本文来自微信公众号“半导体行业观察”。
在今年的Hotchips,很多专家分享了关于光芯片互联的一些技术。例如特斯拉、博通、openAI、博通和英特尔等。从这些厂商的积极布局看来,我们以为光芯片互联已经到了爆发前夕。但其实在不少人看来,这还为时过早。
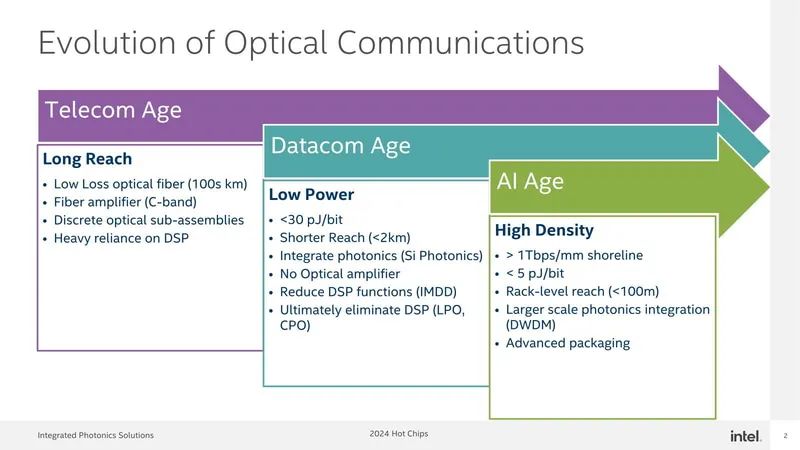
图1:这是“芯片到芯片”连接,而不是“芯片内”连接。英特尔似乎改变了主意,称距离使用光进行内部芯片连接还有很长的路要走。
光通信需求的变化
上面的图显示了英特尔对光通信演进的看法。这是夸张的说法,考虑到光纤实际上在电信时代之前就已经被使用了,在20世纪90年代就向客户介绍了使用基于光纤的令牌环(token ring)来创建LAN的系统。电信时代和数据通信时代有很多重叠。不过,考虑到光纤相关技术最初是为了长距离通信而开发的,也曾被用于其他目的,这可能有些夸张,但这并不是谎言。
在长距离应用的情况下,能够稳定长距离和拓宽频段是首要考虑的,成本和功耗是其次的。对于DSP来说,它很可能被用作长距离应用的骨干,因此可靠性至关重要。
然而,随着数据中心内基于铜线的以太网被基于光纤的以太网取代,新的需求出现了。当然,带宽在这里是必要的,但降低成本和功耗也变得很重要。
大量的服务器排列在大量的机架中,这些服务器通过TOR(机架顶部)和BOR(机架底部)连接到网络交换机。由于这些交换机将相互连接并连接到大规模的后端交换机,因此迫切需要降低每个网络端口的功耗,而这也将影响数据中心安装成本的降低。结果是,市场催生了以下需求:
- 旨在通过使用硅光子学来降低功耗;
- 增加输出功率(和/或)增加接收器的灵敏度,从而消除光放大器(这降低了成本和功耗)
- 减少DSP的功能,有可能就去掉(因为DSP的功耗很低,而且DSP的处理比较复杂,这也是延迟增加的原因之一)
- 这些需求已经改变。这是引入CPO背后最大的因素。
顺便说一下,去年11月Intel出售给Javi的可插拔以太网收发器业务,正是针对这个数据通信时代的解决方案。再顺便说一句,“硅光子学”和“硅光学”这两个符号都被使用,但它们具有相同的含义。
这就引出了我们当前的主题:人工智能时代。
芯片间光通信
简而言之,如果用于芯片到芯片的连接,则范围仅限于机架内或机架之间(或者更确切地说,除非将其限制在该区域,否则没有尽头)。随着带宽的增加,功耗必须进一步降低。当然,不应增加每个波长的速度,而应将每个波长的速度降低到DWDM。由于CWDM需要支持多种波长,因此使用DWDM比较合适。
用于此目的的光学组件(例如MUX/DEMUX)已经在英特尔内部开发了很长时间,因此实施起来很容易。因此,他们开发的不是“使用高速光信号的串行芯片到芯片互连”,而是“并行芯片到芯片互连”的原型,它捆绑低速光信号以创建一个宽带。”
顺便说一句,“CPO”这个词早些时候出现过。这是“Co-Package Optics”的缩写,这个术语最近开始被普遍使用,但迄今为止它展示的第一个应用是以太网交换机,然后是计算结构。这里将解释芯片之间的连接(图2)。

图2:如果Intel仍然继续开发Barefoot的Tofino,未来的产品中可能会有使用以太网CPO的产品
事实上,这种趋势对于博通来说也是一样的。对于可插拔以太网收发器,该公司将首先用硅光子取代传统的II-V光学元件(图3),然后将该技术应用于交换机,最后应用于芯片到芯片的连接(图4)。

图3:这是可插拔以太网收发器的故事。这里所说的III-V族很可能是指GaAs与InP、Sb等结合的VCSEL结构的激光源。

图4:左侧交换机配备16个CPO,16个端口(每侧4个),可配置总共256通道的光纤以太网交换机
台积电也是如此,在今年6月举行的技术研讨会上,他们提出了一个路线图,首先将其COUPE(COmpact通用光子引擎)应用于可插拔以太网收发器,然后应用于交换机。
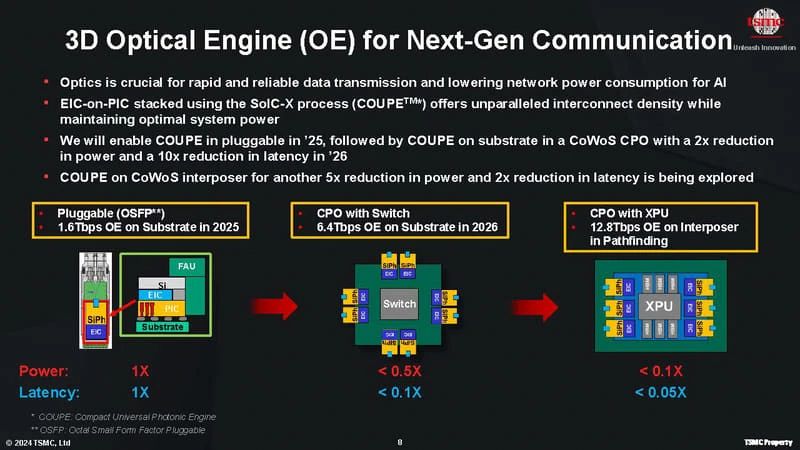
图4:台积电的光芯片路线图
Marvell和GlobalFoundries也涉足硅光子和光纤以太网,其路线图可能相似。Intel不处理交换机(不,Intel Foundry处理它们的可能性非零,所以将来有可能,但我在不久的将来看不到),所以我会跳过这是XPU芯片到芯片技术的一个进步。
现在,这是Intel的配置(图6)。XPU就是所谓的处理器,它和CPO Chiplet之间的连接是UCIe。CPO底部有一个EIC(电气集成电路),必要时可在其中集成UCIe I/F和DSP。电/光转换由EIC顶部的PIC(光子集成电路)执行。该PIC使用硅光子学实现。

图6:Foveros可能是用来堆叠PIC和EIC的。看来在这个实现中,DSP并没有在EIC中实现
该CPO小芯片可实现4Gbps的互连。虽然波长为(SR:短距),但约为1,310 nm,通常是xBASE-LR等使用SMF(单模光纤)使用的区域,但无法与MMF(多模光纤)通信甚至没有。
我认为他们不使用850nm左右波长的原因是由于输出和衰减问题。每个波长的速度为32Gbps,但以1310nm为中心的8个波长以约1.2nm的间隔转换为DWDM,并通过单根光纤。它实际上由每个方向8根光纤组成,因此总带宽为32 x 8 x 8=2,048 Gbps。
假设它将应用于PCI Express 6.0,因此看起来配置是不通过以太网帧,但如果需要的话可以直接通过PCIe。
首先,我认为32Gbps和NRZ调制的传输速度是因为PCI Express 5.0信号是按原样进行光学转换的。事实上,它被写为“un-retimed PCIe6”,表明PHY当前正在使用NRZ进行传输,但如果需要,也可以使用PAM4进行传输。
目前,EIC似乎兼容UCIe 1.1,因此PAM4信号无法按原样传递,但兼容2.0的下一代EIC将按原样传递PCIe 6信号,将其交给PIC,并将它们转换成光信号进行传输。在这种情况下,他们似乎正在考虑使用PCIe FLIT来进行纠错,而不使用FEC。
简而言之,它的工作原理类似于PCI Express光纤扩展器。在这种情况下,XPU通过读取和写入PCI Express设备进行操作,然后通过光纤直接连接到另一个XPU。或者,对于PCI Express,传输模式有限制,因此逻辑层可能是CXL,但这不是一个大问题。这里的重点是它似乎使用PCIe作为物理层。
对于光纤以太网,FEC引起的延迟不可避免地会增加。为了避免这种情况,我们的想法是保持每个通道的速度较低,并使用PCI Express纠错和FLIT来扩大带宽,同时保持XPU之间的通信延迟较低。
为什么英特尔不将一切与硅光子集成?
为什么英特尔使用CPO而不是将一切与硅光子集成?这就是故事。
在图7中,XPU自然是一种硅工艺。既然是XPU,那么现在可能是Intel 7或Intel 3,将来可能是Intel 18A。EIC当然是硅工艺,如果使用硅光子,PIC也是硅工艺。
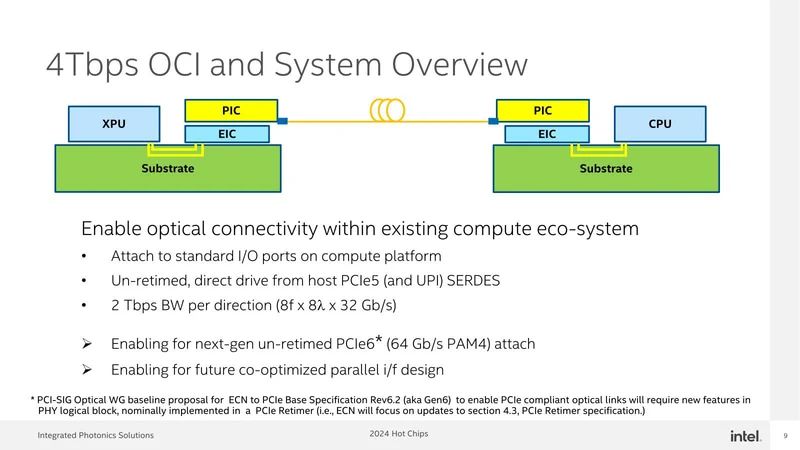
图7:4Gbps是双向总带宽,单向2Tbps。顺便说一句,由于正文中提到的原因,EIC接口可能会有四个16位宽的32Gbps UCIe
到目前为止的想法是,“如果我们集成所有东西,制造不是更容易吗?”然而,英特尔这次的结论是,将它们分成小芯片实际上会更有效。虽然没有显示EIC和PIC工艺,但EIC很可能在22nm或14nm左右,PIC将在45nm或65nm左右。
原因很简单。EIC需要以一定的电压将信号传递给PIC,PHY占用很大的面积,如果我的假设正确的话,根本不需要协议转换或FEC,所以高速逻辑是不必要的。32Gbps PHY采用22nm工艺可能有点困难,但采用14nm工艺则可以毫无问题地制造。而且无论PHY是用14nm还是18A制作,面积几乎是一样的。
说白了,尖端工艺不适合需要一定电压的应用(虽然不是不可能,但效率低下),因为工作电压会随着工艺变小而降低。在这种情况下,使用22nm或14nm等较旧的工艺将更容易处理高电压,并且如果面积保持不变,制造成本也会更低。
这种情况在PIC中更为极端,其中基于硅光子的电路元件最初是使用平面型工艺而不是FinFET工艺开发的,并且这些元件的尺寸甚至更大。
在2022年Hot Interconnects大会上,英特尔James Jaussi的邀请演讲中透露,TIA是采用22nm工艺开发的(图8)。然而,考虑到并非所有组件都可以用22nm制造,我怀疑该工艺实际上有点老了。
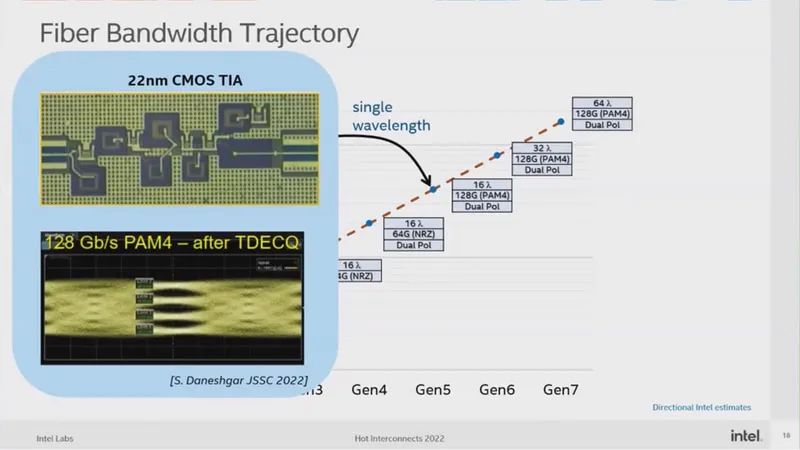
图8
回到主题,“在同一块硅中实现电和光”的旧想法不幸的是不现实,唯一现实的解决方案是以chiplet的形式分离组件。
与Knights Hill的关系取消
当我看到Intel发布的芯片照片(图9)时,我想起了Knights Hill。

图9:乍一看像是一对2根光纤,但里面却有8对16根光纤。
Knights Hill计划于2016年发布,采用10nm工艺,并于2014年11月的SC14上揭晓,计划在Aurora中实现,英特尔将交付给ALCF。然而,在2017年11月举行的SC17上,一篇博客文章简单提到Knights Hill将被取消。
根据存储在网络档案中的文章,拥有可以直接从CPU连接到外部互连(Omni-Path Fabric)的产品。这一代Omni-Path Fabric仍然是100Gbps铜缆,而下一代应该是200Gbps铜缆或光纤。
因此,Knights Hill也计划提供一个将下一代200Gbps与光学连接的版本,并且似乎一直在讨论将硅光子纳入其中,但由于Knights Hill的取消和Omni-Path的退出,所有都消失了。
由于故事已经消失,我不知道带有这种光学接口的Knight Hill计划采用什么样的结构,但它可能会配备像Knights Mill一样结合EIC和OIC的外部芯片,这一定很酷。
然而,实际上,集成EIC和OIC是相当困难的(旧工艺使得无法提高与Xeon Phi的接口速度),这可能是Knights Hill被取消的原因之一。不这么认为(虽然我认为最大的问题是Intel的10nm在2016-2017年的时间范围内根本没有投入实际使用)。现在制作Knights Hill无论是制程还是界面都是完全可能的。所以Knights Hill早了10年。
让我们回到4Tbps OCP。这种界面有多大用处?有些人可能会这么认为,但英特尔实际上使用100GbE或200GbE与Gaudi 2(图10)和Gaudi 3(图11)进行外部连接。用当前的4Tbps光纤替换它将使布线更加容易,提高速度,并可能降低通信所需的功耗。
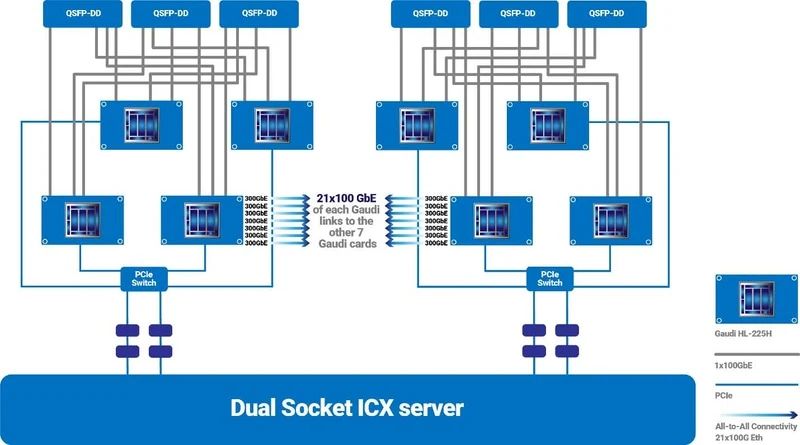
图10:来自Gaudi 2白皮书。21根100GbE电缆以7对3电缆排列,Gaudi 2设备相互互连。另外三个100GbE端口将用于外部连接
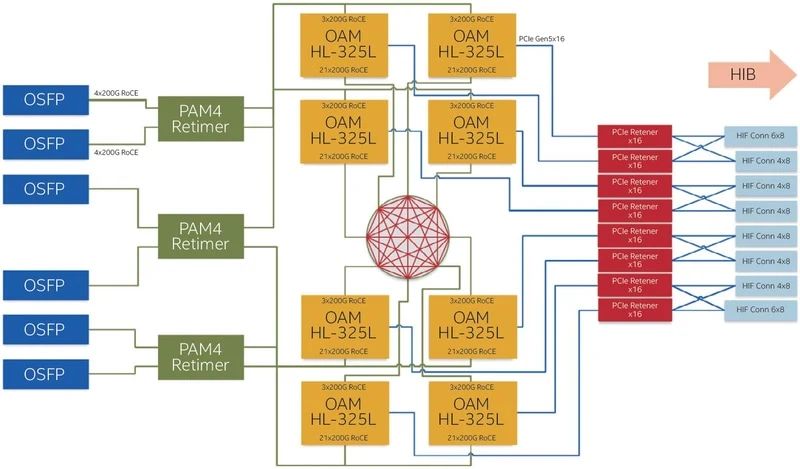
图11:来自Gaudi 3白皮书。这已从100GbE变为200GbE,但我们仍然需要将3根线捆绑在一起形成7对,这将互连8个Gaudi 3
其他AI处理器厂商也采用了类似的配置,这些芯片之间点对点应用的需求非常大。它会被Xeon采用吗?这可能看起来有点奇怪,但作为Intel Foundry提供的解决方案,它似乎很有前途。
相反,将电和光集成在单个硅中的旧愿景仍然为时过早,而且在技术上也很困难。这可能吗?老实说这很可疑。无论怎么看,3D堆叠都更灵活、成本更低、更可靠。
光学计算,下一个热点
如Yole所说,近年来,因为多种原因的影响,光学计算也成为了一股新兴力量。
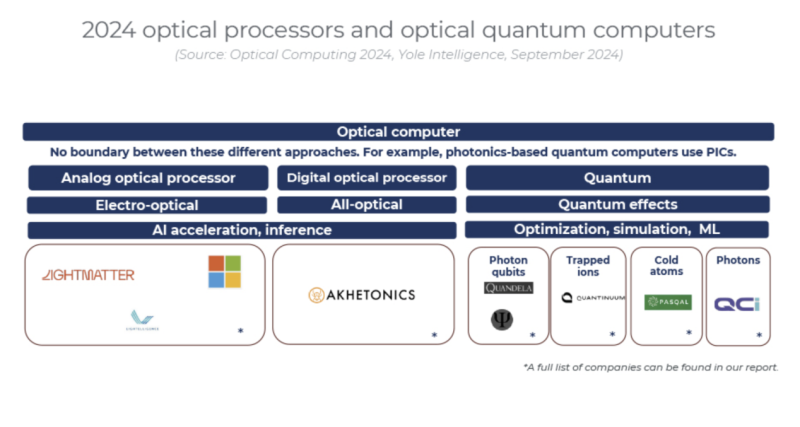
但他们也承认,光学计算仍处于早期阶段。如上所述,一些大公司已将重点从光学计算转向光学I/O,但新的光学计算初创公司不断涌现,探索各种方法。
光学处理器主要针对人工智能推理任务。此外,基于量子位和其他量子效应的光学量子计算机可用于各种应用,例如模拟、优化和人工智能/机器学习。另一方面,光学处理器将专门针对人工智能推理。
Yole估计,第一批光学处理器将于2027/28年开始出货。2027年的首批出货可能用于实施该技术部分内容的定制系统,大部分收入来自非经常性工程(NRE)服务。到2028年,配备光学处理器的通用系统的直销将开始。从2029年开始,早期采用者、随后是OEM和系统集成商将逐渐采用光学处理器。到2034年,我们估计光学处理器的总数将达到近100万台,代表着数十亿美元*的市场价值。
Yole还预测,从2030年开始,基于光子的量子计算机的出货量将出现大幅增长,其中Quandela、QUIX和Pasqal等公司将引领这一潮流。到2034年,预计该市场在系统层面的价值将达到数百美元*。未来几年,该领域的大部分收入将来自项目和NRE。

光学计算并不是一个新概念,而且有很多方法可以实现光门,其中光子集成电路和量子光学是当今最有趣的方法。然而,尽管取得了进展,实用的光逻辑门仍然面临重大挑战,因为它们需要满足多个标准,例如门之间的级联性、可扩展性和从光损耗中恢复,才能与电子门竞争。虽然当前的研究通常涉及单个门或简单电路,但大型光学计算机的开发仍处于早期阶段。
硅光子学因其可扩展性而成为光学计算的一项使能技术。光子学的最大问题之一一直是集成。随着集成光学通过不同的材料方法(SOI、SiN、TFLN、石墨烯、BTO、聚合物)迅速发展,这可能为基于PIC的实用光学处理器铺平道路。集成度的提高也将使量子光学界受益,因为它能够开发出具有更多量子比特且外形紧凑的量子光学计算机。
目前,制造光学处理器的方法有很多种。它可以是模拟的,也可以是数字的,使用各种光学介质来处理数据,例如PIC、FSO或光纤。对于基于量子比特的光学量子计算机,我们考虑了三种不同的方法。一种使用光子量子比特,而另外两种使用光子学来控制非光子量子比特,例如捕获离子和中性/冷原子。
此外,一些公司声称正在开发不基于量子比特的光学量子计算机,而是使用光量子效应和非线性。光学处理器还在开发新型材料,尽管它们仍处于非常早期的阶段,例如超表面和SiC。
光学计算的成功需要多维度的方法,解决集成挑战、制造复杂性和基础设施要求。在地缘政治方面,特别是关于美国/中国的禁令,当中国国内芯片生产赶上时,美国将需要已经开始攻克先进计算的下一个技术前沿,例如基于光的计算或量子计算。光学量子供应链仍处于早期阶段,对需要大量研发的先进产品的需求很高,导致交货时间较长,阻碍了进展。
尽管如此,供应链仍然高度动态,有GlobalFoundries、台积电、三星、LioniX等众多参与者提供PIC代工服务。该行业仍在努力应对“小批量问题”,因为该行业尚未达到规模化和商业化阶段,目前的重点仍然放在开发和原型设计上。
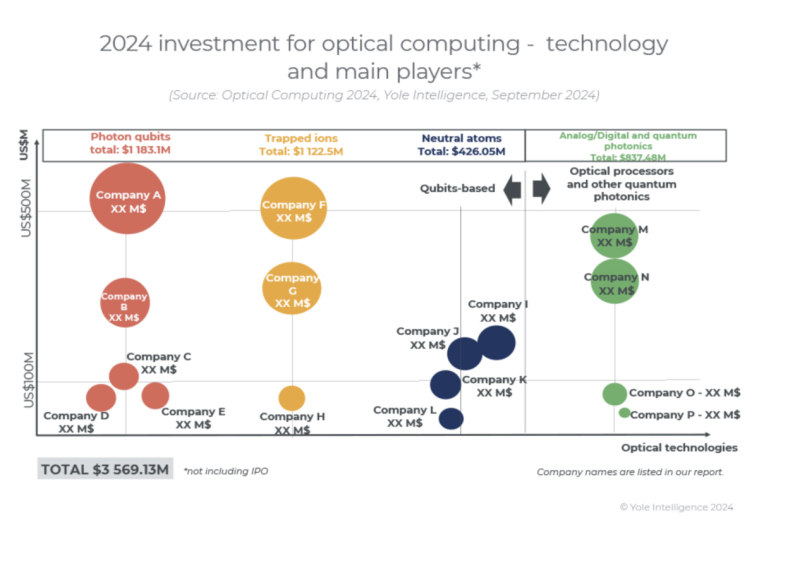
过去五年,从事光学计算的公司筹集了近36亿美元。随着谷歌、Meta和OpenAI等巨头将人工智能能力推向极限,更快、更高效的计算竞争正在加剧。最新一轮融资凸显了投资者的信心,他们相信光子学能够提供未来维持人工智能进步所需的突破。
然而,与一般的量子计算机一样,很难预测光学计算的拐点何时会出现。光学计算平台预计将在未来几年内在学术和私人研究领域得到一定程度的应用,但它们是否会在短期至中期内实现广泛的适用性和采用仍不确定。
参考链接:
https://pc.watch.impress.co.jp/docs/column/tidbit/1626432.html#Photo02_l.jpg
https://www.yolegroup.com/press-release/could-optical-computing-solve-ais-power-demands/
