
你感受到了吗?近些年,随着人工智能的蓬勃发展,越来越多的人工智能助理进入到了我们的日常生活中,如Cortana、Siri……
智能助理(Virtual Personal Assistant)是指以人工智能技术驱动,以自然语言对话作为主要交互方式,能够帮助个人完成任务的对话机器人(chatbot),属于对话即平台(Conversation as a Platform,CaaP)的重要应用之一。
人工智能助理还不够聪明
当前市场上形形色色的智能助理通常只能提供简单的信息查询的服务(如天气,新闻,股市等),而真正能够帮人们完成某项特定任务的智能助理可以说是凤毛麟角。不仅如此,用户在和智能助理交互过程中总会碰到诸多问题,导致用户体验不佳,用户普遍认为多数智能助理其实不(是)智(智)能(障)。
很多人将智能助理的局限性归咎于其核心技术——自然语言理解的不成熟,并期待着有一天深度学习或者其他机器学习技术能在自然语言理解领域迎来新的突破,最终使机器拥有能够和人类媲美的自然语言理解能力。到那时,“不智障”的智能助理才有可能出现。
的确,自然语言理解是智能助理的关键技术之一。但以目前的技术水平就不可能打造“不智障”的智能助理了吗?

微软亚洲研究院开发了一个名为EDI (Enterprise Deep Intelligence)的神奇小机器人,可以帮助用户自动预定会议室,或设置工作提醒等。通常,员工需要耗费5分钟左右的时间来安排一个会议,而EDI从收到用户的自然语言请求到完成会议预定只需要不到10秒的时间。用过EDI的同事都夸他聪明,因而越来越多的微软同事们选择EDI作为自己的日常工作小助手。如今,在微软亚洲研究院内部,超过一半的会议都是通过EDI自动预定的。可以说,EDI是一个真正聪明起来的人工智能助理。
今天,笔者以EDI开发过程中的经验和大家分享一下如何打造人工智能助理,提高其自然语言理解能力,以及人工智能助理还需要做好的几件事。我们认为这些事对于一个智能助理的成功来说——可以说是人工智能助理的四大“自救法宝”!
自救方法一:专注垂直应用
现阶段,要打造一个无所不能的“超级”智能助理有很大难度,但在一个垂直领域做到智能还是有可能的。
“超级” 智能助理的一个难点是开放域的自然语言理解。想将每一个领域都做到很大,并且合成一个“大而全”的智能助理——这个目标以目前的技术水平来说还是极富挑战的,因为我们无法对用户的请求进行任何先验假设。各个领域之间会有一定的冲突和矛盾。为了总体最优就必须有妥协和让步。最终的理想结果就是将若干个一般水平的智能助理们合成一个更为一般的集成智能助理。例如同一个词在不同语境和领域下可能有不同的意思,但在特定的领域内词语的含义往往就是确定的。
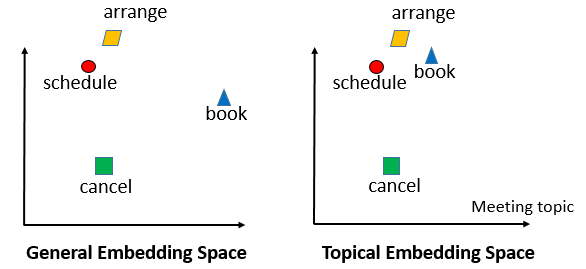
在我们开发 EDI训练意图识别(intention classification)和实体抽取(entity extraction)模型的过程中,使用了词向量(word embedding)作为特征表示,发现使用全局数据训练的词向量效果比只使用少量和日程规划相关的数据训练的词向量效果差很多,即使全局数据量远远大于局部数据量。分析数据发现,“schedule”和“book”两个词在全局空间并不是十分相似,而在局部空间两个词则非常接近。基于这个发现,我们使用了主题相关词向量(topic-aware word embedding)的算法,将训练数据的主题分类和词向量训练同时进行,得到的词向量很好地提升了EDI对于意图识别和实体抽取的准确率。
“超级” 智能助理的另一个难点是开放域的实体推理。EDI在时间理解方面就遇到了这样的问题。对于同一个表示“星期一”,在一个查询请求中“星期一有多少用户访问过我们的网站”,“星期一”应该被解析成过去的星期一,而对于预定请求“帮我订一个星期一的会议”这句话中,“星期一”则应该被解析成未来的星期一。EDI将这些和领域知识相关的参数作为隐变量,用递归神经网络(RNN)对请求中的上下文进行建模,利用封闭域数据学习时间抽取的结果到时间理解的结果的映射,进行上下文相关的时间语义理解。
所以,想要打造一个智能助理,可以先设定一个能够实现的“小目标”:找到一个可以自动化完成的任务,用与任务相关的数据训练模型,利用任务的特点提高自然语言理解和智能决策能力。做一个垂直领域“小而美”的智能助理往往更容易成功。
自救方法二:指导用户
对开发者来说,什么最珍贵?用户的耐心!
当前,用户对于智能助理最大的失望与不满(DSAT)在于智能助理难以准确理解用户的请求。通常,大多数用户没有耐心一遍又一遍地尝试让机器能理解自己的请求,当他们有几次DSAT之后,基本就会放弃使用该“智能”助理了。
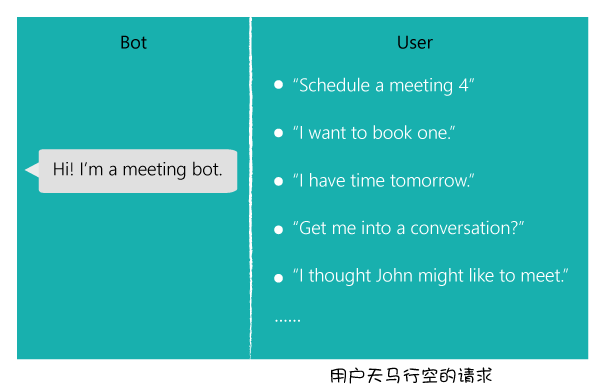
对话式服务和对话机器人与传统的基于GUI(图形用户界面)的交互方式的最大区别在于,基于GUI的交互方式通过对页面元素的限制,输入空间是有限的,因此机器可以枚举有限的输入组合完全理解用户的请求。而对于对话式交互服务来说,用户的输入空间是无限的,用户可以输入各种各样的请求(如上图)。因此,通过合理的方式对用户进行指导,告诉及指导用户机器可以理解的请求,用户只要依样画葫芦——在样例示范的基础上进行个性化的发挥,此举将用户输入空间大大缩小,智能助理从而就可以完成对应的任务(如下图)。这对用户和机器来说是两全其美的事情。依样画葫芦并不是要求用户输入的请求必须和我们的样例一模一样,否则大家都会更习惯传统GUI的交互方式。因为用户几乎不可能记住样例的每一个词以及它们的顺序。人工智能助理必须要能够理解这些样例模板的绝大部分等价表示(下图中的用户请求)。
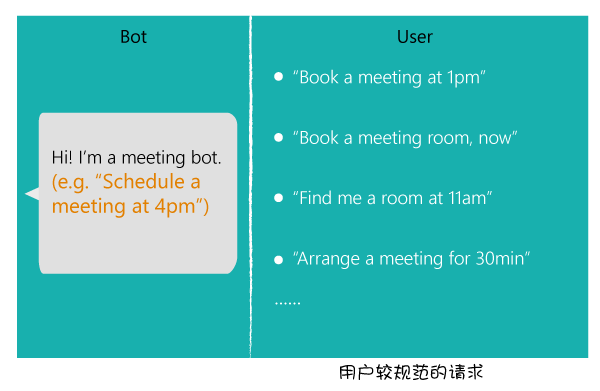
EDI利用统计滚雪球(Statistical Snowball)的方法[1]在海量数据(Bing,Cortana)中学习每个词语、短语的可替换表达,建立语义词典(Semantic Dictionary),并在语义词典的基础上进一步生成语言模板(Semantic Pattern)。在一个局部空间内,该方法理论上可以枚举自然语言中的所有等价表示。将指导用户的样例(如,schedule a meeting at 4pm)作为种子,通过该方法可以得到用户基于样例所输入请求所有的可能变换(Book a meeting at 1pm, Find me a room at 11am, Arrange an appointment tomorrow等)。
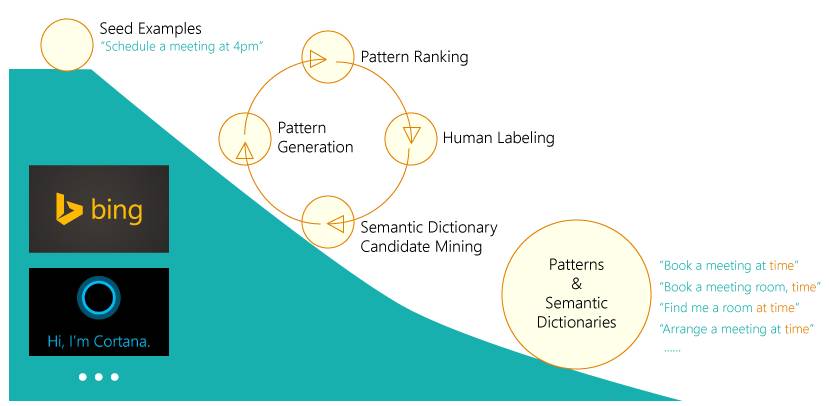
不仅如此,该方法在碰到有歧义或不能理解的请求时还可以利用语义词典生成动态提示,帮助用户快速完成任务。例如用户提到“schedule a meeting 4”,这里的“4”可以理解为时间,地点或人数,“4”在语义词典(通过海量数据挖掘得到)中对应的替换表达有“4pm”, “4th floor”, “4 people”, “4 years old”, “4 players”等,进一步结合句子“schedule a meeting”,利用语义模板挖掘的方法可以发现有意义的模板为“schedule a meeting at 4pm”, “schedule a meeting on the 4th floor”, “schedule a meeting for 4 people”。EDI会将这些可能的模板提供给用户进行选择。动态提示的方法不仅帮用户快速完成了请求,也提示了用户规范的样例。

通过对EDI的历史数据进行分析,我们还发现了两个有趣的现象:1. 随着使用时间的增加,越来越多的用户使用和样例相似的请求格式来完成任务;2. 有些用户会探索自己的模式,当他发现行之有效的请求格式后,在今后的使用中会一直沿用该模式。这也说明,当用户发现智能助理真的在某些任务上可以帮助自己节省时间、提高效率,他们就会尽可能用容易理解的请求去适应智能助理。
自救方法三:借助知识图谱
即使自然语言处理可以完全理解用户的请求,如果智能助理缺乏必要的知识,便无法进行合理的推理与决策,用户也会觉得智能助理并没有任何帮助。
没有任何知识帮助推理与决策的智能助理可能会出现下述场景:
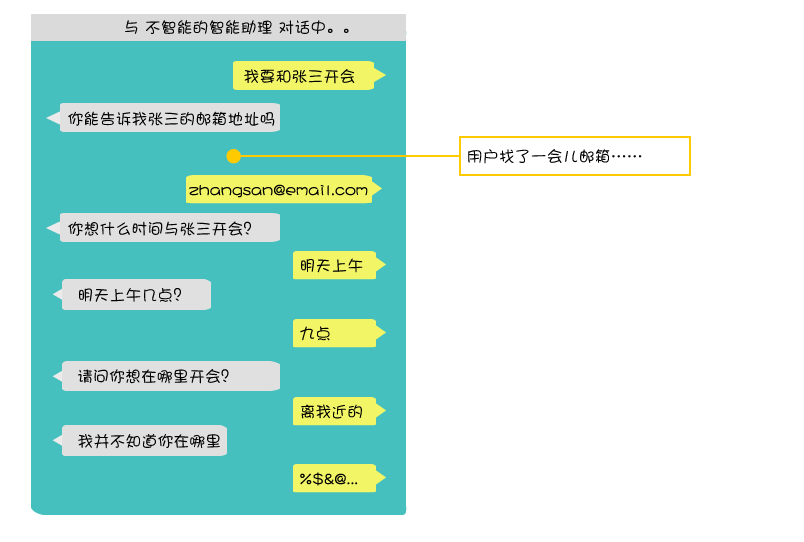
《构建企业知识图谱》一文介绍了如何构建企业知识图谱。利用该文介绍的技术,我们为智能助理EDI构建了对应的知识图谱,从中可以得到用户所在的大楼、楼层、位置、用户的关系网络、用户常去的会议室、用户的开会习惯、用户的日程安排等信息,在智能助理EDI完成任务时,这些信息使EDI变得十分智能。
使用了知识图谱的智能助理如下:
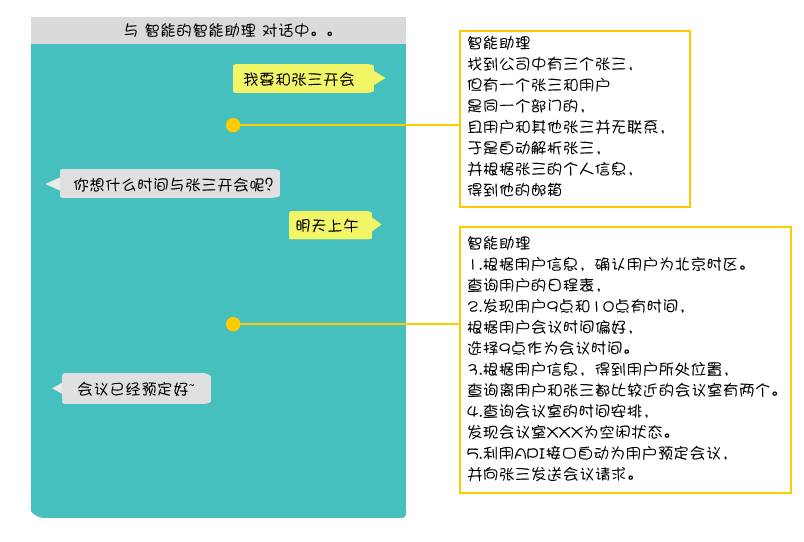
自然语言理解的结果通常为字符串形式(“张三”),而EDI需要结构化数据的实体ID(例如,张三的邮箱地址SanZhangFoo@outlook.com)来唯一指定一个现实生活中的具象的实体。从张三转化为张三的邮箱地址的过程通常被称为实体链接推理(Entity Linking)。我们构建的企业知识图谱可以很大地提高实体链接推理的效率。比如,用户在会议请求中提到了张三,而公司里有很多个张三,用户到底指的是哪一个张三呢?EDI使用了实体链接中的联合检索模型来选择正确的张三,联合检索模型可以综合考虑张三的关系网络,从而最大化知识图谱的价值。
自救方法四:人机协同
人机协同也被称为AI+HI(artificial intelligence + human intelligence,人工智能+人类智能)。在当前阶段,大多数的智能助理都很难做到100%的准确。在实践过程中,我们发现智能助理+真人助理的模式是解决问题的有效形式,智能助理可以根据自信度决定是否需要真人助理的协助完成任务。
人机协同并不只是简单的1+1=2的关系。通过不断学习真人助理的行为模式积累数据、积累知识,智能助理就能不断成长与进步。而真人助理则可以受益于机器执行效率高的优点,提高工作效率。
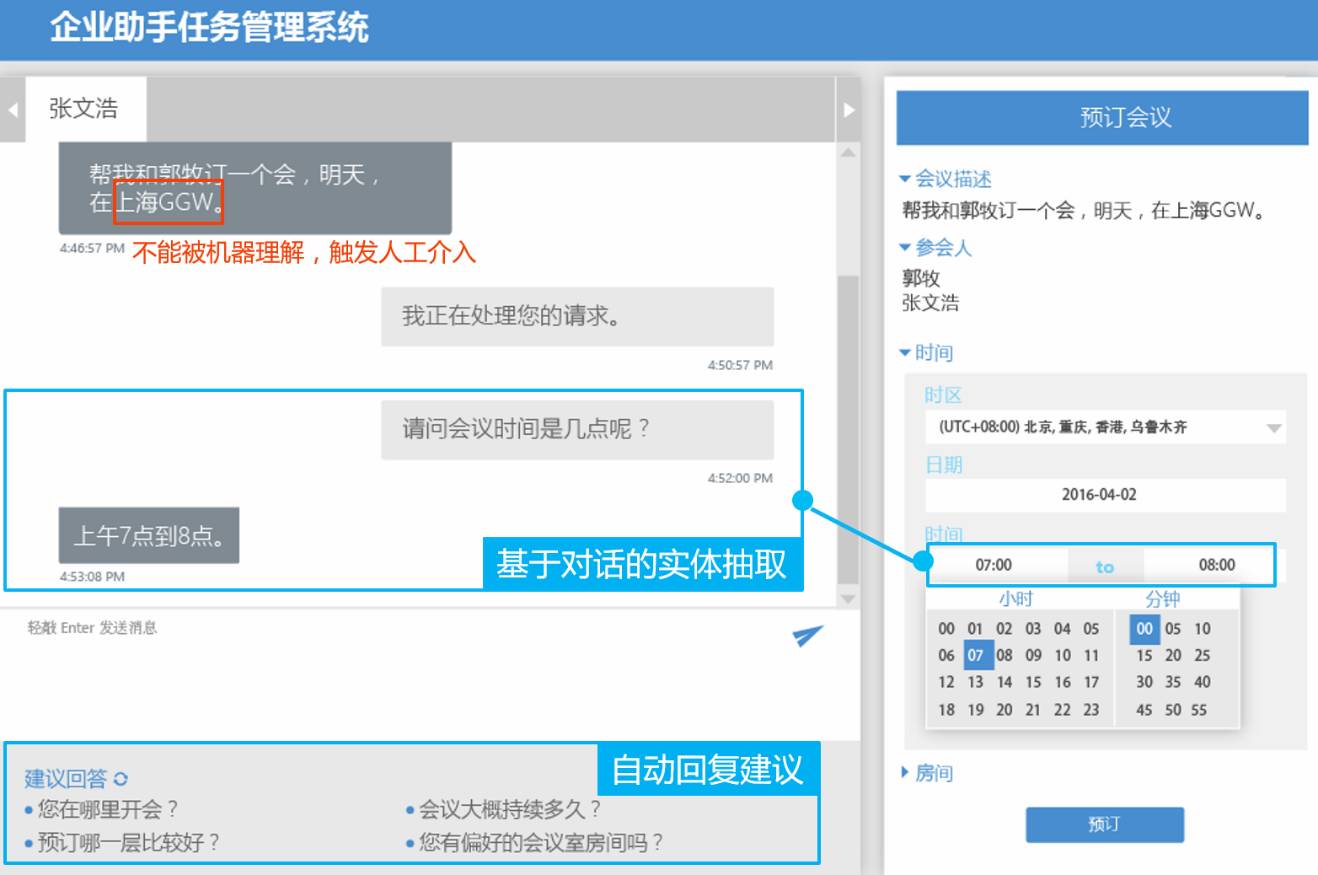
在EDI的实际应用中,我们尝试了人机协同的方式。面对一个会议请求,EDI首先进行处理,只有当EDI的自信度低于阈值时才由真人进行协助。实际上,即使对需要帮助的这类请求,我们的人机结合方案在保证准确率的同时也将实际完成一个任务的时间成本从3~5分钟降低为不到一分钟。在上图的示例中,EDI可以在真人助理的对话过程中进行实体抽取,帮助真人助理自动填写表单,同时EDI会建议几个他认为的最佳回复给真人助理。这样可以大大缩短用户等待真人助理回复的时间(这可以提高需要真人参与完成的那些请求的用户体验)。同时,EDI能从真人助理完成任务的对话历史记录中学习更多可能的回复。
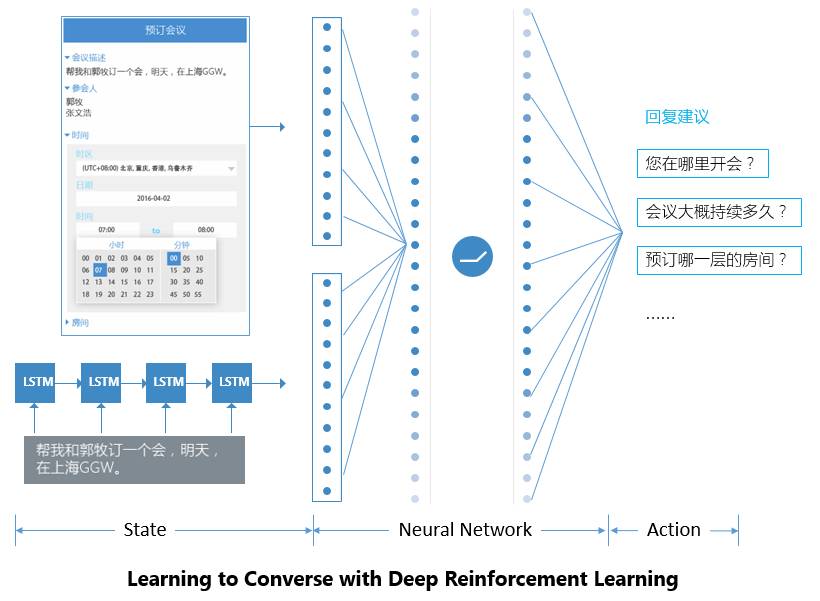
真人助理对自动回复建议采纳与否的每一次点击信号以及用户是否满意的信号为EDI提供并积累了大量的数据。EDI使用深度强化学习(Deep Reinforcement Learning)的技术根据真人助理对于回复建议的点击以及用户是否满意的反馈信息构建价值函数(value function)并根据获得的价值自行推理更优的对话策略,不断优化学习到的回复及其排序。这样EDI学到的对话策略及其最优回复建议都会和真人助理的回复越来越相似(甚至比真人助理的表现更好),智能助理就可以独立完成越来越多的任务,而逐步脱离对真人助理的需求。
再谈自然语言理解
作为智能助理的核心技术,自然语言理解是需要攻克的技术难题。前面提到的几个“自救法宝”其实都与自然语言理解息息相关。专注垂直领域和指导用户都是为了减小用户的语言输入空间从而弥补现阶段技术的不足;借助知识图谱其实是利用知识图谱帮助计算机进行自然语言的理解和消歧;人机协同则是通过人和机器的不断交互,让机器不断进行增量学习,逐步提高计算机的自然语言理解的能力。
微软亚洲研究院大数据挖掘组专注于两个方向的自然语言理解研究。
第一个方向是通过海量数据来挖掘自然语言表达的等价表达模式,用以提高机器自然语言理解的能力,从根本上解决自然语言理解能力的局限。
第二个方向是将自然语言理解平台化,使没有自然语言理解背景的开发者可以简单地开发和自然语言理解相关的应用,真正地做到CaaP(Conversation as a Platform,对话即平台)。我们组的下一篇文章会具体的介绍我们的技术怎么被应用到微软的产品LUIS[2]和Bot Framework[3]中来帮助广大第三方开发者们开发真正智能(“不智障”)的助理!
【大数据挖掘组】
微软亚洲研究院大数据挖掘组致力于从大数据中挖掘信息构建海量知识图谱,以提高人工智能应用中的知识推理和自然语言理解能力。大数据挖掘组的研究方向包括数据挖掘、大数据、深度学习、自然语言处理、智能聊天机器人等。十多年来,该组成员的研究成果对微软的许多重要产品及应用产生了深刻影响,包括人立方、微软学术搜索、读心机器人、微软知识图谱(Satori)、智能聊天机器人开发平台等。
大数据挖掘组现招聘实习生,工作内容涉及机器学习、大数据挖掘、自然语言处理等领域,工程和研究均可,根据个人兴趣和能力确定工作内容。要求编程能力较强;有一定的沟通能力,有责任心;对机器学习、大数据挖掘、自然语言处理有热情和兴趣; 高质量的完成工作;半年以上实习期。
