本文来自微信公众号“半导体行业观察”,【作者】编辑部。
据韩媒KEDGLOBAL引述相关消息透露,SK海力士将采用目前最先进的代工技术3纳米工艺,在2025年下游生产定制的HBM4芯片。
报道指出,这家韩国芯片制造商原计划在5纳米节点上为客户定制第六代高带宽工厂(HBM4)。它正与代工领导者台积电(TSMC)合作开发HBM4。但最近,应主要客户对更先进工厂的要求,SK海力士已转向3纳米工艺生产HBM4,预计将于2025年下半年向Nvidia公司供货。
消息人士告诉《韩国经济日报》,SK海力士将于3月份推出相当多的在3纳米HBM芯片上的HBM4原型。Nvidia的图形处理单元(GPU)产品目前基于4纳米HBM芯片。借助台积电的CoWoS封装,基片位于连接到GPU的HBM底部,充当GPU的大脑。与采用5 nm基片的HBM4相比,堆叠在3 nm基片上的HBM预计性能将提高20-30%。
在华盛顿限制对华出口之际,SK海力士正全力投入Nvidia Corp.、Google LLC和Microsoft Corp.等美国大型科技公司,以减少对中国的依赖,因此英特尔转向3 nm代工工艺。
SK海力士占据全球HBM市场约一半的份额,并将其大部分HBM产品运往全球最大的AI芯片买家Nvidia。使用3纳米基片生产HBM4将进一步拉大其与三星电子的差距,后者计划将其4纳米代工工艺应用于第六代HBM(即HBM4)。
HBM渐成主流
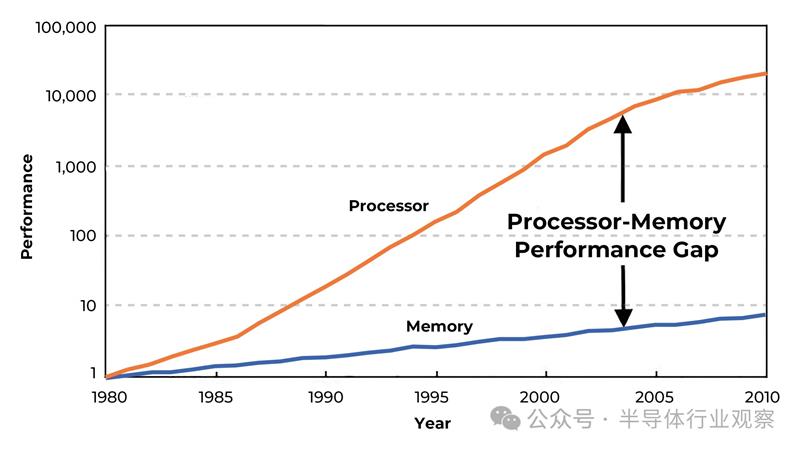
正如Alphawave Semi在一篇文章中所说,随着AI模型的规模和复杂性不断增长,它们会生成和处理越来越庞大的数据集,从而导致内存系统出现性能瓶颈。这些内存密集型操作会给内存层次结构带来压力,尤其是在训练大型神经网络等高吞吐量场景中。
我们看到CPU处理能力不断提高,遵循摩尔定律,但内存访问速度却没有保持同样的速度。专用AI硬件虽然能够实现极高的并行性,但受到内存延迟和带宽的限制。这种瓶颈通常称为内存墙,会严重影响整个系统的性能。为了应对这些挑战并缩小内存性能差距,人们正在探索3D堆叠内存技术等领域的进步,通常称为高带宽内存(HBM)。
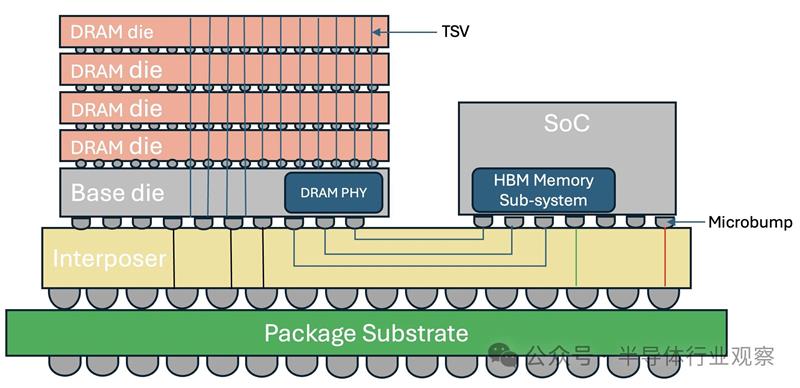
HBM采用3D堆叠架构,其中内存芯片垂直堆叠并通过硅通孔(TSV)互连。堆叠的DRAM通过中介层连接到处理器芯片。这减少了数据必须传输的物理距离,并允许更高的数据传输速率和更低的延迟。
总体而言,HBM拥有以下几点优势:
- 高带宽–使用宽内存接口总线可为芯片之间的数据传输提供大量带宽。这对于并行处理工作负载(例如AI模型训练和深度学习中的工作负载)特别有用。
- 更小的外形尺寸–与传统内存配置相比,HBM的3D堆叠设计占用空间更小。这些堆叠随后安装在处理器旁边的硅或有机中介层上,从而形成高度紧凑的内存系统。
- 低功耗–HBM的设计功耗也低于传统内存,尤其是在提供高带宽时。低功耗是现代计算硬件设计的一个关键因素,特别是对于通常大规模部署的AI系统而言。
- 降低延迟–与DDR和GDDR等片外内存解决方案相比,HBM可提供更低的延迟。凭借最近对2.5D中介层和3D堆叠等先进封装技术的投资,它可实现更紧凑的SoC设计,适合异构计算。
对于性能和带宽至关重要的应用,HBM具有显著优势,尽管成本高、复杂度高,但它仍然是最可行的解决方案之一。随着计算工作量因人工智能和大数据的爆炸式增长而不断演变,管理和访问内存的新方法对于克服内存瓶颈至关重要。
而随着人工智能的复杂性不断增加,HBM在释放下一代人工智能硬件的全部潜力方面的作用将变得越来越重要。随着演变,下一代HBM4和HBM4E技术将通过将接口宽度加倍至2048位来进一步满足AI工作负载的需求。

但是,随之而来的挑战,也是显而易见的。
HBM实施挑战
因为实现具有高带宽内存(HBM)的2.5D系统级封装(SiP)是一个复杂的过程,涉及架构定义、设计高可靠性中介层通道以及对整个数据路径进行稳健测试(包括系统级验证)。
总体而言,HBM拥有几方面的挑战:
制造复杂性–HBM采用3D堆叠架构构建,制造TSV和对齐多层内存芯片所需的精度远高于传统内存。此外,HBM通常安装在硅中介层或有机中介层上,这为内存堆栈和处理器之间提供高速通信。这需要先进的光刻技术和精确的芯片放置,这增加了制造的整体复杂性。
热管理–由于HBM的堆叠特性,多个DRAM芯片彼此叠放,内存芯片产生的热量会积聚在堆叠中。这带来了巨大的热挑战。通常需要使用液体冷却、热界面材料(TIM)和集成散热器等先进冷却方法来缓解热节流。
总拥有成本–由于2.5D中介层和3D堆叠技术需要先进的制造技术,实现高产量可能非常具有挑战性。即使任何堆叠芯片或互连中出现一个缺陷,也可能导致整个HBM堆叠失效,从而降低整体制造产量并增加成本。
在具体实现过程中,则需要注意以下几方面的问题:
首先,在高级设计与架构规划时,要确定必要的带宽、延迟和功率要求对于规划整体系统架构非常重要。单片芯片还可以分解为更小的专用模块(称为chiplet),以处理系统内的特定功能。这种方法可以提供增强的设计灵活性、功率效率、产量和整体可扩展性。

来到中介层设计的时候,由于中介层可以是硅材料或有机材料,并支持多个金属层以处理HBM堆栈和计算芯片之间的高密度布线。值得一提的是,因为HBM4将以HBM3E中的改进为基础,旨在进一步提高数据速率、能效和内存密度。由于接口宽度增加了一倍(至2048位),但HBM4内存shoreline与HBM3E保持不变,因此主要挑战是如何管理PHY和中介层中更密集的I/O布线。布局应确保仔细的信号布线、电源分配和接地,以最大限度地减少通过通道的串扰和损耗,从而满足HBM4E规范。
去到SI和PI分析时,为了防止HBM4E数据速率下的信号衰减,我们需要执行阻抗匹配、屏蔽等技术,并采取措施确保相邻走线之间的串扰最小。中介层的特征包括插入损耗(IL)、反射损耗(RL)、功率总串扰(PSXT)和插入损耗与串扰比(ICR),以表征通道并确保我们满足下一代HBM4E技术的要求。
此外,供电网络也需要仔细规划,以确定去耦电容、低阻抗路径和关键敏感信号的专用电源层。在确定供电网络的目标阻抗时,需要考虑主板、封装、中介层和硅片等所有组件的噪声贡献。
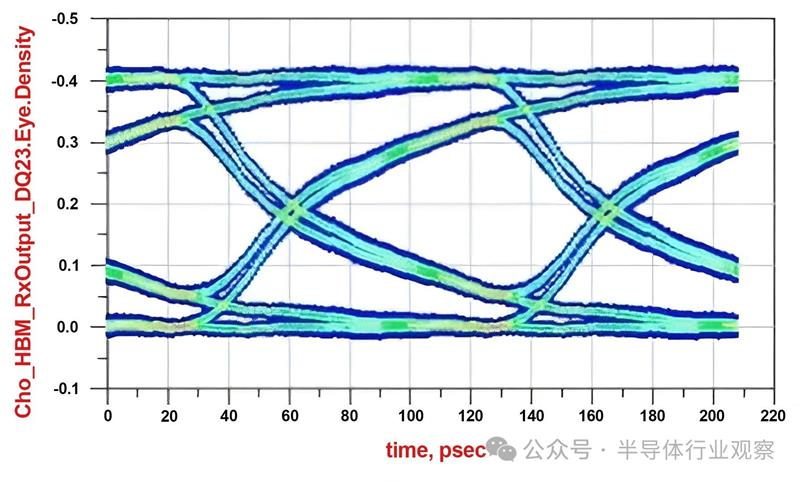
最后,广泛的SI-PI测试可确保HBM封装符合抖动和功率规格。将中介层引起的抖动分解为ISI、串扰和上升-下降时间退化有助于识别影响EYE闭合的主要通道参数,并有助于更好的布局和I/O架构优化。
对数据路径中的所有组件进行系统级测试对于确保组装好的封装满足设计阶段规定的性能规格至关重要。包括支持DFT的设计在内的综合测试套件对于实现高产量的早期诊断也至关重要。

自定义的HBM
在过去,我们谈的HBM都是通用的HBM,但从HBM 4开始,则以客制化为主流。在AI已经突破了计算系统极限的当下,HBM的自定义实现允许与计算芯片和自定义逻辑进行更好的集成,因此可以成为证明其复杂性合理的性能差异化因素。
整体看来,定制HBM集成具有以下几点优势:
1. 更好地协调记忆与需求
定制HBM4设计意味着优化内存和内存控制器,使其与处理器或AI加速器的特定需求紧密结合。这可能涉及调整内存配置(例如,通过增加带宽、减少延迟或添加更多内存层)并微调芯片间接口以确保顺畅快速的通信。
2. 2.5D集成
在2.5D封装中,处理器芯片和HBM定制芯片并排放置在中介层上,中介层充当它们之间的高速通信桥梁。这种方法允许使用宽数据总线和短互连,从而实现更高的带宽和更低的延迟。
3. 芯片间接口提高了带宽
芯片间接口可以支持高时钟速率的超宽数据总线,从而实现巨大的带宽吞吐量。
4. 它还可以改善延迟
通过缩短内存和处理器之间的距离,芯片到芯片接口可以最大限度地减少访问外部内存带来的延迟。这在AI模型训练和推理中至关重要,因为延迟会严重影响性能。
5. 电源效率
更短的互连距离和对外部内存控制器需求的减少降低了功耗。这对于运行高功耗AI工作负载的数据中心以及对电源效率至关重要的边缘AI设备来说是一个关键优势。
总体而言,当与芯片到芯片接口结合使用时,定制HBM可提供强大的解决方案,帮助解决AI芯片面临的内存瓶颈问题。通过利用2.5D和3D堆叠等先进封装技术,AI芯片可以实现超高内存带宽、更低延迟和更高能效。这对于处理现代AI工作负载的海量数据需求至关重要,特别是在深度学习、实时推理和高性能计算等应用中。虽然在成本和热管理方面存在挑战,但性能优势使这种方法对于下一代AI硬件系统非常有价值。
而使用诸如UCIe标准(Universal Chiplet Interconnect Express)之类的芯片到芯片接口则是创建自定义HBM的一种尖端方法,该方案涉及将内存芯片与计算芯片紧密集成,以实现极高的带宽以及组件之间的低延迟。在这种实现中,内存控制器通过内存基座芯片上的硅通孔(TSV)PHY直接与HBM DRAM接口连接。来自主机或计算机的命令通过使用流式协议的芯片到芯片接口进行转换。这允许重用主芯片上已占用的芯片到芯片海岸线,用于核心到核心或核心到I/O连接。这种实现需要IP供应商、DRAM供应商和最终客户之间的密切合作,以创建自定义内存基座芯片。
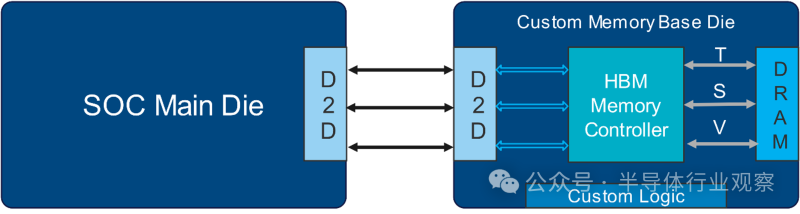
但要实现这个,需要产业链的完美结合。
写在最后
HBM 4的定制化已经在产业链达成共识。但依然还有通过HBM 4的需求。
kedgloabal在报道中表示,对于通用的HBM4和HBM4E,SK海力士将与台积电合作采用12纳米工艺技术。这家全球第二大内存芯片制造商使用其基础芯片制造了HBM3E,即第五代HBM。但对于HBM4芯片,它已决定采用台积电的技术。
应Nvidia的要求,SK海力士正在加快HBM4芯片的开发。
Nvidia首席执行官黄仁勋最近要求SK集团董事长崔泰源将12层HBM4芯片的供应从SK的2026年初的计划提前六个月,崔泰源上个月在SK AI峰会2024上发表主题演讲时表示。
与此同时,韩国半导体行业消息人士上个月告诉《韩国经济日报》,特斯拉公司已要求三星和SK海力士提供用于通用的HBM4原型样品。在测试原型后,这家全球第一大电动汽车制造商预计将选择这两家公司中的一家作为其HBM4供应商。
至于他们韩国本土的另一个竞争对手三星。早前消息显示,三星电子目前正在开发HBM4,以提供给微软和Meta。报道指出,三星将以4nm量产HBM4,对抗SK海力士/台积电联盟。
参考链接
https://www.kedglobal.com/korean-chipmakers/newsView/ked202412030008
https://www.design-reuse.com/industryexpertblogs/57123/redefining-xpu-memory-for-ai-data-centers-through-custom-hbm4-part-3.html

