本文来自微信公众号“农业品牌联盟”,作者/盟主。
近年来,人工智能在农业领域的应用取得了显著进展,但仍面临诸如模型数据收集标记困难、模型泛化能力弱等挑战。大模型技术作为近期人工智能领域新的热点技术,已在多个行业的垂直领域中展现出了良好性能,尤其在复杂关联表示、模型泛化、多模态信息处理等方面较传统机器学习方法有着较大优势。
[进展]本文首先阐述了大模型的基本概念和核心技术方法,展示了在参数规模扩大与自监督训练下,模型通用能力与下游适应能力的显著提升。随后,分析了大模型在农业领域应用的主要场景;按照语言大模型、视觉大模型和多模态大模型三大类,在阐述模型发展的同时重点介绍在农业领域的应用现状,展示了大模型在农业上取得的研究进展。
[结论/展望]对农业大模型数据集少而分散、模型部署难度大、农业应用场景复杂等困难提出见解,展望了农业大模型未来的发展重点方向。预计大模型将在未来提供全面综合的农业决策系统,并为公众提供专业优质的农业服务。
引言
大模型(Big Models)[1],或称基础模型(Foundation Models)[2],指经过在大规模数据上训练,具有庞大参数量的深度神经网络模型。这些模型通常基于Transformer[3]架构,通过自监督的方法从大量数据中进行学习,不仅拥有卓越的通用能力,也可以适应不同的下游任务。通过扩展,模型在多个领域展示出强大能力的同时,甚至可以涌现出的新能力。例如基于GPT(Generative Pre-trained Transformer)[4]系列技术的ChatGPT对话机器人,可以经过一定的提示词,在如机器翻译、情感分析、文本摘要等大量的自然语言处理任务中表现出色,亦可以推理小模型无法处理的复杂逻辑。
大模型一般使用自监督(Self-supervised)的方式进行大规模的训练,然后将模型应用于不同的下游任务。自监督的学习方式摆脱了对大量人工标记的依赖。通过扩展模型的规模与训练量,模型的任务范围与性能均能有显著提高,同时微调(Fine-tuning)也可以在特定任务上利用少量数据快速提升模型能力。在大模型中,以语言大模型(Large Language Models,LLMs)[5]为代表性成果,其可以通过一定的提示词完成广泛的文本生成任务,展现出强大的模型泛化能力。大模型也包括视觉大模型(Large Vision Models,LVMs)与多模态大模型(Large Multi-modal Models,LMMs)等。
现代农业的迅猛发展与人工智能技术进步密切相关,特别是深度学习的突破性进展对农业产生了深远影响。深度学习强大的特征学习与数据处理等能力,使其在杂草控制、作物病虫害检测、畜牧业管理以及农业遥感等领域均有广泛应用。然而,这些方法大多使用监督学习,依赖于特定的高质量人工标注数据。收集和标注这类数据集不仅耗时、耗资巨大,且模型迁移到其他任务的能力有限,限制了数据规模与模型的发展。因此,寻找能够跨应用领域通用的模型和技术,减少对大规模数据标记的新方法,扩展深度学习框架的通用性,是推动农业等领域进步的重要挑战。
农业大模型(Agricultural Big Models)是为克服上述困难的一次重大尝试,为解决农业领域数据较少且分散的现状提供了方案,同时其广泛的任务迁移能力也得到了多个农业子领域的关注。图1介绍了大模型的构建流程,包含使用异构数据训练模型,对模型微调提升能力,以及使用外部系统增强生成能力等;最终,模型可以用于多种农业综合服务中,提供强大而全面的农业问题解决方案。
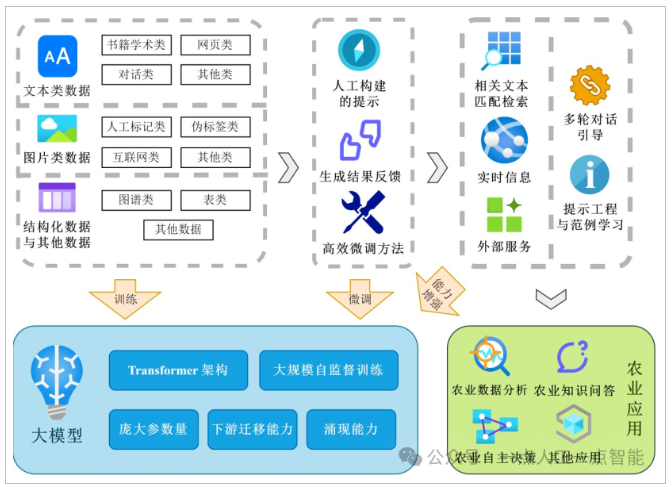
图1农业大模型的构建流程与应用[6,7]
为梳理大模型的农业应用现状,探讨大模型的农业应用潜力,本文首先介绍了大模型关键技术;其次分析了大模型在农业领域可能的应用场景,分别介绍语言大模型、视觉大模型和多模态大模型三种常见大模型及其农业应用案例,展示模型在农业领域的影响。最后,阐述大模型在农业领域发展面临的挑战,并给出农业大模型的发展思路。
大模型关键技术与特性
大模型依赖于诸多技术支撑,也具有区别于其他人工智能模型的特性。Transformer架构是当今众多大模型的基础,使大模型能够有效处理大规模的数据并扩展模型规模[3],扩展定理则指导大模型进行有限预算的最优开发,大规模的自监督学习使模型在无需人工监督的情况下扩展训练规模来提升能力。同时,大模型中新产生的涌现能力(Emergent abilities)[8],是其区别于其他小规模模型的重要特征。
1.1 Transformer模型的产生与核心原理
Transformer架构的设计核心是一种简单高效的自注意力(Self-attention)机制,通过计算序列内元素间的相互关注度分数,为各元素赋予差异化的重要性权重。这一设计使得模型能够在处理序列数据时,动态地集中处理序列中的关键信息,并能够覆盖序列中任意位置的数据元素,有效捕捉长程依赖关系。这种机制使得模型能够方便地扩展,不会因此在模型推理时丢失细节。此外,Transformer模型的架构允许并行化计算,模型在参数规模较大时训练效率有了显著提升。这些特性促使其在大模型领域具有广泛应用。
Transformer推动了自然语言处理领域的一系列重大进展。BERT(Bidirectional Encoder Representations from Transformers)[9]、GPT等基于Transformer架构的预训练语言模型相继产生,并在文本翻译等子领域展示出卓越的性能。
GPT使用了Transformer中的解码器设计,允许文本正向输入,并通过预测文本序列中的下一词来进行训练,使模型能够理解并生成连贯的文本内容。BERT则使用双向Transformer编码器架构,能够考虑到给定单词在上下文中的前后信息,实现同时从正向和反向与对文本的深入理解,显著提升了模型对语义的把握能力。同时,BERT通过在掩码语言建模(Masked Language Modeling)与下一句预测(Next Sentence Prediction),学习到复杂的语境关系。
随着模型的进一步扩大,例如GPT-3[10]、LLaMa(Large Language Model Meta AI)[11]等语言大模型的开发,将模型能力推升至新的高度。同时,Transformer架构的影响也扩展到了其他的人工智能子领域,如计算机视觉领域的代表模型ViT(Vision Transformer)[12],通过将图像分割成多个小块并应用Transformer架构处理,打破了传统依赖卷积神经网络(Convolutional Neural Networks,CNNs)的图像处理范式。
进一步地,Caron等[13]将ViT与自监督学习结合,提出了DINO(Self-distillation with No Labels)框架,在自监督条件下也能学习到图像中的深层语义特征,为构造视觉大模型奠定了一定的理论基础。
1.2大模型的扩展定理
Transformer架构允许模型进行大规模的堆叠,而对模型规模、数据规模与计算量的扩展,可以大幅提高模型能力。尤其在语言大模型领域,开展了一些对扩展的定量研究。
语言大模型发展出两个代表性的法则[7]:KM(Kaplan-McCandlish)法则[14]与Chinchilla法则[15]。
KM法则是通过拟合神经语言模型的性能在不同模型规模(N)、数据集规模(D),以及训练计算量(C)三种变量的表现提出了一种性能随这三种要素扩展而提升的定量描述;Chinchilla法则提出了另一种形式来指导语言大模型进行最优计算量的训练,认为模型大小与数据量应以同比增加来在一定预算下取得最优模型。KM法则可以表示为公式(1)~公式(3),Chinchilla法则表示为公式(4)~公式(6)。
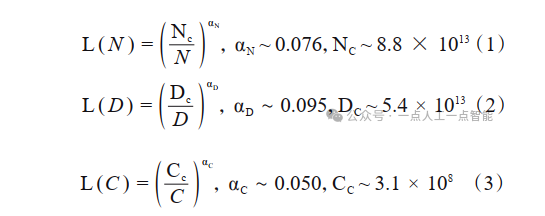
式中:图片为nats表示下的交叉熵损失。
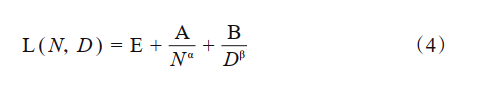
式中:E=1.69,A=406.4,B=410.7,α=0.34,β=0.28。在𝐶≈6𝑁𝐷的条件下,将计算预算分配给模型规模与数据量的最优解,为公式(5)和公式(6)。
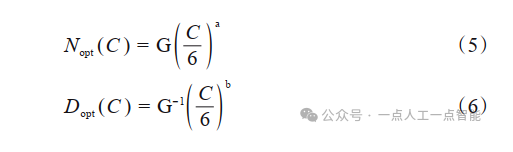
式中:图片,G为基于A、B、α与β计算的扩展系数。
1.3大规模自监督学习
大模型的能力依赖于大规模的训练。早期的深度学习模型基于监督训练,依赖于对数据的人工标注。这种方式耗时耗力,限制了模型的训练规模。相对地,自监督学习的核心思想是利用数据本身自动化地产生对应的监督信号,使模型能够在未经人工标注的数据上,学习到有用的特征,进行自我监督。通过减少或避免对人工的依赖,使得在更广泛、更大规模的数据集上进行训练成为可能。
在大模型领域,自监督学习主要采用生成式学习与对比学习两种策略。生成式学习,也称预测学习,旨在通过模型生成与训练数据相似的数据,深入挖掘数据的内在结构及生成过程的潜在因素。
生成式学习在语言模型中应用广泛,如BERT模型通过掩码语言建模与下一句预测进行训练,前者旨在预测文本中挖空的词汇,后者则是从候选句子中挑选出最合适作为文本下文的句子。对比学习则广泛地应用到计算机视觉领域中,如SimCLR(Simple Framework for Contrastive Learning of Visual Representations)[16]架构,将同一批图片采用不同方式增强后进行编码,最大化来自相同图片的编码的相似性,以此学习对图片的特征表示。
同时,进行大规模自监督学习的可扩展性训练技术也至关重要[7],可以包括如使用3D并行技术(数据并行、流水线并行、张量并行等),将计算分散到多个GPU上进行训练,或使用零冗余优化器(Zero Redundancy Optimizer,ZeRO)[17]技术,解决数据在多GPU部署后的冗余问题,以及采用混合精度训练,减少计算量与数据传输开销。这些技术结合计算机硬件的持续进步,为大模型的规模扩展和训练效率提供了坚实的算力支持。
1.4大模型通用能力与适应微调
经过预训练,大模型具有解决广泛任务的通用能力。通过一定的提示(Prompts),大模型能够执行不同的具体任务。如ChatGPT可基于语言等提示,执行如文本翻译、开放领域问答、文本摘要、文本生成等多种自然语言处理上的具体任务;Meta公司开发的SAM(Segment Anything Model)[18]允许使用文本提示与可视化的分割范围提示,对照片中的具体物体进行实例分割。
大模型可以通过微调适配到特定的目标上。如在语言大模型上可以进行指令微调(Instruction tuning)与对齐微调(Alignment tuning)两种微调方法[7]。
前者通过构建人工参与的格式化的指令,包含任务描述、输入输出以及可选的少量示例等,监督大模型对特定的工作进行调节,提升其完成具体目标的能力;后者则着重于将人类的价值取向与偏好等对齐于语言大模型,防止其生成有害的、虚假的、带有偏见的等不符合人类期望的内容,一般采用基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)[19]方法,通过收集的人类反馈进行训练奖励,有监督地调节模型。视觉大模型亦可通过微调工作,来提高模型在特定任务,如开放世界物体检测中的性能,也可提高模型的某种能力,如视觉定位(Visual Grounding)等[6]。
对模型进行全参数微调需要大量计算资源。而对模型添加少量额外结构,就能使模型在仅调节这些结构后快速适应下游任务。这种参数高效微调[7]的方法包括适配器微调(Adapter Tuning)、前缀微调(Prefix tuning)、低秩适应(Low-Rank Adaption,LoRA)[20]微调以及提示微调(Prompt tuning)等。
适应器微调通过在模型的多头注意力层与前馈层之间插入小型的神经网络模块来实现;前缀微调则是向模型的输入添加一系列固定的向量(即前缀)来引导模型输出;而LoRA微调通过在Transformer层中添加低秩矩阵来模拟模型内部较低的本征维度,从而使用少量参数进行快速学习。此外,提示微调则通过自动调整添加到输入上的提示模板来激发模型在特定任务上的性能。这些方法的出现显著降低了微调的计算量,促进了大模型在多个领域的推广。
1.5涌现能力
语言大模型与一般预训练语言模型的主要区别之一是涌现出在较小模型上难以出现的能力,即涌现能力[8]。将模型的规模提升到一定程度,其能够展现出解决复杂的问题的新能力。其中有三种典型能力[7]:上下文学习(In-Context Learning)、指令遵循,以及逐步推理。
上下文学习是指模型能够按照一定的自然语言指令以及任务演示,对测试样例进行补全来生成答案,不需要对模型参数进行更新。指令遵循是指模型在混合多任务数据集上进行微调后,在格式相同但未曾见过的任务中具有良好表现,即便没有显式的示例依然可以遵循新的命令。逐步推理则强调语言大模型可以解决涉及多个推理步骤的复杂任务,通过思维链(Chain of Thought)[21]等方式生成中间的推理步骤,最后生成最终的答案。
大模型分类及在农业应用分析
2.1大模型农业应用主要场景
大模型在农业领域展出广泛而强大的应用潜力,涉及农业的多个子领域。
在种植业领域,大模型可以对植株及根茎果实等器官进行识别分析,对病虫害、杂草等进行识别与定位等;在畜牧业领域,大模型可以对家畜进行个体识别与追踪,以及动物行为分析、动物产品分析等。
对于农业上的通用领域,大模型可以对农业遥感图像进行划分,分析土地用途、作物种类等;也可以用于农业文本的分类与信息提取等。对于综合化的农业应用,大模型可以用作农业智能问答系统,对多模态信息进行全面分析;而在未来,大模型可以接入自动化农机中指导其操作,亦可以作为决策核心对多种农业任务进行无人化管理。
大模型与农业深度融合是未来的发展趋势,甚至会对农业产生变革性的影响。图2展示了当前以及未来农业大模型的几种应用方向。
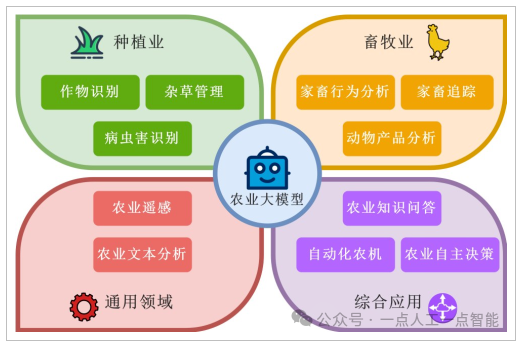
图2农业大模型主要应用场景
发展并普及基于大模型的农业服务,不仅可以加强用户反馈信息和数据集的丰富性,进一步优化模型,还能推动农业智能化的广泛实施。此外,推广大模型在农业领域的应用,能够为用户提供更加个性化、全面而便捷的综合服务。其能够减少对人力的依赖,促进农业知识的积累与传播,并为农户与企业提供更加科学、可靠和高效的农业支持系统,推动农业产业的持续发展和创新。
2.2农业大模型分类
2.2.1语言大模型
语言建模(Language Modeling)是人工智能在语言能力上的重要体现,其旨在通过对词序列进行概率建模,预测未来或内部缺失的文本概率[7]。
近年来,语言大模型通过大规模的语言建模,将人工智能在自然语言处理上的能力推上了一个新的高度,以GPT系列为代表的语言大模型得以产生。
GPT-2[22]采用无监督语言建模的方法,对多任务求解进行概率建模,将多种自然语言处理任务转换为特殊的词序列预测问题;通过在更多更广泛的语言文本上训练,GPT-2可以在未针对部分特定任务训练的情况下,依然在这些任务上表现出色,展现出“零样本学习”(Zero-Shot Learning)的能力。
GPT-3[10]在继续扩展数据集与模型规模的同时引入更多的预训练方法,将模型能力推升到新的高度;通过少量样本即可显著提升在下游任务上的能力,GPT-3展现出了其少样本学习(Few-Shot Learning)的能力。此外,InstructGPT[19]探索了GPT-3对基于人类反馈的强化学习的引入,将模型对齐于人类的价值偏好,旨在生成有用、可信且无害的内容。
GPT-4[23]在展现出更加先进语言能力的同时,亦可进行复杂的图像解读与生成,展现了多模态能力。基于GPT-3.5与GPT-4的ChatGPT的出现引起了社会对语言大模型的关注,让人们重新思考通用人工智能(Artificial General Intelligence,AGI)的可能性,也促进了多种大模型的出现。
BERT与GPT的设计思想在语言大模型中得以沿用,催生出不同的模型架构。
目前有三种主要的架构[7],第一种为编码器-解码器架构(Encoder-Decoder Architecture),利用编码器理解输入序列,再由解码器生成目标序列。编码器使用多个堆叠的多头自注意力层对序列编码,捕捉其中复杂的内部关系,解码器则使用交叉注意(Cross-Attention)并自回归地生成目标序列。基于此项原理的预训练语言模型大都基于BERT进行进一步开发,比较知名的有BART[24]和T5[25]等,而基于此架构的语言大模型(如Flan-T5[26]等)数量较少。
第二种是因果解码器(Causal Decoder Architecture),沿用GPT模型的思想,仅含有一个单向的解码器,因而输入的序列片段只关注自身与之前的片段,目前被大部分的语言大模型使用。开源的BLOOM(Big Science Large Open-Science Open-Access Multilingual Language Model)[27]、Llama2[28]等模型均是基于这种架构开发的。
第三种是前缀解码器架构(Prefix Decoder Architecture),使用了编码器-解码器架构的部分思想,改进了因果解码器,使得前缀序列片段可以执行双向的注意力机制,并保持生成的序列使用单向注意力机制。采用这种架构的语言大模型有GLM-130B[29]等。目前,语言大模型已经在农业领域初步应用,其中包括构建专用农业模型、研究已有模型的农业能力,以及综合使用模型与外部系统等研究方向。
1)建立农业专用语言模型。
在大规模的语言模型出现前,一些较小规模的语言模型就已经在农业领域得以应用。如Rezayi等[30]提出了用于匹配食物与营养成分的AgriBERT模型。该模型使用了BERT语言模型结构,在基于大量学术期刊的语料数据集上进行了从零开始的预训练,并通过农业专业知识图谱增强答案来微调。结果表明,使用专用语料数据集进行训练后,模型匹配能力的提升非常显著,而专业知识图谱的影响较为复杂:模型能更好地推测出食物中最多的营养成分,但其推测出食物完整营养成分的能力会下降。这项工作为语言模型与知识图谱在农业领域的结合提供了一定指导。
目前,语言大模型的文本分析与生成能力在多种农业任务中得以应用,其可以对农业文本进行信息抽取与分类,为农业问题提出解答,提供全面的智慧农业服务。农业领域专用语言大模型的训练还在进行当中,如Yang等[31]基于预先训练的Llama2-7B与Llama2-13B模型,通过在大量专业文本上的继续预训练与指示微调,训练出适用于植物科学领域的PLLaMa系列模型。在测试中,基于Llama2-13B的PLLaMa-13B-Chat在给定的多选问题上可以达到60%的准确率,同时在零样本生成测试中也取得了令农业与植物专家满意的结论。由安徽省农业农村厅与科大讯飞构建的“耕耘大模型”,基于星火认知大模型的核心技术,对接海量涉农数据,实现包含农业生产、市场分析,以及政策咨询与政务服务的一站式智慧农业系统。由中国农业大学开发的“神农大模型1.0”,使用多种农业学科的海量数据进行训练,利用知识图谱与向量数据库提供相关文本来缓解模型幻觉,具有农业知识问答、农业文本摘要生成、农业生产决策等多种能力,是中国农业人工智能领域新的进展。
2)探究与增强已有语言大模型的农业能力。
不经过额外的大规模预训练,探究已有语言大模型在农业领域的应用能力也取得了一定成果。ChatAgri[32]是一种使用ChatGPT(基于GPT-3.5)的多语言农业文本分类技术,总共包含有四种处理方向。一是使用人工书写的指令来让ChatGPT筛选文本;二是用ChatGPT构建出多个问题后再使其基于问题筛选文本;三是让ChatGPT判断当前文本与已有文本的相似度来分类;四是在方向三中额外引入分步推理提升正确性。分类后的句子会继续以固定的规则或与各类别的典型答案进行相似匹配两种方式进一步对齐与归并。ChatAgri使用零样本学习即可超出其他模型,展现了语言大模型在农业文本分类上的卓越能力。
语言大模型的农业问答能力也得到了研究。Silva等[33]基于美国、巴西与印度三地的农业问题,探究了LLaMa2-13B、LLaMa2-70B、GPT-3.5与GPT-4四种模型的农业应用能力。采用检索增强生成(Retrieval-Augmented Generation,RAG)、集成精炼(Ensemble Refinement,ER)与问题背景描述三种方式提高模型的生成能力。GPT-4作为实验的最优模型,其在农业硕士考试的成绩超越人类考生结果,展现出语言大模型超越人类的问答能力,王婷等[34]基于草莓栽培农技知识设计了知识对象识别与知识问答两种下游任务,来探究Baichuan2-13B-Chat、ChatGLM26B等模型的农业能力。使用多种学术数据来源提取与草莓栽培技术相关的知识并进行标注。同时为提升模型性能,该研究在知识对象识别实验中采用LoRA微调,在知识问答实验中采用提示微调与检索增强生成等方法。这项实验为农业大模型的中文问答能力评估提供了初步见解。
语言大模型可以生成高质量的农业信息,但是对于精确到一定地区的问题,可能依然生成一般性回答,与地区的实际情况有所偏差。Balaguer等[35]采用检索增强生成与微调来提升模型在地区具体问题上的回复能力。实验从公开文档中抽取格式化数据,并用模型生成所选文本的相关问题。使用增强的模型回答问题后,问题与答案会由GPT-4统一进行多角度的评估。评估不仅聚焦于问题范围精准度、答案的正确性等,也包括问题的拟人性、答案文本流畅性等多个角度。实验不仅表明两种方式均可显著增强模型能力,且提出了基于大模型的多维度评估机制,为模型的农业能力评价提供了基线。
3)语言大模型与外部系统配合。
语言大模型强大的文本理解与生成能力,使其能够有效地与其他小型人工智能模型等外部系统结合。Qing等[36]设计了一套综合使用语言大模型与计算机视觉模型的病虫害识别系统。该系统依赖YOLO模型[37]来识别植物病害,并提出YOLO的轻量级变体YOLOPC,来识别图片中的植物虫害。识别后的结果会先进行简单的转换,生成文字描述。之后,检测结果与可选的额外信息(如地点等)会合并后传输给GPT-4模型,以产生综合的描述与应对方案。实验结果表明,GPT-4可以有效地生成对病虫害的全面描述并给出相应的解决方案。同时,使用对当前环境的额外描述,以及让GPT-4在生成总结后再进行推理,均对模型能力的提升有较大的帮助。Peng等[38]设计了一套利用语言大模型进行辅助农业文本信息提取的系统。这项系统同时依赖于语言大模型与基于嵌入的检索(Embedded-Based Retrieval,EBR)过滤器。EBR过滤器可以将文本转换为向量并映射到高维空间,以此检测文本片段的相似性,并基于此来提取文本特征。
提取文本的过程总共分为四步。第一步,文本将使用EBR过滤器进行预先切割后,再通过语言大模型进行处理,提取其中的描述性词汇;第二步,语言大模型将上一步中的描述性词汇与相应的类别相匹配,如将“白色”匹配为“颜色”;第三步,语言大模型会从对应的文本中提取主要的实物实体,类似于命名实体识别过程但着重于带有形容的实物;第四步,使用语言大模型将实体与描述进行匹配,并将结果输入EBR过滤器,将同义但不同词的表述进行对齐统一,得到结构化的文本输出。实验采用了GPT3.5-turbo作为语言大模型,并将输出结果经过人工评估,发现这种系统在准确率与召回率上均有良好的表现。这一结果突显了语言大模型在农业文本结构化处理方向上的应用潜力。
语言大模型在农业领域的这些应用展示出其对农业文本强大的理解与生成能力。通过融合相关外部文本、多轮自行判断推理以及模型高效微调,语言大模型的农业能力能够显著增强。未来,使用通用语言大模型并通过外部信息以及少量训练与微调来增强其农业能力的方式会得以进一步推广。这些模型既能作为农业智能问答系统的核心,也可以被整合到其他多样化的系统中,从而提升人工智能在农业领域的应用水平。
2.2.2视觉大模型
计算机视觉领域较早的主要研究范式是基于有监督的深度神经网络训练。ImageNet这种大规模图像分类数据集促使了这一范式的沿用与推广。这种范式下的模型包括AlexNet与ResNet等图片分类模型,YOLO等物体检测模型,以及U-Net等图像语义分割模型。这种有监督的范式限制了视觉模型的泛化性与适用性[2]。将语言模型的相关技术应用于计算机视觉领域,并使用自监督等学习方法,促进了视觉大模型的产生。
Florence[39]模型广泛的视觉能力使其成为视觉大模型领域的重要突破。该模型可以快速适配多种计算机视觉任务,涵盖了图像分类、图像和视频检索、目标物体识别、可视化问答、图像标注、视频内容理解和动作识别等领域。其核心创新之一在于能力的泛化,能够处理从粗粒度(如整体场景)到细粒度(如特定对象)的信息,从静态图像到动态视频的内容等。Florence不仅在常规的视觉任务中展现了高度的适应性和性能,在处理更复杂、多样化的数据类型和任务时也展示了前所未有的识别与分析能力。特别是在迁移学习的应用场景中,无论是在微调、线性探测(Linear Probing)、少量样本迁移(Few-shot Transfer)还是在完全没有先前知识的新图像和新物体的零样本迁移(Zero-shot Transfer)场景中,该模型都能有效地适应并保持高效的性能。
SAM[18]模型将图像分割引入视觉大模型领域,是计算机视觉大模型的重大突破。其能够在多种不同场景中分割出其中不同的物体,表明其对“物体”的理解已上升到高度抽象的层面。SAM在SA-1B这一规模空前的开放数据集上训练,保证了其强大的性能;SAM结构包含图像编码器、提示编码器和掩码解码器三个组件,允许用户使用文本描述与可视化的图像分割范围两种提示来指导模型进行分割处理,通过输出多个有效掩码来处理模棱两可的提示,允许该模型在不同的图像分布和任务中进行零样本迁移学习。图3展示了SAM模型的架构。
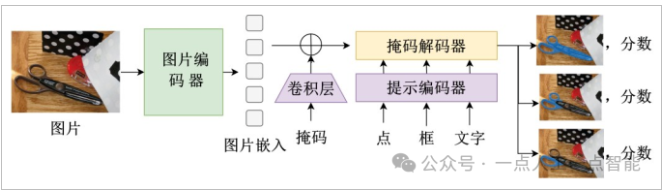
图3 SAM模型架构
作为视觉大模型的代表,SAM模型的分割能力在种植业、畜牧业以及农业遥感等领域得到了体现。
Williams等[40]探究了SAM模型分割土豆植株叶片的能力。首先使用SAM模型在图像上直接进行分割,而后通过颜色检查、去除全植物掩码、形状过滤、剔除含多叶片的掩码四个步骤,构建“叶片专用SAM”推理流程。将该流程与Mask R-CNN模型进行比较,结果表明SAM在使用上述构建步骤后分割效果有所提升,然而依然略弱于基于监督学习的Mask R-CNN。但这一推理流程本身并不需要人工参与,采用零样本分割的SAM对农业领域减少人工标记数据的依赖起到了推动作用。
Carraro等[41]评估了SAM模型对作物与杂草图像生成精确图像分割的潜力。该实验使用作物/杂草田间图像数据集(Crop/Weed Field Image Dataset,CWFID),通过语义分割来区分植被的前景与背景,分割测试采用人工辅助标记与无监督自动标记的两种形式,在不对SAM额外训练的情形下探究其零样本学习能力。结果表明,SAM模型在使用仅少量点或边框进行提示下效果良好,但是在自动标记的情况下会过度分割图像,说明模型需要向农业方向进一步适配。即便如此,该项研究依然为作物与杂草图像识别提供了一种弱监督的可能方法。
Li等[42]提出了一种农业SAM适配器,通过适配器微调的方法提升模型的农业能力,并通过病虫害图像分割探究该适配器的能力。该适配器由少量全连接层配合ReLU激活函数构成,在SAM掩码解码器的多头注意力层后与多层感知器后加入,同时在微调过程中仅训练适配器来使SAM模型快速适应农业任务。通过收集有关咖啡叶疾病和害虫的12种数据集并创建对应识别任务,测试原始SAM模型与添加适配器变种的能力。实验结果表明,添加适配器后SAM在各项任务中的表现均有提升,尤其在识别咖啡叶疾病时平均戴斯系数与平均交并比分数提高约40%,实践了视觉大模型在农业领域中对适配器微调的有效使用,推动了视觉大模型在农业领域的适应与应用。图4为在使用适配器前后SAM模型的病虫害图像分割结果,展示了SAM适配器对分割能力的显著提升。

图4 SAM在使用适配器后的病虫害图像分割实例
Yang等[43]以无笼养鸡为例子,通过多角度的实验探讨了SAM模型在家禽业的应用甚至于养殖业的未来潜力。
主要设计了两种实验,一是比较SAM以及其他先进模型(SegFormer[44]和SETR[45])在普通图像与热源图上的图像分割能力,包含对整只鸡的分割与除尾部外部分的分割,详细探究该情境下SAM的零样本分割能力。二是将YOLOX和ByteTrack模型与SAM模型结合,利用前两者的物体识别与追踪能力,实现对鸡群内单只鸡的详细运动追踪。
实验结果表明,SAM在鸡的整体与部分身体的分割任务上超越了其他先进模型,且上述运动追踪系统达到了实时的处理速度。实验也表明SAM模型在鸡群密度高、设施遮挡,以及鸡的行为与姿势多变的情况下具有一定的局限性,为未来的研究指明了方向。
农业遥感领域侧重于通过遥感图像提取出农用地的多种信息,提升农业数据的准确性和实用性,指导地方农业向精细化、个性化的方向发展。
Gui等[46]探究了SAM模型通过遥感图像在农业用地及城市绿地的划分方面的能力。其使用美国多地的精度为0.5~30 m不等的遥感图像,采用有监督的人工辅助分割以及无监督自动分割两种方法对模型能力进行测试,发现SAM在使用人工标定感兴趣区域(Region of interest,ROI)与非感兴趣区(Uninterested Region)后其准确率可保持90%以上,但无监督分割的准确率则有明显更低,尤其受低分辨率与较大框定范围的影响。由此,Gui等提出几项改进意见,包括使用更多样化的图像扩充训练数据集以扩展SAM模型的能力范围,以及调节模型的超参数来增加SAM在细微差别上的敏感度。
Gurav等[47]探讨了SAM模型在生成作物类型图上的潜力,发现SAM对输入的作物类别不敏感,但可以划分田地。由此,提出利用SAM划分卫星图像的田地轮廓作为作物分类的基础,并使用多种聚类一致性指标(Clustering Consensus Metrics)来评估其图像分割性能。
为进一步提升SAM模型的农业遥感能力,Liu[48]提出了一种基于SAM模型的利用遥感图像划分农田边界的工作流程。该流程采取双阶段的策略,首先初步地将图像进行全景分割,创建整体的耕作地图,随后提取出感兴趣区,以进行更加细致的分割。该研究同时详细阐述了如何从感兴趣区生成提示点并输入SAM模型,以此来指导模型进行细致划分。通过对黑龙江省两处约1 000 km2的试验区进行实验,该方法在总识别率、平均交并比、平均过分割比与平均欠分割比四项指标上的评价均十分出色,通过零样本学习,为解决大规模农田界限精确提取问题,尤其是大规模未标记区域,提供了一种低成本且高效的新途径。
SAM模型也为改进现有遥感数据提供了帮助,如Zhang等[49]提出了一种通过SAM模型提高由美国国家农业统计局开发的农田数据层准确性的方法。该研究利用SAM的零样本泛化能力,从Sentinel-2卫星图像中对农田地块进行划分,在美国主要农业区域,如加利福尼亚中央谷地和美国玉米带上进行实验,提高了农田数据层的精确度。
SAM模型的“分割一切”能力使其在发布的短期内即在农业的多个领域得到充分应用。尽管其在部分特定任务中不及传统人工监督学习模型,但仅通过少量的监督微调,其在农业领域的能力就能够得到显著提升。在未来,随着视觉大模型技术的进步,利用特定提示、少量人工监督训练等方法,这些模型将更加高效地替代传统模型,在农业领域发挥更大作用。
2.2.3多模态大模型
与单一处理文本或图像的模型不同,多模态大模型可以融合语言、图像等多种信息,打破多种信息载体的壁垒。这种模型一般涉及多种信息载体的互相转换与理解,提升机器对世界的理解能力,是通用人工智能出现的必要门槛。
2021年出现的CLIP(Contrastive Language-Image Pre-training)[50]模型是将视觉模型接入文字能力的重要尝试。该模型使用文本编码器与图像编码器,并将两种输出投射到共同的嵌入空间,学习文本与图片在空间内的相似性,以此指导模型通过一定的文字提示对图像进行分类。模型采用对比学习的方法,通过由互联网采集的图像-文本集合,构建对图片的正向和反向描述并进行训练。该模型的创新点在于其出色的零样本学习能力,如能够理解风格不同的图像并提取关键信息;同时,其使用自监督的学习方法,大量减少对人工标注依赖的同时,能够取得与监督学习的深度神经网络ResNet50的相似性能。
由DeepMind开发的Flamingo[51]模型是多模态领域的重要研究成果之一。该模型使用了预先训练的视觉与语言模型,且仅通过训练两者间新的神经网络来让模型学习到多模态能力。通过在大量文本与图片穿插的互联网数据上进行训练,Flamingo可以经过少量样本学习迁移到多种多模态任务上来,是多模态模型在迁移能力上的一大突破。此外,GPT-4作为语言模型亦具有多模态能力,可以对输入的多种图像进行复杂分析,包括图表分析、文字提取、照片内容分析等[23]。
图像与视频生成也是多模态领域的重要研究方向之一。如DALL-E[52]模型作为GPT-3的扩散模型(Diffusion models)变体,可以根据一定的文字描述生成图像。这种模型基于变分自编码器(Variational Autoencoders,VAEs)[53]与Transformer架构相结合,VAE将图像编码为离散潜在表征,Transformer则学习自然语言描述到这些表征的映射,以此指导模型的图像生成能力。DALL-E模型可以在未经训练的文本中生成高质量图像,甚至包括对复杂与高度抽象的概念图像具体描述,表现出零样本学习能力,同时模型可以较精确地控制图像的颜色、形状等细节,展现了出色的图像生成能力。
近期,由OpenAI开发的Sora[54]视频生成模型在GPT与DALL-E的部分技术基础上继续开发。Sora将视频映射为时空碎片(Spacetime Latent Patch),并使用Diffusion Transformer融合文字、图像等提示后生成去噪数据,最终解码为目标视频。Sora在视频保真度上尤为突出,如可以在视角快速移动时保持三维内容一致性,以及保持视频物体的长距离一致性等,并实现了视频生成、融合与扩展等多种功能。
农业领域的知识涉及图像和文字等多种介质,通过多模态模型的方式将知识融合,基于多种异构信息提供知识服务,对农业知识的推广与落地有着很强的现实意义。Cao等[55]提出了一种多模态模型ITLMLP,融合了图像、文字与标签三种输入方式,并将CLIP与SimCLR的部分结构融入模型之中,用于对黄瓜病害进行识别。模型利用图像与文本信息进行对比学习,并与标签信息相结合,在少样本上进行学习。通过与CLIP、SimCLR以及SLIP(Self-Supervision Meets Language-Image Pre-training)[56]模型的对比结果显示,ITLMLP在黄瓜病害识别的多种指标上超出以上三种模型。ITLMLP模型在多种其他植物病害上也有着良好表现,与其他三种模型相比性能更好或有极小差距,展现了该模型的泛化能力。Tan等[5]设计了针对GPT-4的多个基于农业领域图片与提示词的简要实验。其中,第一项实验是基于遥感图像和对应的基本信息(地区、时间等)对农田作物进行识别,结果表明GPT-4在一般图像上表现良好,但在复杂环境会出现错误。第二项实验是通过航空图像(普通图像与近红外(Near-Infrared,NIR)图像)识别作物的养分缺失,实验结果显示GPT-4模型能够分析出图像中养分缺失的特征信息以及对应的图像范围,但需要详细的说明与相关知识来指导其分析。第三项实验是探究GPT-4在植物病虫害与植物表型检测上的能力,包含棉花病虫害检测、杂草识别以及棉苗、棉花花朵与棉铃的计数。该研究中GPT-4在分析较简单图像时表现良好,处理复杂或相似图像时容易产生错误,但其提供的农业知识与建议等较为全面,有一定的借鉴作用。第四项实验旨在将GPT-4应用于家禽业,包含对蛋壳问题、鸡禽行为的分析,以及鸡群计数共三种探究。实验表明GPT-4在蛋壳问题与鸡禽行为的分析上可以提供全面且较为精确的内容,在鸡群计数问题上也可以对图像细节进行归纳,展现出其在家禽管理上的潜力。总的来说,研究结果展示了以GPT-4为代表的高级多模态模型在农业领域的广泛前景,其复杂的图像解读、文本分析,以及生成能力将推动农业知识的普及与个性化农业分析的发展。
多模态模型在农业领域的主要优势之一是能够打破多种农业图像问题与农业知识文本之间的壁垒,通过统一的模型为多种农业问题提供全面的解决方案。将语言大模型与视觉大模型等的能力结合,进行多模态方向的深入开发,进一步提升模型能力,为实现综合化的智慧农业服务提供更为坚实的技术支撑,为农业领域带来更高效、智能的解决方案。
农业大模型发展重点方向
大模型是人工智能领域的技术突破,通过大规模的自监督学习与庞大的参数量,大模型仅通过少量学习样本甚至无样本就可以迁移到大量下游任务中,在多个农业问题上取得了良好成果。将大模型应用于多种农业任务中指导农业发展,使用大模型进行数据分析与决策,是未来的发展趋势,也为智慧农业、精准农业等领域的发展提供了新的方向。目前大模型及其在农业领域的应用尚处于早期阶段,仍需克服一系列挑战,但具有很强的发展潜力。
3.1构建综合且集中的农业数据集
农田环境多变、场景复杂,收集大规模、多样化的数据集存在一定困难。虽然大模型的迁移能力减少了模型对农业数据的需要,但其迁移效果受数据质量的影响较大,确保数据的准确性和一致性至关重要。
目前农业领域的数据集呈现相对较为局限和分散的现状,依然限制了大模型在农业上的广泛应用。尤其是文本数据,大多数现有数据集可能缺少专门针对农业领域设计,例如气候灾害数据等,与农业相关联但并不直接聚焦于农业关键领域。而要构建文本数据,使用网络爬虫既耗时又复杂,依赖于学术期刊等权威数据又可能引发版权问题等。而对于视觉数据集,大多只针对某项农业问题,规模较小且分散。无论是训练还是辅助回答,数据的质量和数量是模型成功的关键因素。因此,建立一个高质量、全面、广泛且开放共享的数据集显得尤为重要。这样的农业数据集不仅需要收集大量的农业数据,也需要采用更加先进的技术对数据进行持续的筛选和整合对齐,以反映农业研究与实践中先进且综合的成果。
3.2减轻模型的训练与部署难度
农业领域涉及的作物种类繁多,不同地区的气候、土壤条件差异显著,通用的大模型难以适应所有场景,需要构建具有地域特色的专用模型或专用模块。而大模型的预训练、微调和部署工作均需要大量的计算能力与存储空间,高度依赖于高性能GPU服务器,且依然需要较长的训练时间。这种需求限制了目前大模型在农业等多个领域的进一步发展。
目前,扩展性训练技术[7]可以减少模型的GPU显存需求并提高模型吞吐量,同时QLoRA[57]与OPTQ[58]等技术允许模型降低参数精度来缩减模型体积,已经得到了广泛应用。此外,大模型自身的优化和发展亦有助于在较小的参数规模上实现或超越更大模型的性能,而硬件的进步也将增强模型在更广泛领域的应用潜力。未来,模型的进一步轻量化和便携化将促进其在农业等领域的普及。
3.3构建基于大模型的农业决策系统
基于复杂文本、图像等信息的分析能力,大模型可以作为农业决策的核心,接入不同来源的各种模块。这些模块可以包括有物联网实时监控设备、其他人工智能模型、公开的即时信息(如天气)等。通过一定的提示,大模型可以整合多种输入来源,并推理出基于实时信息的最优策略。用户可以通过语言交互来获取简单易懂的个性化反馈与建议[59],甚至农业机器人可以在大模型的指导下进行自动化的管理与采收等工作[60]。通过提高模型的泛化性,确保决策模型能够适应不同的农业环境和条件。但是,由于农业大模型更多面向农民等群体,因此农业决策需要更强的模型可解释性,以便农民能够理解和信任模型的输出。此外,还可通过融合多种外部能力与自身知识储备制定出全面可靠的农业方案,来进一步提升农业管理的效率和准确性,甚至为农业领域带来变革。
3.4推动大模型在农业领域的广泛应用
当前,大模型在农业领域的应用仍然主要局限于科研阶段的小规模测试,其在公共服务方面的应用明显不足。发展和推广农业大模型正面临着涉及技术、政策、资金和农民接受能力等多个方面。此外,如何将大模型技术转化为可落地应用的具体产品和服务,以及如何通过这些产品和服务产生商业价值,是农业大模型发展另一个挑战。这些均需要政府、企业、研究机构和农民等各方共同努力,制定合适的政策和措施,推动农业大模型的可持续发展和推广。

