本文来自极客网,作者:小刀。
现在的生成式AI工具还不完美,经常会“撒谎”,这就是所谓的幻觉。为了克制幻觉,开发者开发出一系列工具,最近在硅谷比较流行的工具是检索增强生成(Retrieval-augmented Generation,简称RAG)。

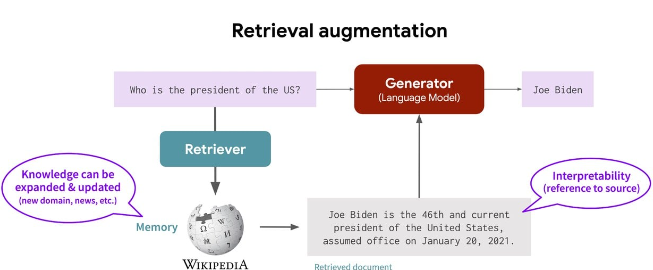
RAG是一种结合检索和生成技术的模型,它为大模型提供外部知识源,使得大模型具备从指定的知识库中进行检索,并结合上下文信息,生成相对高质量的回复内容,减少模型幻觉问题。例如,企业可以将所有的HR政策和福利信息上传到RAG数据库,AI聊天机器人聚焦于可以从这些文件中找到的答案。
听起来RAG似乎和ChatGPT技术没有什么太大差异,实际上差异蛮大的。Thomson Reuters用RAG技术开发出一套面向法务工作者的AI工具,其公司高管Pablo Arredondo说:“RAG不会单纯依靠初始训练生成的记忆来回答问题,它会利用搜索引擎收集真实文档,比如判例法、论文等,然后根据这些文档锚定模型的响应。”
例如,我们可以将某本杂志的所有内容上传到数据库,根据数据库内容回答问题。因为AI工具关注的信息面比较窄,信息质量更高,基于RAG开发的聊天机器人在回答问题时会比通用机器人更有深度。
RAG机器人会不会犯错呢?当然会,但它捏造内容的概率会降低。
研究人员认为,RAG方法有很大优势,在训练模型时,它所接受的信息都是事实,而且是可以追溯来源的事实。如果你能教模型对提供的数据进行分类,并在每个输出结果中使用、引用,那么人工智能工具就不太可能犯严重的错误。
用了RAG技术,幻觉能降低多少呢?一些研究者认为,幻觉可以达到很低的程度,但无法完全消除。换言之,RAG不是万能药。总体看,幻觉减少程度取决于两个核心要素:一是整体RAG的部署质量,二是对AI幻觉的定义。
并非所有的RAG都是一样的。在自定义数据库中,内容的精度影响着结果质量,但它并不是唯一影响因素。除了要关注内容的质量,还要关注搜索质量及基于问题的正确内容的检索。掌握过程中的每一步都至关重要,因为一个失误就可能使模型完全偏离。
斯坦福教授Daniel Ho说:“凡是在某个搜索引擎中使用自然语言搜索的律师都会发现,许多时候语义相似度影响巨大,它会导出完全不相关的资料。”
如何定义RAG应用中出现的幻觉也很重要。一些专家认为,判断RAG系统是否出现幻觉主要是看输出结果是否与数据检索时模型找到的答案一致。斯坦福大学则认为,要检查结果,看它是否基于提供的数据,是否符合事实。
在回答法律问题时,RAG系统明显比ChatGPT、Gemini更好,但它仍然有可能忽视细节,随机给出错误答案。几乎所有专家都认为,即使有了RAG系统,也需要人类参与,对引用信息进行双重检查,判定结果的准确率。
在法律领域RAG系统可以找到用武之地,在其它领域也一样。凡是需要专业知识的专业领域,AI系统给出的答案都应该锚定真实文件,所以RAG适合专业领域。
Daniel Ho说:“幻觉一直存在,我们还没有找到好办法真正消除幻觉。”虽然RAG可以降低错误率,但还是需要人类来判断结果如何。(小刀)


