本文来自微信公众号“半导体行业观察”。
2025年的春节,可能是中国有史以来科技味最浓的。一切,都只因为DeepSeek的横空出世。
作为全球增速最快的AI应用,DeepSeek上线20天来,日活用户数突破2000万,目前达到了ChatGPT的23%,并且应用每日下载量接近500万。饶毅教授甚至在其个人公众号上评价道,“DeepSeek是鸦片战争以来,中国对人类最大的科技震撼。”
如此之快的爆发速度,一方面说明DeepSeek的开源和低价策略正在重构AI应用行业生态,使得更多中小公司有机会加入AI竞争,削弱了巨头的护城河。另一方面,DeepSeek-R1在数学、代码等任务上展现出了比肩OpenAI o1的长文本推理和自我修正能力,表明DeepSeek大幅推动了AI推理能力的提升,拓展了AI推理在复杂任务和专业领域的应用边界,使AI能够更好地处理复杂的推理问题。
数据显示,DeepSeek通过架构创新,使显存占用降至传统架构的5%-13%,推理成本仅为GPT-4 Turbo的1/70,训练成本更是OpenAI同类模型的1/10。这意味着,在大幅降低算力依赖的同时,DeepSeek也颠覆了AI行业的底层逻辑——从依赖算力堆砌转向算法驱动效率,继而加速整个行业生态向开源、普惠方向演进。
但这并不代表DeepSeek未来在模型性能方面会存在任何妥协。事实上,为了进一步提升模型性能,尤其是在处理更复杂的任务,如多模态融合、更深入的语义理解和更精准的生成,DeepSeek模型参数量将继续增大,从而对内存容量和带宽提出更高的需求。
这一过程中,一种新型内存架构——多路复用双列直插内存模组(Multiplexed Rank DIMM,MRDIMM)将因此受益。作为一种高性能的内存互连解决方案,MRDIMM能够提供更高的内存密度和带宽,满足以DeepSeek为代表的大模型对大规模数据处理的需求。
AI发展,苦“三力”久矣
这里的“三力”,即“算力”、“存力”和“运力”。
以大语言模型GPT为例,2022年11月发布的GPT-3使用了1750亿个参数,而2024年5月发布的最新版本GPT-4o则使用了超过1.5万亿个参数。不仅是GPT系列,过去几年里,Transformer类模型参数数量的增长普遍都以指数级别呈现,每两年大约增加410倍。
从近年来服务器CPU的技术路径来看,一个显著的趋势是CPU厂商不断增加内核数量,CPU核心数呈指数级增长,如英特尔和AMD最新一代CPU核心数都达到了数十甚至上百的量级。同时,自2012年以来,数据中心服务器内存对速度、容量的要求每年都在以超过10倍的速度增长,且没有减缓的迹象。可以说,“算力”和“存力”在过去十年里的确是得到了空前的进步。
与之形成鲜明对比的,是为处理器提供必要的内存带宽一直是“一场艰苦的斗争”。传统内存RDIMM传输带宽的线性增长态势与CPU核心数量的指数增加速度不匹配,这是AMD和英特尔在其主流处理器上转向DDR5内存的原因之一。
这也直接带动了DDR5市场的快速发展。市场调研机构Omdia分析指出,对DDR5的市场需求从2020年开始逐步显现,到2024年,DDR5将占据整个DRAM市场份额的43%左右。
可以想象,如果上述现象一直持续下去,在超过一定的核心数量后,所有CPU都会出现带宽分配不足的情况,从而无法充分发挥增加核心数量所带来的优势,严重制约CPU性能的发挥,形成了所谓的“内存墙”,难以满足系统性能的平衡。
AI推理、大数据应用、以及众多高性能计算工作负载侧也遇到了同样的情形。以先进驾驶员辅助系统(ADAS)为例,L2+/L3级别系统的复杂数据处理至少需要超过200GB/s的内存带宽;在L5级,如果车辆要能够独立地对周围动态环境做出反应,将需要超过500GB/s的内存带宽。
这些内存密集型计算之所以迫切需要大幅提高内存系统的带宽,以满足多核CPU中各个内核的数据吞吐要求,一是因为高带宽是复杂AI/ML算法的基本需求,二是相较于AI训练,AI推理更重视计算效率、时延、性价比等,而且AI推理需要应用到不同的端侧上,单纯依靠堆砌额外数量的GPU和AI加速器,很难在成本、功耗、系统架构等方面获得竞争优势。
因此,必须要找到更加高效的内存数据传输与处理体系架构,提高内存利用效率,才能有效化解“内存墙”问题,才能让庞大的数据和计算资源实现按需组合,并根据不同工作负载的需求动态配置内存资源。
这时,MRDIMM这样新的内存技术就逐渐走进了人们的视野之中。那么,什么是MRDIMM?它有何神奇之处?接下来,就让我们揭开MRDIMM的“前世今生”。
释放存储带宽的魔力
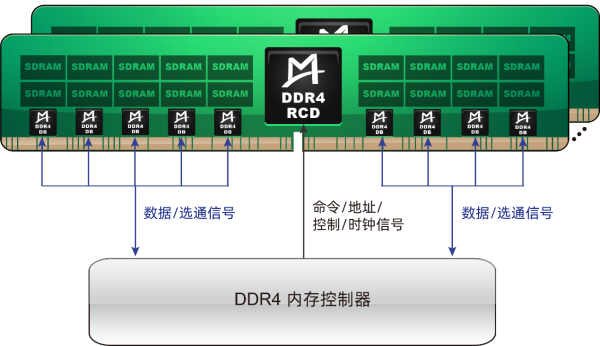
MRDIMM最早可追溯到DDR4世代的LRDIMM(Load Reduced DIMM,减载双列直插内存模块),该种类型的内存模组旨在降低服务器内存总线的负载,同时提高内存的工作频率和容量。
与服务器使用的传统内存模组RDIMM只采用RCD(Registered Clock Driver,寄存时钟器)相比,LRDIMM新增了DB(Data Buffer,数据缓冲器)功能,这种设计不但降低了主板上的信号负载,还允许在模组上使用更大容量的内存颗粒,从而能够显著提升系统内存容量。
JEDEC当时对于LRDIMM架构曾有过不同方案的讨论,最终采纳了中国澜起科技公司发明的“1+9”(1颗RCD+9颗DB)方案作为DDR4 LRDIMM的国际标准。这并不是一件容易的事情,要知道,在DDR4世代,全球只有IDT(后被日本瑞萨电子收购)、Rambus和澜起科技三家公司可以提供RCD及DB芯片套片。而在贡献DDR4 LRDIMM国际标准后,澜起科技也于2021年入选JEDEC董事会,进一步提升了自身的行业话语权。
资料来源:澜起科技
进入DDR5世代,尽管根据JEDEC的定义,LRDIMM演变为“1颗RCD+10颗DB”的架构,但由于DDR5内存模组容量较DDR4有显著增加,使得DDR5 LRDIMM的性价比优势逐步缩小,其在服务器内存中的占比并不是很大。
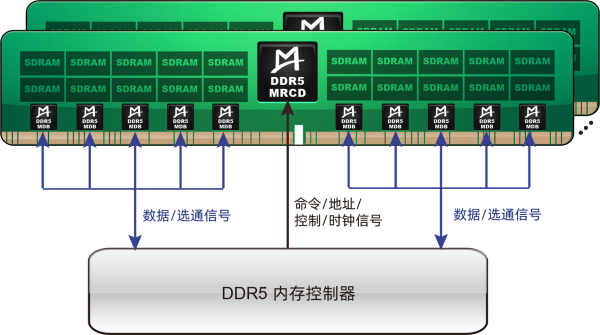
此时,沿用了与LRDIMM类似的“1+10”技术架构,即需要搭配1颗MRCD(多路复用寄存时钟驱动器)芯片和10颗MDB(多路复用数据缓冲器)芯片,能实现更高内存带宽的MRDIMM开始登上历史舞台。
从工作原理角度来讲,MRDIMM能显著提升接口速度和内存带宽的关键,源于其在内存模组上集成的多路复用器或数据缓冲器。得益于此,MRCD能够在标准速率下同时生成四个芯片选择信号,支持更复杂的内存管理操作;MDB可以把两个内存阵列的传输数据组合为一个,一个内存阵列可以传输64字节的数据,两个内存阵列同时操作就可以一次传输128字节数据,使DRAM一次可以向CPU传输128个字节的数据,实现传输速率的翻倍。这样,带宽的魔力就被彻底的释放出来。

资料来源:Lenovo
MRDIMM的优势概括起来主要有三点:
- 速率大幅提升。相较于同时期RDIMM支持6400MT/s速率,第一代MRDIMM支持8800MT/s速率,提升幅度接近40%,这一提升幅度过去往往需要2-3代才能实现。而第二代和第三代MRDIMM的速度更是将达到12,800 MT/s和17,600 MT/s。
- 与DDR5良好的兼容性。MRDIMM完美兼容常规RDIMM的连接器和外形规格,对客户来说,无需对主板进行任何改动,就可轻松实现升级。
- 出色的稳定性。MRDIMM全面继承了RDIMM的纠错机制及RAS(可靠性、可用性和可维护性)功能,确保无论数据缓冲区中产生何种复杂的独立多路复用请求,都能有效维护数据的完整性与准确性。
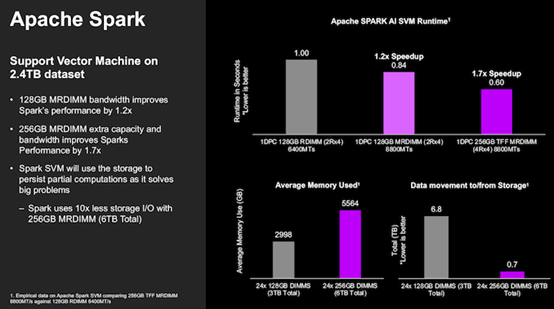
目前来看,HPCG(High Performance Conjugate Gradient)、AMG(Algebraic Multi-Grid)、Xcompact3d这些科学计算类的应用,以及大语言模型推理,是MRDIMM的最大受益者。
在美光和英特尔的一项联合测试中,研究人员使用了英特尔Hibench基准测试套件中的2.4TB数据集,在内存容量相同的情况下,相较RDIMM,MRDIMM的运算效率提高了1.2倍,使用容量翻倍的TFF MRDIMM时运算效率提高了1.7倍,内存与存储之间的数据迁移减少了10倍。
资料来源:anandtech
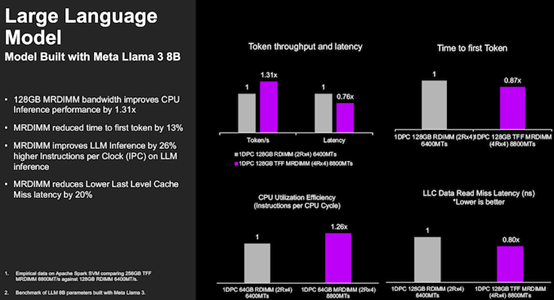
MRDIMM也提升了AI推理的效率。在内存容量相同的情况下运行Meta Llama 3 8B大模型,使用MRDIMM后,词元的吞吐量(Token throughput)是RDIMM的1.31倍,延迟降低24%,首个词元生成时间(Time to first Token)降低13%,CPU利用效率提升26%,末级缓存(LLC)延迟降低20%。
资料来源:anandtech
上述优势使得MRDIMM一经推出就受到产业界的广泛关注。通过采用DDR5的物理和电气标准,MRDIMM实现了内存技术的突破,使CPU单核心的带宽和容量得以扩展,极大改善了大算力时代“内存墙”桎梏,对于内存密集型计算效率的提升意义重大。
盘点MRDIMM的主要玩家
2024年7月,美光科技宣布推出MRDIMM,支持32GB到256GB广泛的容量选择,涵盖标准型和高型外形规格(TFF),适用于高性能1U和2U服务器。根据美光的测试数据,与RDIMM(支持速率6400MT/s)相比,MRDIMM(支持速率8800MT/s)有效内存带宽提升高达39%,总线效率提升超过15%,延迟降低高达40%。
当然,美光也不是第一个公开宣布MRDIMM样品的公司。三星在2024年6月宣布了自己的MRDIMM产品方案,该方案通过组合两个DDR5组件,使现有DRAM组件的带宽翻倍,可提供高达8.8Gb/s的数据传输速度。
而在更早之前的2022年底,SK海力士推出了用于特定英特尔服务器平台的MCR-DIMM技术,允许高端服务器DIMM以最低8Gbps的数据速率运行,较之当时DDR5内存产品(4.8 Gbps)相比,带宽提高了80%。
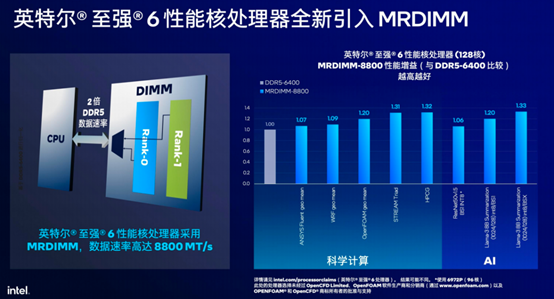
英特尔2024年10月推出的至强®6性能核(P-Core)处理器至强6900P,就将支持每秒8800MT的MRDIMM内存作为产品亮点之一,独立测试表明,使用MRDIMM的至强6处理器比使用传统RDIMM的相同系统性能提升高达33%。同时,通过使用标配的6400MT/s DDR5内存和更快的MRDIMM内存相结合的方式,英特尔可以处理对内存非常敏感的工作负载,包括科学计算、AI等。
资料来源:英特尔
再回到MRDIMM本身,如前文所述,在MRDIMM实现双倍带宽的过程中,MDB芯片起到了至关重要的作用。目前全球可以提供完整MRCD/MDB芯片套片的供应商包括瑞萨电子、Rambus和澜起科技三家公司,这与DDR4世代的格局是一致的。
作为中国在内存接口芯片市场上的标杆型公司,2024年,澜起科技DDR5内存接口芯片出货量在第三季度超过DDR4内存接口芯片,其出货占比将在第四季度进一步增加,而MRCD/MDB芯片则实现超过7000万元人民币的销售收入。目前,澜起科技第一代MRCD/MDB套片产品已成功实现量产,第二代MRCD/MDB套片的工程样片已经推出,并在近日完成了向全球主要内存厂商的送样工作,有望再次引领行业技术发展潮流。
澜起科技第二代MRCD芯片支持高达12800MT/s的速率,可精确缓冲并重新驱动来自内存控制器的地址、命令、时钟及控制信号。第二代MRCD芯片具有两个子通道,每个子通道又分为两个伪通道,以增加主机系统的总带宽。同时,两个子通道分别执行CA和DPAR输入信号的奇偶校验检查,两个伪通道分别接收CA(命令/地址)信号输入并生成独立的CA输出信号。
资料来源:澜起科技
与之协同工作的第二代MDB芯片同样支持12800MT/s的数据速率。芯片主机侧配备双4位数据接口,运行速度是DRAM侧的两倍;DRAM侧设有四个4位数据接口,每个伪通道分配两个。MDB可高效的将两个DRAM侧DQ信号多路复用为一个主机侧DQ信号,并通过一个仅输入的控制总线接口,用于连接MRCD。
性能跃升及生态完善将共同推动MRDIMM的未来
从8,800MT/s到17,600MT/s,MRDIMM带宽和性能的显著提升对高性能计算、AI计算客户来说是颇具吸引力的。可以预见,基于推理应用的新一轮AI基础设施建设将刺激终端对MRDIMM需求。
同时,考虑到第一代MRDIMM目前只有英特尔的Granite Rapids支持,行业相关生态仍处于初期,但从第二代MRDIMM开始,随着相关技术逐步成熟,业内预计将有更多类型服务器CPU支持MRDIMM,行业生态将进一步完善,并最终实现终端需求放量。
对内存接口芯片厂商而言,考虑到一根MRDIMM需要标配十颗MDB芯片,MRDIMM的普及势必将大幅提升MDB芯片的需求,从而扩大内存接口芯片行业市场规模,全球三家内存接口芯片厂商也均会受益于该项新技术的发展。
但与其他方案相比,澜起科技在MRDIMM相关技术标准制定中具有的影响力,将有望成为其最强的竞争优势之一。从DDR4 DB到DDR5 DB,再到牵头制定MDB芯片国际标准,澜起科技在技术规范和兼容性上具备的权威性和前瞻性,能够帮助生态伙伴更好地适应未来行业的发展和变化,在市场竞争中占据有利地位。加之高效的客户支持,良好的产品兼容性,以及与生态系统上下游厂商的深度合作,都为澜起科技在MRDIMM领域的竞争力提供了坚实的基础。
