本文来自微信公众号“twt企业IT社区”,作者/刘艳春。
随着人工智能和机器学习技术的飞速发展,大模型已广泛应用于各个领域,大模型拥有更强的数据处理能力和更高的预测精度,为企业提供了更为精准的业务分析和预测服务。然而,在数据获取,数据处理、模型训练、模型微调、推理应用等业务流程中,特别是在计算机视觉、自然语言处理、语音处理以及跨模态检索生成等关键环节中,每个阶段都涉及数据的存储与访问,对存储系统有很大的挑战。一方面,大模型的训练和推理过程需要大规模数据的支持,这些数据需要高效的存储和访问;另一方面,大模型的部署和维护需要稳定、高效的存储系统,以确保模型的持续运行和数据的可靠性,同时还需要注重数据的安全性和隐私保护。为了应对这些挑战,企业需要采用高效的数据处理技术和算法,同时需要构建高性能、可扩展的存储系统,以满足数据处理的实时性和可靠性需求。
一、AI大模型存储需求
AI大模型的存储需求,随着业务场景复杂性和数据量的增长,在不断演变和升级。模型的数据处理模式已经从单一类型转向包含文本、图片、音频、视频等在内的多模态数据,这种转变导致原始数据量呈现爆炸式增长,往往达到PB级别。这就要求存储系统必须具备足够大的容量,以容纳这些海量的多模态数据。同时,AI大模型的规模也在持续扩大,参数数量从数百万跃升至千亿甚至万亿级别,这种庞大的模型规模不仅对计算资源提出了更高的要求,也对存储系统的性能和稳定性构成了严峻的挑战。由于模型训练涉及大量的数据读写操作,包括向量库、日志、超大CheckPoint文件等,这就要求存储系统必须具备出色的I/O性能、高带宽和低延迟,减少宝贵GPU算力资源的等待。有数据显示,千卡多模态大模型单个CheckPoint文件能够达到TB级,在训练过程中大模型每隔2小时左右就会暂停保存CheckPoint,这时GPU资源都是被浪费的。因此需要存储的高性能能力,来减少GPU等待。除了容量和性能方面的需求外,AI大模型还对存储系统的稳定性有着极高的要求。在训练过程中,任何数据丢失或存储故障都可能导致模型训练的失败,甚至造成无法挽回的损失。因此,存储系统的稳定性对于AI大模型的训练和推理至关重要。
在应对海量小文件方面,存储系统需要展现出高并发、低延迟的特性。由于小文件数量巨大,存储系统需要能够快速响应并发读写请求,避免因延迟过高而影响模型训练和推理的效率。同时,随着业务规模的不断扩大和数据量的持续增加,存储系统还需要具备优秀的扩展性,以灵活应对未来的增长需求。
对于异构多模态数据的存储需求,存储系统需要能够高效管理并加载相互关联、嵌套的数据。要求存储系统不仅具备高性能和可扩展性,还需要具备高度的可维护性和可靠性。同时,随着大模型对分布式并行训练的需求日益增长,存储系统还需要支持高并发、低延迟的数据加载和模型训练,存储系统需要具备出色的数据吞吐能力和低延迟性能,以满足大规模并行训练的需求。
随着数据使用频率和价值的变化,存储系统还需具备数据生命周期管理能力,智能地进行数据归档、删除和迁移,从而优化存储资源使用,提高数据访问效率,降低存储成本并提升数据价值。同时,随着云计算和边缘计算技术的不断进步,跨平台的数据访问和共享已成为大模型存储系统的关键特性,要求存储系统必须提供高度一致的数据服务,并确保高可用性和容错能力,要求存储系统支持多种协议和接口,实现数据的灵活流动和高效协作。
AI大模型训练中心也面临着巨大的能耗压力,例如ChatGPT每天可能要消耗超过50万千瓦时的电力,以响应用户的约2亿个请求。GPT3每训练一次,就要消耗128.7万度电,消耗的电力是我们三百个家庭一年的电量。马斯克曾说AI发展正在从缺硅走向缺电,因此存储作为AI数据中心关键基础设施,既要考虑高性能、高可用性和大容量,还需要考虑AI数据中心绿色节能的诉求。
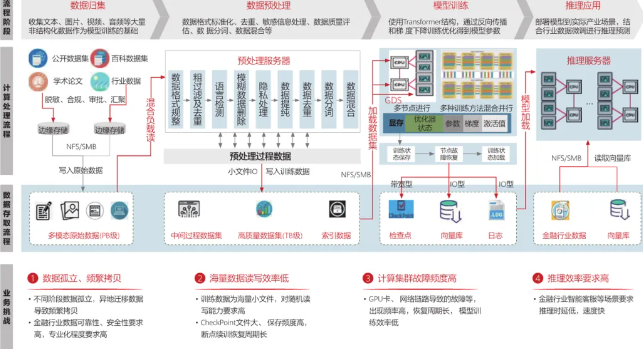
图1大模型存储挑战与需求
综上所述,AI大模型对存储的需求是多方面的,包括大容量、高性能、高稳定性、高效性、绿色节能以及跨平台的数据访问和共享能力等。随着AI技术的不断进步和应用场景的不断拓展,这些需求还将持续演化和升级。因此,需要不断创新和优化存储技术,以满足AI大模型日益增长的存储需求,并推动AI技术的广泛应用和发展。
二、大模型存储技术策略
未来大模型存储的方向将根据不同应用场景和实际需求来灵活选择适宜的存储方式,如分布式存储、对象存储、数据湖以及集中存储等,以实现数据的高效管理、快速访问和灵活扩展。建议存储技术策略如下:
1.分块存储:针对海量小文件,建议将小文件分成固定大小的数据块,分别存储在不同的存储节点上。这种方式可以有效地提高并发读写性能,降低单个节点的负载。同时,通过合理地分配数据块,可以避免节点间的数据热点,提高存储效率。
2.缓存加速:缓存加速技术利用高速缓存设备,将频繁访问的数据暂存于本地或高速存储中,显著提升了数据的读写速度和处理效率。合理调整缓存容量和策略,不仅有效避免了缓存失效及击穿等潜在问题,还实现了多层次的缓存优化,按需将热数据缓存到GPU内存和本地盘中,利用数据本地性提供高性能访问。训练先将Checkpoint写到性能相对容易保证的本地存储,再向远端对象存储服务器/数据湖上传。
3.数据压缩:采用数据压缩技术,对小文件数据进行压缩存储。可有效地减少存储的空间占用,提高存储效率。同时,通过合理地选择压缩算法和压缩参数,可以平衡压缩和解压缩的时间消耗,避免对存储性能产生过大影响。
4.去重技术:利用去重技术,去除重复文件数据,只存储一份数据副本。这种方式可以有效减少存储空间的占用,提高存储效率。同时,通过合理地选择去重算法和去重参数,可以避免对存储性能产生过大影响。
5.连续稳定:为了确保训练的连续性和稳定性,存储系统需要提供强大的训练断点保存与恢复功能。模型训练的Checkpoint机制是确保训练过程可靠性的关键。通过优化Checkpoint过程并减少其耗时,降低训练中断的时间,提高训练效率and/or利用率,减少GPU空闲,优化数据清洗过程,数据搬运和处理与计算重叠;2.优化读取过程,让每Epoch读取数据耗时小于计算耗时。同时存储系统需要具备高带宽的特性,从而确保数据能够迅速、稳定存储。
6.异构多模态存储:采用分布式存储系统,如Hadoop、Spark等,将异构多模态数据分布存储在多个节点上,实现数据的并行读写和高效处理。采用并行计算框架,如TensorFlow、PyTorch等,结合分布式存储系统,实现多模态数据的快速训练和加载。建立异构多模态文件数据间的关联和嵌套关系,例如图-文对应、文-视频对应等,以实现数据的多模态融合。
三、大模型存储未来方向
分布式存储可以通过将数据分散到多个节点来实现可扩展性和容错性,非常适合大规模数据存储和处理。而对象存储则提供了更加灵活的数据存储和管理方式,适用于各种类型的数据,包括图片、视频、文本等。
此外,数据湖作为一种新的数据存储和处理架构,将公开数据集、训练数据、模型结果统一存储到数据湖,实现不同形态的数据统一存储和高效流转,避免数据在AI大模型不同的阶段频繁拷贝,降低效率。为落地多模态、万亿参数大模型,企业数据湖将需要具备如下能力:1)支持EB级的横向扩展能力来应对多模态海量数据的爆发;2)支持10TB级的带宽,亿级的IOPS,数据加载、断点/故障恢复CheckPoint加载时长从小时级->秒级;3)提供全局统一命名空间、数据同步一致访问、数据强一致的存储集群,降低AI调度平台复杂度。对于追求极致性能和能效比的应用场景,存算一体化和近存加速技术或将脱颖而出。而对于需要灵活性和可扩展性的应用,存算分离策略可能更为合适。展望未来,大模型存储将呈现综合性发展趋势,不仅关注性能与效率,还强调可靠性、安全性、多模态支持、智能化管理以及绿色环保等多个维度。随着技术的持续革新和应用需求的不断演变,大模型存储系统必将迎接新挑战,并持续创造新的价值。
