本文来自与非网eefocus,作者/张慧娟。
从1964年第一台计算机系统IBM 360引入CPU,迄今约60年,不论是PC、台式电脑主机,还是大型商用主机,CPU一直是计算机工业发展史上的主角。然而,随着AI应用来临,加速计算盛行,GPU和各类AI计算芯片崛起,CPU遭遇前所未有的挑战。
在加速计算的世界,CPU落伍了吗?特别是随着生成式AI席卷业界,算力需求暴增,CPU中央处理器的地位是否还如其名?
“CPU扩张的时代已结束”
黄仁勋就明确表达过,加速计算和人工智能重塑了计算机行业,CPU扩张的时代已经结束了。当下需持续提升运算能力的数据中心需要的CPU越来越少,需要的GPU越来越多,我们已经到达了生成式AI的引爆点。
在他看来,全球价值1万亿美元的数据中心基本上都在使用60年前发明的计算模式,而现在,计算已经从根本上改变,如果你明年再买一大堆CPU,计算吞吐量仍难以增加,必须使用加速计算平台去处理。
他指出了CPU通用计算和加速计算的根本区别:尽管CPU如此灵活,基于高级编程语言和编译器,几乎任何人都能写出相当好的程序,但是它的持续扩展能力和性能提升已经结束。加速计算则是个全栈问题,必须从上到下和从下到上重新设计一切,包括芯片、系统、系统软件、新的算法优化以及新的应用等,还需要针对不同领域进行不同的堆栈,而这些堆栈一旦建立起来,就会彰显出加速计算的惊人之处。
不过,换一个角度来看,GPU尽管性能强悍,但通常只能执行深度学习这样的特定应用,它还需要CPU的协助,来进行数据的搬运、控制,以及一系列的预处理和后处理任务。而CPU具有独立运算能力,可以独立运行操作系统和应用程序。如果说绝对点,一台计算机可以只有一个CPU,但是不能只有一个GPU。
也正是由于CPU的不可替代性,黄仁勋虽然预判了CPU暴力扩张的时代结束,但另一方面,却曾试图斥巨资收购Arm,以补齐生态短板。并且,英伟达专门面向数据中心推出基于Arm Neoverse内核的Grace CPU,来满足新时代数据中心的性能和效率需求。
CPU不会被完全取代,我们只是来到了新计算时代的临界点。
“始终相信CPU跑AI推理有价值,
也是极其普遍的”
数据中心在AI时代的重要性不言而喻,多年来,英特尔至强处理器在数据中心一直扮演着重要角色。当前,英特尔至强处理器该如何应对AI的趋势和挑战?如何应对加速计算的冲击?
英特尔资深院士、至强首席架构师Ronak Singhal告诉<与非网>,“AI的发生不仅在各类加速器上,更在我们‘老生常谈’的CPU上。实际上,眼下大部分的推理工作都是在CPU上运行的。我们始终相信CPU上的推理是非常有价值的,也是极其普遍的。为了让其在CPU上运行,我们需要继续讨论‘加速’。我们一直在探索,如何去提高CPU的能力,使它始终是运行这些推理工作负载的最佳载体。”
他补充,根据当前所观察到的算法方向以及实际案例来看,在CPU上运行AI工作负载拥有显著优势,包括更低的延迟以及更高的能效,比如避免在CPU和加速器之间来回移动数据,可以极大地降低能源消耗,这也是CPU的一个显著优势。
根据英特尔方面提供的数据,目前25%在售的至强被用于AI工作负载。其中,很大一部分用于推理,一小部分用于训练。此外,许多至强产品还用于在训练或推理之前的一些工作,如数据准备(包括为至强和GPU提供数据)。
英特尔副总裁、至强产品和解决方案事业部总经理Lisa Spelman表示,为满足AI工作负载的需求,至强已经具备诸多加速器和专业功能,且这些日渐成为至强越来越重要的方向。在海量数据、复杂数据处理等需求下,能源效率成为至强转变设计的关键因素。将于明年推出的第六代至强就引入了新的体系结构:Granite Rapids(性能核/P-core产品)和Sierra Forest(能效核/E-core产品),有望进一步提升算力和效率。
Granite Rapids的产品升级有两个要点:一是如何增强算力。其中最重要的是在第四代至强基础上增加了核数,以及继续提高能效。因为进行大量AI矩阵计算时,耗电量会大幅提升,Granite Rapids通过内置的加速器能够为目标工作负载提供显著的性能和效率提升。二是内存带宽。部分AI工作负载以计算为核心,因此将受到核数和能效的影响。还有部分大语言模型,需要处理包括计算、存储等AI工作负载,因此对内存带宽提出了要求。
与Granite Rapids相比,Sierra Forest的核心则更节能,且面积较小,因此,可以在相同功耗下进行扩展、并增加核数,最高可达288核。
对于云服务提供商来说,将尽可能多的用户整合到一个系统上,能够帮助他们减少所需的系统数量,从而降低TCO,这时就可以选择大核数的CPU(Sierra Forest);如果他们需要每个核心拥有最佳性能,他们则可以选择Granite Rapids。
值得注意的是,chiplet、先进封装、最新的内存技术等,在这两款产品中都发挥了重要作用。从下图可知,顶部和底部的I/O chiplet设计,包括PCIe、CXL等。这些功能在Sierra Forest和Granite Rapids之中都很常见。可以根据实际需求,采用更多或更少的chiplet,来扩大或减少核心数量。chiplet的方式既实现了构建芯片的灵活性,同时也有助于提升制造能力。
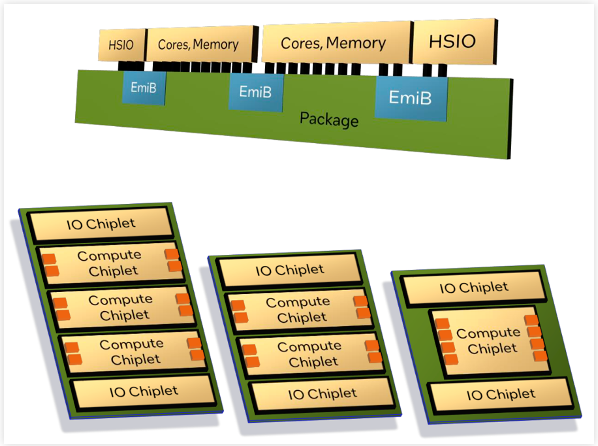
此外,EmiB封装(英特尔的2.5D先进封装技术)也发挥了重大作用。通过EmiB封装,多个独立的计算chiplet和I/O chiplet,在单一芯片中进行了集成,使得芯片结构更为灵活,实现了通用IP、固件、操作系统、平台的有机整体。
除了数据中心,客户端处理器AI方面,英特尔的酷睿Ultra处理器也将首次集成NPU,用于在PC上实现AI加速和本地推理体验。
“AI处于早期快速发展阶段,
不相信护城河”
面对AI的冲击,苏姿丰表示,“对于人工智能,尤其是生成式人工智能如何进入市场,我们还处于起步阶段。我认为我们谈论的是一个10年的周期,而不是‘未来两到四个季度你能生产多少GPU’”。她表示,人工智能发展太快,不相信护城河。
数据中心被AMD作为首要的战略重点。
由于数据中心应用端的算力需求仍在不断增加,而chiplet设计有利于堆算力。AMD在chiplet技术已经享有先发优势,在2019年推出的Zen2架构中,AMD就采用了chiplet设计,使用8块CPU芯片实现64核,是当时英特尔性能最佳处理器的两倍。
去年发布的基于Zen4架构的霄龙处理器,具有96个核心192个线程。而最新的代号为Bergamo的霄龙处理器,采用Zen4c架构,将会搭载128个核心256个线程。Zen4c是AMD专门为云计算场景打造的一款CPU核心,与Zen4架构保持相同的IPC性能和ISA指令集,通过设计优化,使得核心面积缩小,功耗效率提升。这也意味着最新霄龙处理器的核心密度优势,将可以使云服务提供商能够支持超过两倍的服务器实例数量。
在前不久的AMD数据中心和AI首映式中,AMD对比了霄龙EPYC 9654和Intel至强Xeon 8490H的性能,EPYC 9654比Xeon 8490H高80%,Java编译性能高70%,云计算性能(整数)高80%。苏姿丰称,AMD的Epyc在前10名最快的超级计算机中的占据了5台,包括Frontier,这是第一台使用惠普企业硬件构建的百亿亿次计算计算机。
目前,AMD的服务器CPU份额也不断提高,从2017年第四季度的0.8%到2023年第一季度的18%。预计2024年份额达到20%,2027年份额达到25%。
除了服务器CPU,AMD在笔记本电脑CPU也在大刀阔斧地引入AI,锐龙7040系列通过集成AI引擎,能够帮助用户加速多任务处理,提高生产力和效率。据AMD官方说明,锐龙AI引擎的峰值算力可以达到10 TOPS,能够应对日常的AI推理负载设计,相较于外置AI运算芯片,可实现毫瓦级的低功耗AI运算,助力实现本地化的AI运算。
CPU加速AI,尚能战否?
提到AI加速,第一反应通常是强大的GPU或专用的AI加速芯片,但CPU通过内置AI计算,优化底层指令集、矩阵运算加速库、神经网络加速库等方式,在AI推理领域表现出了当仁不让的态势。那么,CPU加速AI推理具体有哪些优势?
英特尔方面表示,经过多年的发展,CPU加速推理过程性价比更高。例如至强可扩展处理器的强大算力可以极大提高AI推理效率,并兼顾成本与安全性。在指令集方面,CPU指令集是计算机能力的核心部分,英特尔的AVX-512指令集通过提升单条指令的计算数量,从而可提升CPU的矩阵运算效率。并且在加速训练环节,DL Boost把对低精度数据格式的操作指令融入到了AVX-512指令集中,即AVX-512_VNNI(矢量神经网络指令)和AVX-512_BF16(bfloat16),分别提供对INT8(主要用于量化推理)和BF16(兼顾推理和训练)的支持。
例如在企业落地AI模型的场景中,CPU服务器部署已经非常普遍,而大多数AI实际要求的是并发量,对推理速度没有特别高的要求,并且在制造业、图像等行业,模型也不会太庞大,这种情况就适合使用CPU作为计算设备。
此外,学术界正在研究轻量级神经网络,目标是使用较少的参数和较低的算力达到同样性能与效果。在这一情况下,用CPU训练轻量级神经网络被认为可能是一个性价比较高的选项,因为相对GPU,CPU一方面减少了数据的反复转移,训练更高效;并且面对轻量神经网络的训练工作,CPU性能已足够,且成本比GPU大幅降低。
写在最后
传统CPU在处理大规模数据和复杂算法时显现出了性能瓶颈,随着AI发展和应用场景的继续扩大,需要更强大的计算能力和存储能力等支持。因此,传统CPU架构不得不引入AI,以适应市场需求。
两大CPU巨头激战正酣,已经面向云边端场景全面引入AI,通过优化架构、提高能效等措施,提高CPU性能和效率。就连GPU巨头英伟达,也开始面向AI数据中心,推出专有的CPU。
AI时代,CPU作为计算机的核心部件,在计算机系统中的地位仍有其不可替代性,也有巨大的想象空间。试想,随着AI的普及,如果未来每个工作负载都嵌入AI,那么是否意味着每次运行AI工作负载时,都离不开CPU?选择AI,拥抱AI,成为AI,是CPU在新时代的宿命。
