本文来自极客网,作者:Ben Dickson。
谷歌旗下人工智能开发商DeepMind日前又发布了一项公告,推出令人印象深刻的AlphaTensor人工智能系统。这是一个深度强化学习系统,可以发现使矩阵乘法的效率显著提高的算法。
矩阵乘法是许多计算任务的核心,其中包括神经网络、3D图形和数据压缩。因此,可以提高矩阵乘法效率的人工智能系统有很多直接的应用。

为了创建AlphaTensor,DeepMind和科学家采用了深度学习系统AlphaZero,该系统曾经学习并掌握围棋、象棋和shogi等棋类游戏。乍一看,DeepMind似乎已经成功创建了一个通用的人工智能系统,该系统可以解决各种各样的无关问题。
考虑到AlphaTensor正在寻找更快的矩阵乘法的算法,有些人对于人工智能系统能够创建更好的人工智能系统表示怀疑。但AlphaTensor面临的一个更深层的现实是,如何将人类智慧和人工智能正确结合起来,帮助找到正确问题的正确解决方案。
人类的直觉和计算能力
行业专家在不久前发表的一篇文章中指出,人们所认为的人工智能技术实际上是一个非常好的解决方案发现者。人类仍然能够发现有意义的问题,并采用计算机能够解决的方式将其表述出来。这些是目前人类所独有的一些技能。
在最近的一次媒体采访中,计算机科学家Melanie Mitchell从不同的角度解释了这一点,即概念、类比和抽象。人类可以将自己的感知和经验转化为抽象概念,然后将这些抽象概念投射到新的感知和经验中,或者创造类比。这种能力对于在不断变化的世界中解决问题是非常重要的,因为人类总是面临并处理新的情况。而如今的人工智能系统严重缺乏这种能力。
为什么这些与本文讨论的技术相关?因为如果了解有关Alphaatensor论文的技术细节(这些细节令人印象非常深刻,就像DeepMind推出的大多数技术一样),就会看到人类直觉、问题表述、抽象和类比的完美展示。
问题空间和深度强化学习

Vanilla矩阵乘法
两个矩阵相乘的一般方法是计算它们的行和列的点积(或内积),但是有许多其他的算法可以将两个矩阵相乘,其中许多在计算上比普通的方法更有效。然而,找到这些最优算法是非常困难的,因为可以用近乎无限的方法分解两个矩阵的乘积。
科学家正在处理非常复杂的问题空间。事实上,问题空间是如此复杂,以至于DeepMind的科学家们只能专注于求解二维矩阵乘法。
研究人员在报告中写道:“我们在这里专注于实际的矩阵乘法算法,它对应于矩阵乘法张量的显式低秩分解。与二维矩阵相比,高效的多项式时间算法计算秩已经存在了两个多世纪,寻找三维张量(及以上)的低秩分解是NP-hard问题,在实践中也是困难的。事实上,搜索空间是如此之大,甚至连两个3×3矩阵相乘的最佳算法都是未知的。”
研究人员还指出,以前通过人类搜索、组合搜索和优化技术进行矩阵分解的尝试都产生了次优结果。
DeepMind此前曾经处理过其他非常复杂的搜索领域,比如棋类游戏围棋。用来掌握围棋的人工智能系统AlphaGo和AlphaZero使用深度强化系统进行学习,这种学习方法已被证明在解决无法通过暴力搜索方法解决的问题方面特别出色。
但为了能够将深度强化学习应用到矩阵分解中,研究人员必须以一种可以用AlphaZero模型解决的方式来表述问题。因此,他们必须对AlphaZero进行修改,以便它能够找到最佳的矩阵乘法算法。在这里,抽象和类比的力量得到了充分的展示。
棋盘游戏类比
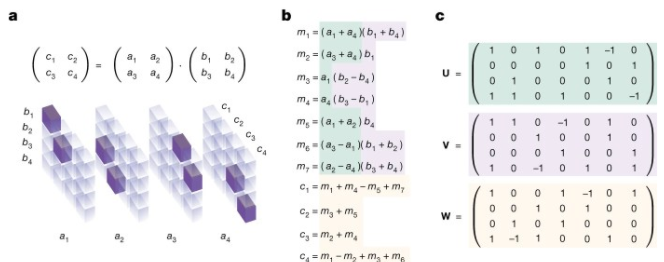
矩阵乘法算法
研究人员发现,他们可以将矩阵分解构建成为一个单人游戏,这使得它与AlphaZero所应用的那种问题更加兼容。
他们将这款游戏称为TensorGame,并将其描述如下:“在TensorGame的每个步骤中,玩家选择如何组合矩阵的不同条目进行相乘。其评分是根据所选操作的数量来分配的,以获得正确的乘法结果。”
基本上,他们将棋类游戏和矩阵分解进行了类比,并将后者定义为包含状态、行动和奖励的强化学习问题。这篇文章包含了详细而有趣的信息,介绍了他们是如何设计奖励系统来限制代理可以做出的动作数量,对时间更长的解决方案进行惩罚,以及为了简洁起见,在此不赘述的其他细节。
有趣的是,棋类游戏和矩阵分解有几个共同点:它们是完美的信息游戏(没有来自代理的隐藏信息),它们是确定性的游戏(在环境中事情不会随机发生),它们使用离散的操作(与连续的相反)。这就是AlphaZero是比AlphaStar(掌握星际争霸2的深层强化学习系统)是一个更好起点的原因。
然而,矩阵分解的问题空间仍然非常复杂。研究人员将TensorGame描述为“一款具有巨大动作空间的具有挑战性的游戏(在大多数有趣的情况下超过1012个动作),这比例如国际象棋和围棋这样传统棋盘游戏(数百个动作)要大得多。”
这就需要一种模型,能够从多种途径中找到最有希望的方向。
AlphaTensor模型
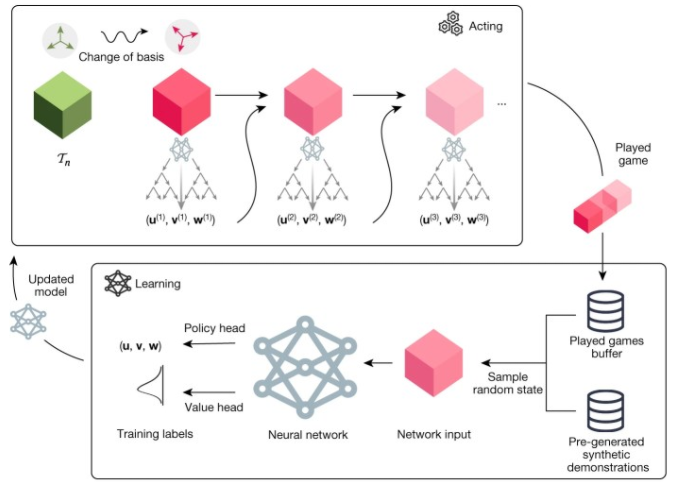
DeepMind AlphaTensor架构
AlphaTensor是AlphaZero的改进版本,但保持了由神经网络和蒙特卡罗树搜索(MTCS)算法组成的主要结构。在游戏的每一步,神经网络向MTCS算法提供一个可能的动作样本。当网络从它的行动中收到反馈时,将会逐渐变得更好。
根据这篇论文,该神经网络是一个Transformer模型,它“包含了张量输入的归纳偏差”。归纳偏差是帮助深度学习模型学习适合模型的正确表示的设计决策。如果没有归纳偏差,该模型可能无法处理矩阵分解中极其庞大和复杂的问题空间,或者需要更多的训练数据。
神经网络的另一个重要方面是用来训练它的合成数据,这是与AlphaZero模型的另一个突破。在这里,研究人员再次利用问题的性质来提高模型的训练和性能。
研究人员写道:“尽管张量分解是NP-hard问题,但从它的第一级因子构造张量的逆向任务是基本的。”
利用这一特性,研究人员首先随机抽样因子,然后构建原始矩阵,生成了一组“合成演示”。然后对合成数据和通过探索问题空间生成的数据进行训练。
研究人员写道:“这种针对目标张量和随机张量的混合训练策略训练,将显著地优于每种训练策略。尽管随机生成的张量与目标张量具有不同的属性,但这一点仍然存在。”
人类和人工智能之间的分工

AlphaTensor提供了非常令人印象深刻的结果,包括发现数千种新算法,以及针对特定类型处理器优化算法的能力(给定正确的奖励函数)。
这篇论文还列举了AlphaTensor可以启用的一些具体应用程序。在这里想强调的是这些人工智能系统研究中人类因素,这在媒体报道中经常被忽视。
就像谷歌的人工智能设计芯片和DeepMind的AlphaCode一样,AlphaTensor是人类智能和计算能力如何帮助找到有趣问题的解决方案的一个主要例子。人类利用他们的直觉、抽象和类比技巧,将矩阵分解形成一个可以通过深度强化学习解决的问题。然后,人工智能系统利用计算能力搜索可能的解决方案的广阔空间,并挑选潜在的候选方案。这是一个不容小觑的组合。(文/Ben Dickson)


