本文来自微信公众号“与非网eefocus”,作者/张慧娟。
AI算力在2023年呈现出快速增长态势。一方面,千行百业的AI应用推动了算力的结构性增长机会,AI芯片继续多样化演进趋势;另一方面,从大模型到AIGC,算力需求激增,且随着模型规模和参数量的增长,算力需求仍在暴涨。
这也引发了业界的持续讨论:在竞逐更强、更快的未来算力时,还有哪些焦点问题不容忽视?面向更大规模的数据密集型AI应用中,居高不下的功耗问题如何解决?
国产存算一体,重大进展
在新一轮算力攻坚赛中,突破传统冯·诺依曼架构的范式探索成为主要方向之一。存算一体架构打破了存算分离的壁垒,减少了数据的搬运,它就如同“在家办公”的新型工作模式,消除了数据“往返通勤“的能量消耗、时间延迟,并且节约了“办公场所”的运营成本,因而具备高能效比,成为AI算力的重要发展方向。
近来,存算一体领域有一个标志性事件值得关注:
清华大学团队研制出全球首款全系统集成、支持高效片上学习(机器学习能在硬件端直接完成)的忆阻器存算一体芯片,相关研究成果已发表在《科学》(Science)上。
忆阻器(Memristor)是继电阻、电容、电感之后的第四种电路基本元件。它可以在断电之后,仍能“记忆”通过的电荷,因此被当做新型纳米电子突触器件。相同任务下,该芯片实现片上学习的能耗仅为先进工艺下专用集成电路(ASIC)系统的1/35,同时有望实现75倍的能效提升。
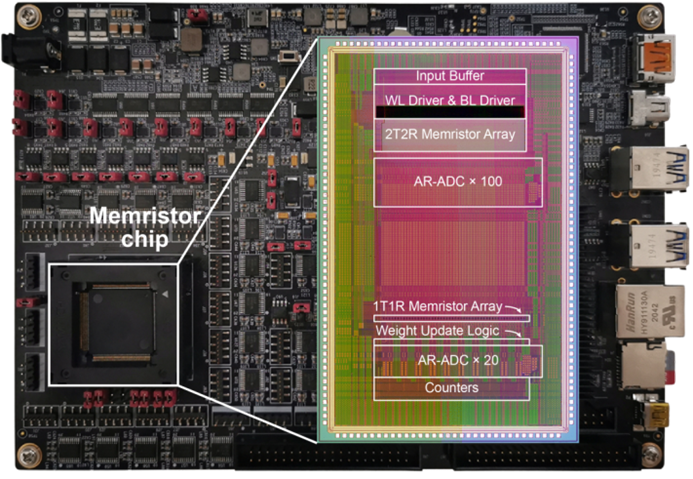
图:忆阻器存算一体学习芯片及测试系统
来源:清华大学官方微信
据了解,国际上当前在该领域的研究仍停留在忆阻器阵列层面的学习功能演示,而全系统集成的忆阻器片上学习芯片仍未实现。清华大学这一突破已经走在了全球前列,展示了存算一体技术突破传统计算架构的能效潜力和算力潜力。此外,由于具备高效的片上学习能力,可以实现数据的本地处理和动态更新,某种程度上可以降低对云端算力和网络带宽的依赖。
存算一体,大不相同
全球的存算一体玩家,主要可以划分为两大阵营:一类是国际巨头,比如英特尔、IBM、特斯拉、三星、阿里等,巨头对存算技术布局较早,代表存储器未来趋势的磁性存储器(MRAM)、忆阻器(RRAM)等产品也相继在头部代工厂传出量产消息。另一类是国内外的初创企业,比如Mythic、Tenstorrent、知存科技、后摩智能、千芯科技、亿铸科技、九天睿芯、苹芯科技等。
由于积淀不同、优势不同、目标场景不同,各家的存算一体方案也不尽相同,主要体现在三大差异上:技术路径、存储介质、以及采用的是模拟还是数字技术。
差异一:近存or存内?
先来看技术路径的选择。根据存储单元与计算单元融合的程度,可以分为近存计算和存内计算两类:
近存计算,本质上仍是存算分离架构,只不过计算模块通常安放在存储阵列(memory cell array)附近,数据更靠近计算单元,从而缩小了数据移动的延迟和功耗。但它依然保留了经典的冯·诺依曼架构的数据处理特点,存储阵列通常无需改动,仍旧只提供数据的访存功能。
近存计算的典型代表有AMD Zen系列CPU、特斯拉Dojo、阿里达摩院使用混合键合3D堆叠技术实现的存算一体芯片等,还有国外创业公司Graphcore、芯片大神Jim Keller加入的创业公司Tenstorrent等,他们目前推出的存算一体芯片都属于近存计算的范畴。
而在存内计算设计中,存储器件参与计算操作,这通常意味着存储阵列需要改动来支持计算。狭义上讲,这才是真正的存算一体,或者说,基于器件层面实现的存算一体才真正打破了存算分离架构的壁垒。在该架构下,存储单元和计算单元完全融合,没有独立的计算单元:直接在存储器颗粒上嵌入算法,由存储器芯片内部的存储单元完成计算操作。
巨头对存算一体产品的考量多是快速攻破算力和功耗瓶颈,开发出符合客户未来需求的技术;或是利用已有成熟生态,在丰富的应用场景中快速落地。也就是说,他们除了战略布局之外,对存算一体的一大预期是“实用、落地快”,因此,近存计算成为巨头首选。
而初创企业由于成立时间短、技术选择不存在路径依赖和历史包袱,他们反而可以另辟蹊径,直接选择将存储单元和计算单元完全融合的存内计算,实现更大的突破,进一步降低对先进制程、先进封装的依赖。例如国内的知存科技、九天睿芯、千芯科技、后摩智能等创业公司,选择的就是存内计算路线,以期向更高性能、更通用的算力场景进行突围。
差异二:存储介质
存算一体依托的存储介质呈现多样化,比如以SRAM、DRAM为代表的易失性存储器、以Flash为代表的非易失性存储器等。综合来看,不同存储介质各有各的优点和短板。
发展较为成熟的有NOR Flash、DRAM、SRAM等。NOR FLASH属于非易失性存储介质,具有低成本、高可靠性优势,但工艺制程有瓶颈;DRAM成本低、容量大,但是速度慢,且需要电力不断刷新;SRAM在速度方面有优势,但容量密度小,价格高,在大阵列运算的同时保证运算精度具有挑战。
根据<与非网>对国内多家存算一体厂商的调查来看,多数厂商当前倾向于技术成熟的SRAM设计存算一体芯片,后摩智能、千芯科技等都首先选择SRAM启动芯片开发。主要原因有四点:首先,SRAM的设计技术成熟,随着当前工艺节点的快速发展(从90nm到3nm),SRAM位单元尺寸减小超过了35倍,最小工作电源电压减小了超过1.25倍。第二,跟新型非易失性存储器相比,SRAM的制作工艺、研发工具和CMOS集成的电路模型都更加成熟稳定,同时SRAM具有更快的操作速度和耐久性,可以实时在存算单元中刷新计算数据,为大算力提供重要保障。第三,SRAM是目前唯一一种跟先进CMOS工艺完全兼容且能大规模量产的存储介质,这也是支持大算力的关键所在:从单独存算一体宏单元的角度,SRAM跟先进工艺的兼容性使其外围逻辑接口最能满足当前宏单元高效利用需求。第四,SRAM存算一体的实现途径可以达到跟传统冯·诺依曼架构中数字计算一致的运算精度,不需要复杂的重训练过程,可以有效降低上层编译器的开发难度,并提升AI模型的适用度。
不过,SRAM也有其固有瓶颈,例如较大的单元面积会导致随着工艺发展,CMOS扩展难度相应增大,芯片计算密度增长会逐渐放缓。因此,相关企业除了考虑量产能力和落地所需,也会采用“多驾马车”并驱的发展路线布局未来,灵汐科技、后摩智能、苹芯科技等正在对功耗较低、存储密度较高的新兴存储介质(比如MRAM、RRAM等)进行投入,以期随着工艺和商业化成熟获得更大的竞争优势。
差异三:数字or模拟?
按照电路技术路径分类,存算一体计算有数字存算和模拟存算的区分。近年来,学术界和工业界对二者的优缺点也有非常多的讨论。总体而言,数字存算和模拟存算有其各自优缺点:
首先,数字存算保留了传统数字电路的高抗噪性,对于不同制造工艺、电源电压和温度的变化呈现很强的鲁棒性,因而更适合大规模高计算精度芯片的实现。而模拟存算由于模拟计算电路本身的低功耗特点,在计算精度比较固定且较低的条件下,它可以获得更高的能量效率。
其次,数字存算要求存储单元内容必须以数字信号形式呈现,而模拟存算可以根据存储单元存储机理的不同,实现不同模拟域的运算,这就意味着模拟计算可以搭载任意存储单元来实现。
第三,相比模拟存算,数字存算实现运算灵活性较好,更适合通用性场景。模拟存算为了达到更好的能量效率,通常其关键模拟模块(如A/D转换器)的转换精度要求相对固定,且由于不同模拟计算方式可能具有不同的计算误差,因而这种技术路径的扩展性略显不足。
第四,相比数字存算,模拟计算减少了大量乘法器和加法器的面积开销,因而在面积开销上具有一定优势,同时各种不同的低功耗模拟计算电路的探索,也可以进一步提升其能量效率。
技术突破叠加市场需求,
存算一体来到产业化拐点
近年来,我国存算一体初创企业不断涌现,投融资进入活跃期,迎来产业化的重要转折点。<与非网>统计,进入2017年以来,国产存算一体芯片企业开始“扎堆”入场,并在2021年后逐步实现量产和产业化。较早成立的公司倾向于采用较为成熟的技术,主要布局低功耗、高能效需求的端侧场景。随着相关技术和应用的不断成熟,近年来成立的初创企业蓝图更为前瞻,在大算力布局和新技术应用方面更勇于尝新。
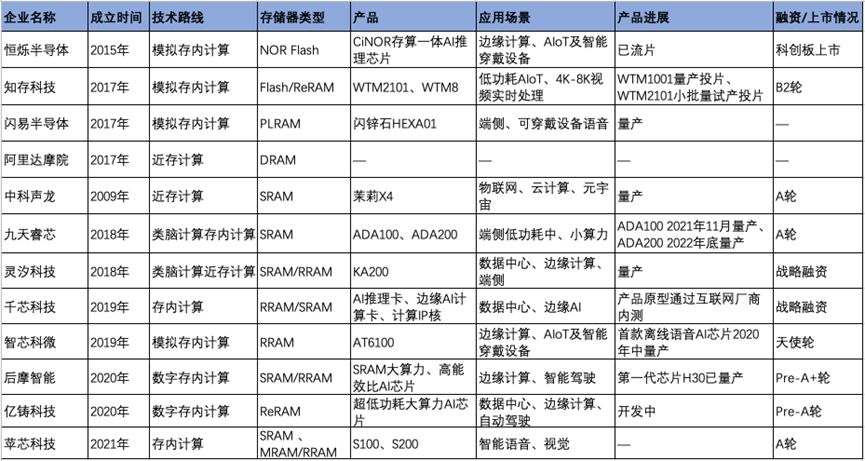
与非网据公开资料整理(2023.10.24)
2023年,存算一体的产业化进程有了质的突破:
小算力方面,知存科技去年量产的全球首颗基于模拟Flash存算一体的芯片WTM2101,可使用sub-mW级功耗完成大规模深度学习运算,适用于可穿戴设备中的智能语音和智能健康服务等场景,今年,该芯片出货已经达到kk级别。
落地和产业合作方面,除了在众多智能终端产品上的推进,知存科技联合中国移动研究院,完成了基于NOR Flash存算一体芯片的视频超分技术验证,为存算一体芯片在算力机顶盒、AR/VR终端、边缘视频解码器等场景支撑高效视觉AI应用奠定基础。这也是存算一体芯片进一步落地广泛终端和边缘场景的重要基础。
大算力方面也迎来重要的商业化转折点。后摩智能今年上半年发布了首款存算一体智驾芯片后摩鸿途H30,最高物理算力256TOPS,典型功耗35W,成为国内率先落地存算一体大算力AI芯片的公司。据了解,H30已开始给Alpha客户送测,第二代H50已在研发中,将于2024年推出,支持2025年的量产车型。
放眼未来,随着云边端智能应用的持续增长、场景的多样性也将继续快速拓展,存算一体产品如何走入更广泛应用中?
相关企业仍有两大核心挑战需要持续攻克:
首先在存算一体AI核和SoC的架构设计和实现方面,存内计算IP虽然提供了高能效的并行计算模式,但受限于所支持运算类型的局限性,因而对架构设计的难度和复杂度要求急剧上升,既要充分利用存内计算IP本身运算的高效性,又要减少存内计算IP之间的数据传输,同时还要兼顾支持网络算子的通用性和物理实现的可行性。
其次是存算一体软件编译器的快速部署和实现。软件工具链对于发挥存算芯片的效率至关重要,软件需要将模型切分成合适的Tensor算子,然后生成相应的指令调用底层硬件来处理。例如针对自动驾驶等场景,通过算子融合来提升计算和访存效率是非常关键的一个优化目标,需要工具链自动化完成算子的融合、调度及对大容量存算的高效管理,以同时提升芯片的利用率和应用的开发效率等。
写在最后
在算力越来越成为“紧俏货”的今天,存算一体作为后摩尔时代突破芯片性能瓶颈的主流技术方向之一,开始在产业中得到越来越多的关注。国产存算一体芯片如何顺流而上,早日迎来产业大发展?
短期来看,行业玩家的竞争主要集中在不同的存储介质和技术路线。长期来看,设计方法论、测试、量产、软件、场景的选择等全方位竞争才是长期发展和落地的关键,创业公司既需要掌握从存储器到AI芯片再到编译器和算法的一系列技术能力,也要构建强大的生态能力。
此外,存算一体技术若能进一步融合新型忆阻器、存算一体架构、Chiplet、3D封装等技术,将有望实现更大的有效算力、更高的能效比、实现更好的软件兼容性,从而进一步构筑国产AI芯片的发展阶梯。
