本文来自微信公众号“半导体行业观察”,作者/李飞。
上周,谷歌在论文预印本平台arxiv上发表了其关于TPU v4的深入解读论文《TPU v4:An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings》(TPU v4:通过光互联可重配置的机器学习超级计算机,搭载硬件嵌入层加速)。该论文将于今年六月在ISCA 2023(International Symposium on Computer Architecture,计算机架构领域的顶级会议)上正式发表,而目前的预印本无疑为我们提供了可以一窥其全貌的机会。
为了TPU的可扩展性设计专用光学芯片,谷歌也是拼了
从论文的标题可以看到,谷歌TPU v4的一个主要亮点是通过光互连实现可重配置和高可扩展性(也即标题中的“optically reconfigurable”)。而在论文的一开始,谷歌开门见山首先介绍的也并非传统的MAC设计、片上内存、HBM通道等AI芯片常见的参数,而是可配置的光学互联开关(reconfigurable optical switch)。作为论文的重中之重,这里我们也详细分析一下为什么光学互联在TPU v4设计中占了这么重要的位置,以至于谷歌甚至为了它自研了一款光学芯片。
TPU v4从一开始设计时,其目标就是极高的可扩展性,可以有数千个芯片同时加速,从而实现一个为了机器学习模型训练而设计的超级计算机。在谷歌的设计中,超级计算机的拓扑结构为:将4x4x4(64)个TPU v4芯片互联在一起形成一个立方体结构(cube),然后再把4x4x4这样的cube用连在一起形成一个总共有4096个TPU v4的超级计算机。
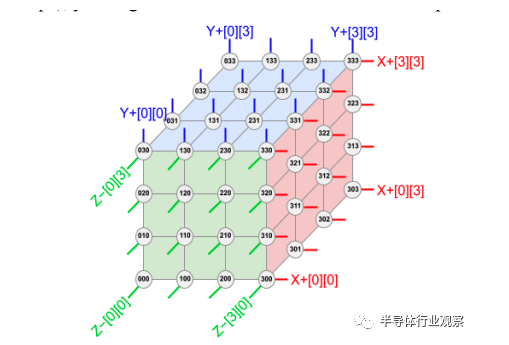
TPU超级计算机(由4096个TPU v4组成)拓扑结构
在这样的拓扑中,物理距离较近的TPU v4(即在同一个4x4x4 cube中的芯片)可以用常规的电互联(例如铜绞线)方法连接,但是距离较远的TPU之间(例如在cube之间的互联)就必须使用光互连,原因就在于在如此大规模的超级计算机中,芯片之间的数据互联在很大程度上会决定整体计算的效率;如果数据互联效率不够高的话,很多时候芯片都在等待来自其他芯片数据到达以开始计算,这样就形成了效率浪费。为了避免这样“芯片等数据”的情形出现,就必须确保芯片之间互联能拥有高带宽,低延迟。而光互连对于物理距离较远的芯片就成为了首选。
光互连在高性能计算中的使用也并非新闻,而谷歌在TPU v4中的主要突破是使用可重配置的光互连(即加入光路开关,optical circuit switch OCS)来快速实现不同的芯片互联拓扑。换句话说,芯片之间的互联并非一成不变的,而是可以现场可重配置的。这样做可以带来许多好处,其中最主要的就是可以根据具体机器学习模型来改变拓扑,以及改善超级计算机的可靠性。
从拓扑结构来说,不同的机器学习模型对于数据流的要求大致可以分为三类,即数据平行(每块芯片都加载整个模型,不同的芯片处理数据集中不同的数据),模型并行(模型中有些层特别大,因此每块芯片只负责这样很大的层中的一部分计算),以及流水线并行(把模型中的不同层交给不同的芯片计算),而不同的数据流就对应了不同的TPU互联拓扑。当有了可重配置光互连之后,就可以根据具体模型数据流来调整TPU之间的互联拓扑,从而实现最优的性能,其提升可超过2倍。
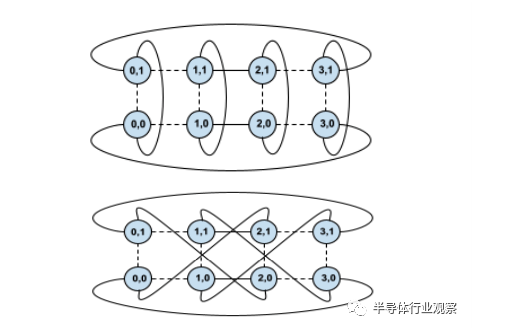
使用可重配置光互连可以快速切换不同的芯片间互联拓扑
另一个优势就是可靠性。在这样拥有海量芯片组成的超级计算机中,一个重要的考量就是,如果有一小部分的芯片不工作了,如何确保整体超级计算机仍然能维持较高的性能?如果使用常规的固定互联架构,那么一个芯片出故障可能会影响整个系统工作。而在有了可重配置的光互连之后,需要做的只需要把出故障的芯片绕过,就不会影响整个系统的工作,最多会牺牲一点整体的性能。谷歌在论文中给出了一个单芯片故障率和系统平均性能影响的曲线图,在使用可配置光互连(以及光路开关)时,假设芯片可靠率在99%的情况下,其整体系统的平均性能提升比不使OCS可高达6倍,可见光互连开关的重要性。
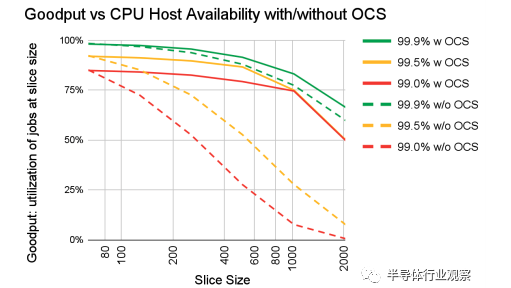
系统性能与芯片可靠性曲线图——使用OCS可以大大提升系统性能
为了实现数据中心级的可配置光互连,需要光路开关首先能高效扩展到超高数量的互联数(例如1000x1000),同时需要实现低开关切换延迟,低成本,以及低信号损耗。谷歌认为现有的商用方案都不够满意,因此谷歌的做法是自研了一款光路开关芯片Palomar,并且使用该芯片实现了全球首个数据中心级的可配置光互连,而TPU v4就是搭配了这款自研光路开关芯片从架构上实现了高性能。谷歌自研的光路开关芯片Palomar使用的是基于MEMS反射镜阵列的技术,具体原理是使用一个2D MEMS反射镜阵列,通过控制反射镜的位置来调整光路,从而实现光路的切换。使用MEMS的光路开关芯片可以实现低损耗,低切换延迟(毫秒级别)以及低功耗。在经过一系列优化之后,光路系统的成本也控制得很低,在整个TPU v4超级计算机成本中占5%以下。
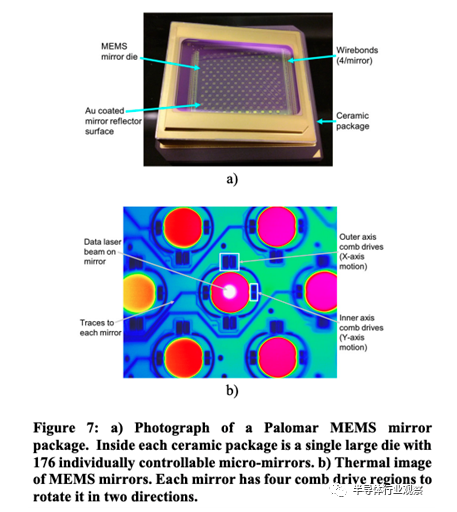
谷歌自研的Palomar MEMS光路开关芯片
算法-芯片协同设计是TPU v4的灵魂
如果说可重配置光互联给TPU v4提供了良好的根基的话,那么算法-芯片协同设计就是TPU v4的灵魂。算法-芯片协同设计包括两部分,一部分是如何根据算法优化芯片,而另一方面是如何根据芯片去优化算法,在TPU v4的架构中,两者都得到了仔细考虑。
我们首先分析TPU v4如何根据算法来优化芯片。如果说2017年TPU v1发表时候,其主要解决的还是卷积神经网络CNN的话,那么在2023年来看,CNN的加速问题早已经被既觉得差不多了,更多的是如何处理目前如日中天的大模型的问题。对于谷歌来说,目前最关键的大模型就是决定了其公司主营收入的推荐系统大模型,因此TPU v4的设计也针对推荐系统大模型做了相当的优化。在推荐系统大模型中,目前的加速瓶颈是嵌入层(embedding layer)。嵌入层的目的是将高维度稀疏特征映射到低维度高密度特征,从而该高密度低维度特征可以被神经网络进一步处理。嵌入层的实现通常是一个查找表(look-up table),而这个查找表可以非常巨大至100GB的数量级。在一个推荐系统模型中可以有多个这样的查找表,从而让整个查找表的存储量达到TB级别。如此巨大的查找表会需要使用分布式计算,将每一个嵌入层的查找表都分布到多块TPU v4芯片中进行计算。谷歌在论文中提到,在进行这样的嵌入层计算时,计算是以1D向量计算为主,而非2D矩阵或者3D张量计算;其次,计算往往是稀疏的(因为输入特征是稀疏的,因此并不是所有特征都会有高密度计算)而且分布在不同的芯片上,因此需要能对于共享存储进行优化,这样不同的芯片可以进行高效地数据交换。
为了实现对于嵌入层优化,谷歌在TPU v4中专门设计了一种专用加速模块,称为稀疏核(SparseCore,SC)。每个SC都有自己的向量计算单元(scVPU),2.5 MB本地SRAM,以及可以访问高达128TB共享HBM的内存访问接口。除此之外,SC还有一些专门为嵌入层操作设计的专用加速逻辑,包括排序(Sort)、规约(Reduce)、拼接(Concat)等。我们可以看到,其实每个SC的结构都较为简单,因此在每个TPU v4中都部署了大量SC,但同时SC总体的面积开销和功耗开销都紧紧占TPU v4的5%左右。谷歌在论文中比较了使用CPU运行嵌入层(这也是常规运行嵌入层的做法)以及使用TPU v4 SC运行嵌入层,结果表明在运行相同的推荐系统时,相对于把嵌入层在CPU上运行,把嵌入层放在TPU v4的SC上可以把整体推荐系统的运行速度提升6倍以上。事实上,这也是领域专用设计(domain-specific design)最吸引人的地方,即使用很小的芯片面积和功耗开销,可以得到非常大的性能提升。而谷歌在TPU v4的设计中把这样的领域专用化设计放到了对于整个公司都最关键的地方(决定谷歌整体收入的推荐系统模型的核心瓶颈嵌入层),从而撬动了非常大的收益。
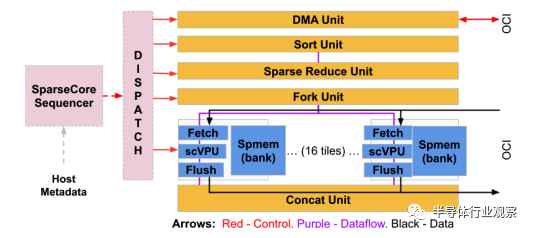
TPU v4的稀疏核(SC)设计
除了在芯片层面进行针对算法的优化之外,TPU v4还在分布式计算拓扑层面实现了对于算法的优化。在前文中我们提到,TPU v4引入可重配置光互连可以针对不同的人工智能模型实现不同的TPU v4之间的互联拓扑,为此谷歌设计了一套机器学习算法来决定如何根据人工智能模型来配置光路开关来提升性能。分析表明,对于目前最热门的大语言模型(包括GPT-3)的训练,使用机器学习算法查找到的最优TPU光互联拓扑配置可以提升1.2-2.3倍的性能。
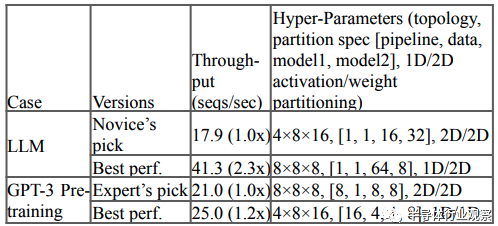
最后,谷歌还为了TPU v4专门设计了一套神经网络架构搜索(NAS)算法,可以根据TPU v4的特性来优化人工智能模型,从而确保经过优化的模型可以最高效地运行在TPU v4上,并且充分利用TPU v4的资源。与人工优化相比,使用该NAS可以实现推荐系统高达10%的运行时间优化,这大约相当于每年节省数千万美元的成本。
TPU v4与人工智能芯片的未来
从TPU v4的设计中,我们可以看到人工智能芯片未来的一些方向,而这些方向是我们在Nvidia的GPU等其他主流人工智能芯片的设计中也看到的:
首先就是对于高效互联和规模化的支持。随着人工智能模型越来越大,对于这类模型的支持主要依赖人工智能芯片的可扩展性(即如何让多芯片可以高效并可靠地一起分工合作来加速这样的大模型),而不是一味提高单芯片的能力来支持大模型,因为模型的演进总是要比芯片的设计迭代更快。在这个领域,不同的芯片公司会有不同的侧重,例如AMD侧重较为微观层面的使用chiplet来实现封装级别的可扩展性,Nvidia有NvLink等芯片技术来实现单机多卡之间的可扩展性和性能提升,谷歌则直接为了海量TPU互联设计了一款光路开关芯片;但是这些公司之间的共性,即对于人工智能芯片可扩展性的支持以满足大模型的需求,却是相当一致的。从这个角度来看,未来可扩展性(例如数据互联带宽)有可能会成为与峰值算力一样的人工智能芯片主要指标,而这也让人工智能芯片设计更加跨界:即不仅仅是需要对于数字逻辑和计算机架构方面的资源,同时也需要在封装、数据互联等领域都有积累。
此外,人工智能芯片与算法之间的结合继续保持紧密关系,算法-芯片协同设计仍然将是未来人工智能芯片继续提升性能的主要手段之一。我们目前已经看到了谷歌、Nvidia等在算法-芯片协同设计中的大量成果:包括对于新的数制(Nvidia的FP16、FP8,谷歌的BF16等)的支持,对于计算特性的支持(Nvidia对于稀疏计算的支持),以及对于模型关键算法的直接专用加速器的部署(Nvidia的transformer acclerator,谷歌的SC等)。随着摩尔定律未来越来越接近物理极限,预计未来人工智能芯片性能进一步提升会越来越倚赖算法-芯片协同设计,而另一方面,由于有算法-芯片协同设计,我们预计未来人工智能芯片的性能仍然将保持类似摩尔定律的接近指数级提升,因此人工智能芯片仍然将会是半导体行业未来几年最为热门的方向之一,也将会成为半导体行业未来继续发展的重要引擎。