本文来自微信公众号“twt企业IT社区”,作者/李威,某金融机构架构师。
5月13日,OpenAI用一场春季发布会再次让AI整个产业链都为之沸腾。ChatGPT的新产品ChatGPT-4o,感知能力更强,不再是一个只会帮你生成内容的聊天的工具,而能实时对音频、视觉以及文本进行推理,神似一名智能的AI助理。不由得让我联想到2018年发售的一款游戏《Detroit:Become Human》,身临其境的全智AI体验,游玩的时候相当震撼,这一天似乎也快到来了?
前些天收到了社区寄出第8期《迈向YB数据时代》,恰巧本次的主题也是“大模型行业应用”,虽然笔者是一名非AI专业的局外人,但对AI大模型发展趋势的关注却与日俱增。随着AI技术的迅猛发展,大模型在各行各业的应用越来越广泛。从语言模型到计算机视觉,AI大模型正在改变我们的生活和工作方式。在拜读完各位专家的大作后,就AI的基础架构唠个嗑,聊表慰藉。
2023年9月,在处理器和系统工程师年度盛会Hot Chips上NVIDIA首席科学Bill Dally介绍了加速计算和AI背后的硬驱动力,从三个方向介绍了基础硬件带来的效率提升:新的运算方法(混合运算及结构化稀疏功能)、GPU高速互联传输(NVLINK及NVIDIA SpectrumX网络)以及半导体工艺制程革新。从Bill Dally这个1小时5分的主题分享中,我们可以看到NVIDIA GPU集群的优化对于生成式AI(GenAI)效率有着显著的提升,这也慢慢衍生到了当前AI大模型面临的一个核心难题——如何通过合理优化基础架构最大程度发挥GPU集群最大的性能表现。
大型AI集群的规模逐年提升,目前主流的都来到了64K甚至更多GPU(如2024年3月Meta公开的第二代AI集群,单集群GPU数量达到了24576张NVIDIA H100)。大型AI集群首先面临的就是网络数据交换问题。巨型的GPU集群需要更低延迟、更高吞吐、更可靠的网络集群来支撑,RoCE虽然可以在已有以太网基础设施上部署升级,在低廉成本的前提下获得低延迟的网络架构,但性能和扩展性层面上,InfiniBand还是略胜一筹。众般皆好,必有一失。InfiniBand高昂的TOC成本、复杂的部署方式却让用户爱不起来。网络解决方案的问题,最终转换为效率与成本的平衡、投入与产出的性价比抉择。
其次是GPU(互联)效率,随着GPU数量规模的升级,不论在GPU主机内支持更多GPU互联,还是在GPU系统间的高速互联,效率都是最为关注的问题。GPU数量的增加,也催生了更高带宽和更低延迟的互联需求。在通用GPU架构中(可参考下图的NVIDIA DGX A100 System),同一主机内GPU之间多采用NVSwitch互联以获得更低延迟和更高的带宽,跨主机的GPU之间多考虑RoCE或InfiniBand互联。当然在实际中也有企业单位采用Intel的CXL(Compute Express Link)来进行集群组网,据公开资料表明其效率低于NVIDIA解决方案,万卡以上的AI集群更多NVIDIA方案部署。从目前的局势来看,主流的卡间互联仅二者可选。此外跨主机的通讯效率大幅低于主机内通讯(NVLink带宽约PICe Gen4的10倍),这也使得大型AI集群更倾向提升单主机规格,支持GPU数量更多和性能更强。在过去20多年里,在摩尔定律的催生下XPU的计算能力增加了9000多倍,然而DRAM内存的带宽仅增加了30倍,内存堆叠封装技术的升级逐步放缓,在此趋势之下单主机GPU性能堆砌的穷途末路必是三墙---内存墙、通讯墙以及存储墙。
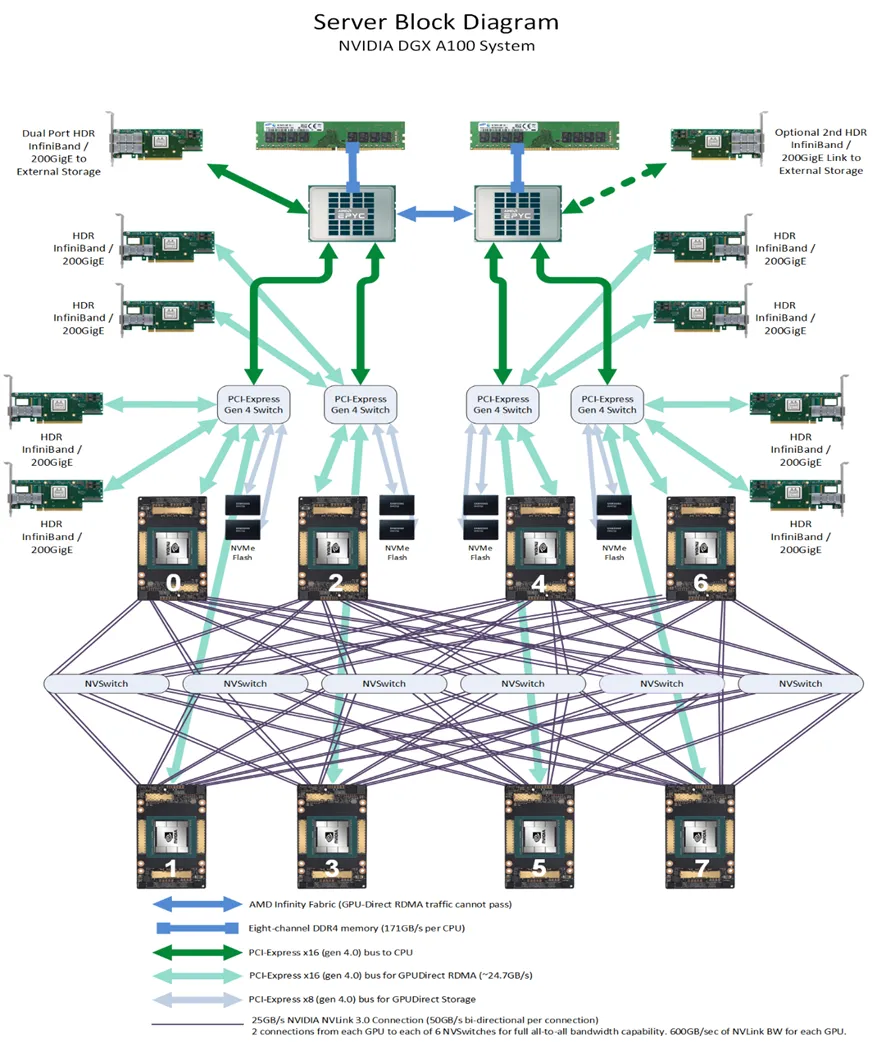
从2024年的风向标来看,AI计算架构正逐渐向分布式和异构计算转变。集群通过将计算任务分散到多个节点,并利用不同类型的加速器(如GPU、TPU、FPGA等)协同工作,可以更好地应对内存、通讯和存储带来的瓶颈。同时,软件层面的优化,如模型并行和数据并行策略,也在不断推进,进一步提升系统的整体性能和效率,Meta公开的第二代AI集群便是其中的一个事实印证。
对于国内的用户,AI大模型建设投资的最后一环必然是成本考量。这些成本分为两类:硬件采购成本和技术拥有成本。受制于美国《出口管理条例》,国内企业获得高性能显卡与技术的难度越来越大,当前国内企业HPC领域的芯片制造能力还在培育阶段,与英伟达、超威半导体等国际一线还有很长距离。AI大模型几乎不可能上演一场没有显卡的战斗。然而曾经简单的物料采购,如今对国内核心企业已成为一道难以逾越的鸿沟。在通用AI集群中,英伟达显卡和NVLINK往往组合应用,其产品技术支撑占据了半壁江山,可替代性选择暂无二致。也正式借着AI这股强心剂,2024年2月16日英伟达一举击败谷歌和亚马逊成为全球TOP4市值最高的公司,整体市值年度环比222.22%的涨幅。
与英伟达欣欣向荣之势截然相反的是国内的AI境况。2024年5月8日,美国众议院提出了“加强海外关键出口国家框架法案”(ENFORCE法案),加强管制AI模型出口,甚至Llama这样的开源模型也在出口管制之内。回顾过往,自2018年起,美国便开始陆续对中国等特定国家实施更为严格的人工智能软件和硬件出口管制并层层升级。针对AI领域的围剿层层加码,很难令人相信这仅是大国博弈,而不是端到端的技术封锁。曾经高喊Freedom的国度,也并不Free。
俗话说得好,雄关漫道真如铁,而今迈步从头越。近年来,国内AI企业在面临重重挑战的情况下,依然展现出顽强的创新精神和技术突破。尽管在技术积累和产业生态方面起步较晚,但凭借政策支持、资本投入、市场需求的强劲推动,中国的AI基础设施建设正在迅速崛起。
以华为的Atlas 900为例,Atlas 900集群的持续迭代体现了国产AI硬件的飞速进步。Atlas 900搭载的Ascend 910B芯片,在AI训练场景中的表现已经能够媲美NVIDIA的A100和A800,尽管在HCCS(Huawei Cache Coherence System)与NVLINK带宽性能方面还存在差距,但其计算能力和效率已经达到了国际领先水平。当然华为的Atlas多以集群形式整体交付,几乎很少存在定制,性能至上的同时少了一点灵活。
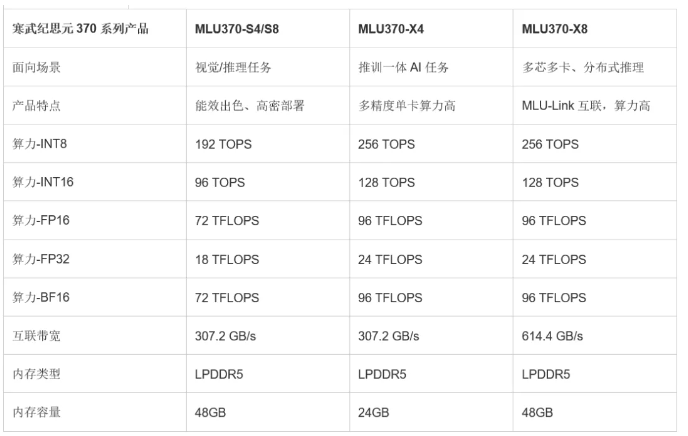
与华为Ascend系列走ASIC线路一致,另一家最具代表性的国产AI芯片厂商也值得说道——寒武纪。凭借着持续高强度的投资研发,寒武纪逐步扭亏奔盈,构建了智能加速卡、智能加速系统、智能边缘计算模组、终端智能处理器IP以及软件开发平台等产品线,在智能加速的细分场景,通过产品的灵活组合打造优异的竞争力,满足市场的多样性需求,规避了ASIC可编程性不足的劣势。其高端智能加速卡思元370系列采用7nm TSMC制程工艺,基于自研的MLUarch3(Machine Learning Unit)架构,支持LPDDR5内存,搭载MLU-Link多芯互联技术。其中基于双芯思元370打造的MLU370-X8整合了两倍于标准思元370的内存、编解码资源,借助MLU-Link多芯互联技术,每张加速卡可获得200GB/s的吞吐性能,胜任多芯多卡训练和分布式推理任务。
有别于华为Ascend、寒武纪思元,海光则走授权+创新的模式搭上快车,并同时兼容了广泛使用的“类CUDA”环境,另辟蹊径,这种战略使得海光在激烈的市场竞争中占据了一席之地,既能满足国内市场的需求,又具备国际竞争力。
国产AI芯片在算力指标上的追赶和突破已不再是梦想,而是一步一步的照进现实。
在数据交换层面,国内互联网三巨头——阿里巴巴、腾讯和字节跳动同样出色,推出了自研的旗舰级51.2T高性能交换机。阿里的“白虎”交换机、腾讯的TCS9500交换机以及字节跳动的B5020交换机已经成为全球旗舰级51.2T高性能交换机网络性能的标杆。它们不仅在数据传输速度和稳定性方面具备卓越的表现,还在定制化和场景优化上具有明显优势,这些创新为国内AI集群提供了强大的网络支持。
此外,国内AI基础设施的崛起还离不开软件生态的繁荣。飞桨(PaddlePaddle)、MindSpore等国产深度学习框架不断更新迭代,推动了AI应用的普及和技术的进步。这些框架不仅适配了本地硬件,还在性能优化、易用性和社区支持方面取得了长足的进展,为AI开发者提供了有力的工具支持。
总而言之,尽管国内AI基础设施的发展还面临诸多挑战,如起步晚、技术积累不足、生态体系不完善等,但在企业的自主创新和市场需求的推动下,中国的AI产业正以稳健的步伐向前迈进。希望这次不再是武汉弘芯事件的延续,而是国产制造及企业科技的觉醒。未来,随着更多技术突破和产业协同,相信国产AI基础设施有望在全球范围内成为人工智能发展的新的动力,这将不仅是一部发展史,更是一部自主创新崛起的抗争史。
