、Google TensorFlow和国内的华为昇思、百度飞桨、阿里MNN等都为大模型的微调技术提供了开箱即用的支持。
但对于端侧而言,软硬件技术的核心目标在于为用户提供大语言模型推理服务,训练和微调并非端侧需要考虑的任务。在推理方面,Intel在进一步提升CPU产品对大模型的支持的同时,推出NPU(Neural Processing Unit)与原有CPU和集成GPU有机结合来应对AIPC时代的到来,Nvidia在牢牢把控云端算力先进地位的同时,也推出了在消费级GPU上的大模型应用。而在AI手机、AI车机方面,高通、联发科等头部公司也与手机、汽车厂商联合发布原生支持大模型能力的新产品。国内以华为为代表的端侧技术提供商也紧跟国际先进企业步伐,在新一代产品中为用户带来大模型能力。
面向开发者,Intel BigDL和OpenVINO提供了在AIPC上运行大模型的完整框架;MLC(Machine Learning Compilation)、阿里MNN等端侧跨平台深度学习框架也都推出了对大模型从训练、微调的算力环境转移到端侧部署环境的全套支持。
三、端侧大语言模型关键技术
3.1量化压缩技术
与微调阶段的参数高效技术相比,在推理阶段大模型的参数规模几乎是一个无法逾越的阻碍,尽管学术界提出了各类剪枝、蒸馏等方法来降低推理阶段的资源消耗,但其局限性往往较强,通用性不足,因而主流的技术路线仍是通过量化来尽可能减少单个参数的空间资源消耗。
对于大模型的量化压缩结果评价,除了直接将压缩后的模型在下游任务上进行测试,与压缩前测试结果指标进行对比之外,一个重要的评价指标是困惑度(perplexity,PPL)。这一指标在传统的自然语言处理任务中就被用于评价文本生成质量,指标越低往往代表模型性能越好。其计算过程不依赖于外部标签,测算方便,因而得到了广泛应用。困惑度的值等于交叉熵损失以2为底的指数,在样本量为T,词表为V的语料中,模型的交叉熵损失J的计算公式为[1]:
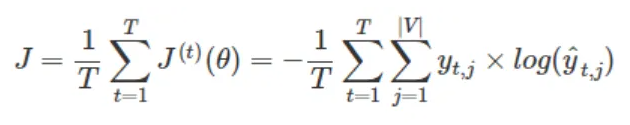
图1模型的交叉熵损失J的计算公式
由于交叉熵损失是模型训练和微调过程中需要计算的损失函数,各个深度学习框架对其都有完备的支持,因而在评价量化压缩结果时也常直接使用交叉熵损失值,即困惑度的对数作为量化指标。
在大模型的量化压缩技术中,一组需要区分的基本概念是权重(通常用W表示)和激活(即模型中神经网络层的输入和输出,通常用A表示)。研究结果指出,相比之下,W的分布范围较为接近标准正态分布,可以压缩的空间较大;而A的分布范围波动大,加大其压缩力度将显著影响模型效果。因而最基础的量化压缩技术一般基于标准的32位或16位浮点数模型,将W量化为8位乃至4位整数,但A采用16位浮点数参与计算。为了进一步压缩A的资源消耗,学术界提出了多种算法。其中一种被广泛应用的经典算法SmoothQuant[2]通过探查A和W的极值分布情况,计算平滑因子,将A的数值波动转移到W,这样尽管W的量化难度会提升,但在一定范围内,A量化质量的提升对模型效果的贡献会超过W量化质量的下降带来的负面影响,使得模型整体量化压缩效果提升。

图2 SmoothQuant原理示意图
SmoothQuant原理示意图[2]。图中X代表中间结果,对应于文中的A,通过将X的数值波动由W分担,使得二者分布均处在较为容易量化的合理区间内。
SmoothQuant不对量化本身的编码作要求,因而计算速度快,通用性高,但其性能上限也较低。为了进一步优化量化压缩质量,一系列对量化编码进行优化的算法被提出。OmniQuant[3]是一种在端侧大模型中得到广泛应用的量化压缩算法,其中通过可学习的权重裁剪(Learnable Weight Clipping,LWC)在量化过程中自适应地学习编码规则,取得了优于SmoothQuant的效果[4]。另一方面,针对传统的对称均匀编码,一系列非对称、非均匀的编码模式也被运用与大模型,以达到在同样比特数下尽可能少的压缩信息损失。例如在QLoRA[5]中提出的NF4(Normal Float 4-bit)编码针对参数分布的特点,按照正态分布概率密度函数设计量化区间边界值,将浮点数量化为以4比特记录的对应区间的序号[6]。
除了认识到应该对A和W采用不同量化压缩策略之外,对不同参数采用不同量化压缩策略的思想也被进一步拓展。在被广泛应用的端侧大模型量化压缩项目llama.cpp[7]中,提供了通过计算参数重要性矩阵为不同重要性的参数赋予不同量化精度的I-Quant和对参数分组分别实施不同量化策略的K-Quant两类量化压缩模式[8]。这些量化压缩算法形成了事实上的行业标准,被广泛应用于各类端侧场景当中,其中模型压缩率与交叉熵损失增量近似呈线性关系,在同等压缩率下,I-Quant是目前性能损失最小的压缩算法。

图3模型性能损失与压缩率的关系
图为模型性能损失与压缩率的关系[8]。图中横坐标为bpw(bit per weight),表示存储单个参数平均需要的比特数,纵坐标为量化后PPL与量化前(以16位浮点数进行运算)PPL比值减去1后的百分数取对数坐标,其数值变化规律上等价于交叉熵损失增量。
3.2数据重排技术
大模型推理过程中,除了巨量的计算任务之外,数据在内存中的流动同样带来了不可忽视的时间消耗。然而在模型微调和训练过程中,这方面因素往往不是影响性能的关键,因而相关技术框架较少关注,需要在模型部署阶段额外开展数据重排工作尽可能减少内存访问寻址。这一类技术在基于CUDA生态的GPU上得到了广泛的研究,例如在TC-FPx(Tensor Cores Floating Point x)内核方案中[9],通过比特级别的预重排,确保对于不同量化精度的大模型参数都可以消除冗余的内存访问。而在推理服务框架qserve中[10],数据重排技术同样被用于消除GPU的内存墙。
阿里MNN框架在端侧部署时,引入按照设备支持的最优SIMD(Single instruction,multiple data)计算指令对数据进行特定的重排以提升内存局部性,减少访存开销,提升访存效率的方案[10]。通过将数据重排到设备指令集支持的并行方案所需要的位置,在与量化压缩技术结合时,将多个低比特数值合并视为单个高比特数值,可以一次性执行4或8个数值操作,这使得MNN框架下大模型的推理速度大大优于其他框架[12]。
模型参数的重排是数据重排的另一个维度。推理阶段大模型以端到端的形式工作,在训练和微调阶段中便于研发人员观察的内部细节可以不再对外暴露,可以进行计算图的重排和对不同算子的融合。常见的优化策略是将激活函数作为前序算子的一部分融合进行,从而无需等待前一个算子的结果写入内存即可计算激活函数。主流端侧部署框架均针对不同的硬件平台对这一能力进行了支持。
四、端侧大语言模型应用场景
大模型在企业级应用场景中的应用非常广泛,现阶段社会各行各业中实现落地应用案例的领域包括:
1.医疗行业:端侧大模型在医疗领域的应用包括医学资料检索增强、智能知识库和知识助手等,智能问答服务,基于大模型和知识图谱能力,可以快速提升医学内容生产的自动化。
2.供应链管理:在供应链领域,端侧大模型可以创建虚拟数字员工专家团队,协助白领员工完成数字化工作,提高供应链服务的质量和效率。
3.人才服务:端侧大模型可以用于猎头管理与决策洞察,通过智能一站式指标分析平台简化数据分析和管理流程,提升猎头服务的质量和效率。
4.工业领域:在工业领域,端侧大模型可以用于设备运检知识助手,帮助企业实现从营销到履约到财务结算的端到端全局自动化。
5.办公自动化:端侧大模型可以与办公硬件和软件产品结合,提供AI摘要、AI待办、语篇规整、一键成稿等功能,提升工作效率。
6.智能制造:在制造领域,端侧大模型可以用于汽车在线问答平台,针对非结构化文档实现自然语言与知识间的交互,提升员工工作效率及学习能力。
7.保险行业:端侧大模型可以用于保险个人助理,通过多渠道触达客户,提供保险服务,提高销售人效和降低成本。
8.金融风控:端侧大模型可以用于构建金融风控场景的垂直领域模型,实现对贷前审核的材料审查工作,提升审核效率。
与云端部署的大模型服务相比,端侧大模型具有隐私安全性高,不受网络环境限制的优势。在一些隐私高度敏感或工作环境网络条件不佳的行业当中,端侧大模型为企业提供了突破大模型落地应用的障碍的有效解决方案。这些企业级应用正在帮助企业提升效率、降低成本,并通过赋能现有的PC、手机乃至工业机器人等端侧设备,推动数字化转型和智能化升级。随着技术的不断发展,端侧大模型在企业级应用场景中的潜力将进一步被挖掘和实现。
参考资料:
[1]https://www.hankcs.com/nlp/cs224n-rnn-and-language-models.html
[2]https://github.com/mit-han-lab/smoothquant
[3]https://github.com/OpenGVLab/OmniQuant

