亿达信息药企销售大数据分析引擎提供统一的数据导入接口,整合药品销售相关的各种数据源,可根据用户需要对不同数据进行关联,具有建立企业KPI看板、销售预测与辅助决策、用户画像及关系图谱展现等功能。其中销售预测与辅助决策作为整个产品的核心功能,是药企销售大数据分析引擎的灵魂所在,是产品研发团队通过数据挖掘前沿技术和对BP神经网络预测算法进行相应改进,从而实现对药企销量的预测,并且可以通过调整影响因素的数值,得到相应的销售决策方案及销量预测数据,进而为销售管理及领导决策提供支持。
(一)项目情况
本项目是以药企供应链业务为基础,以大数据思维和供应链思维为导向,以大数据技术为手段,打造的集数据分析、未来预测、供应链协同等功能于一体的分析引擎。
项目采用自主开发模式,运用海量数据采集、自动化数据处理、分布式存储以及大数据海量分析等先进技术,实现整体供应链数据分析平台的建设。项目整体方案如下图:

项目内容包括:
1、运营监控平台:对医药企业主营业务活动、经营绩效指标、运营情况和人、财、物等核心业务资源进行监测,开展有针对性、系统性的分析与评价。包括经营统计报告、企业绩效评估、经营状况分析、风险管控等功能。
2、核心KPI预测引擎:运用大数据分析对企业核心KPI的完成情况进行预测,也可以用KPI预测其影响因素,为企业决策提供指导功能。
3、供应链协同平台:对供应链上各个模块间的关联因子进行平衡,有效的利用和管理供应链资源。
项目开发的药企供应链分析引擎平台,实施后将助力于各大医药供应链运营的可视化、智能化、自动化和集成化,实现市场推广、药品销售、市场资金流、医院与医生反馈等信息的高效高速整合。
(二)项目创新点
1、大数据组合建模技术
通过大数据建模技术,建立药企核心KPI预测模型,对药企销售业务实质进行分析整理,了解影响销量的各种因素。
对影响药企销量的直接因素和间接因素的全面数据画像分析,是大数据分析模型的基础,首先是企业历史数据的采集,为保证分析模型准确度我们需要至少3年的历史数据,足够多的历史数据会大幅度提升预测的结果准确率和决策精准度。在有了全面的历史数据采集之后,我们引入数据挖掘算法分离出影响销量的直接因素和间接因素。
传统的时间序列模型是建立在线性关系的假设上,因此对于非线性时间序列的预测的效果不太理想。而人工神经网络模型是非线性建模过程,具有较强的学习和数据处理能力,能够挖掘到数据中非线性的特征。利用ARIMA模型拟合时间序列的线性部分,再用BP神经网络模型估计时间序列的非线性残差部分,最终叠加为销售量的预测结果。与使用单一模型相比,该融合模型充分发挥了单一模型各自的优势,显著改善了单一模型的预测性能,并降低了模型的使用风险。
2、权威的医药销量预测与决策模型
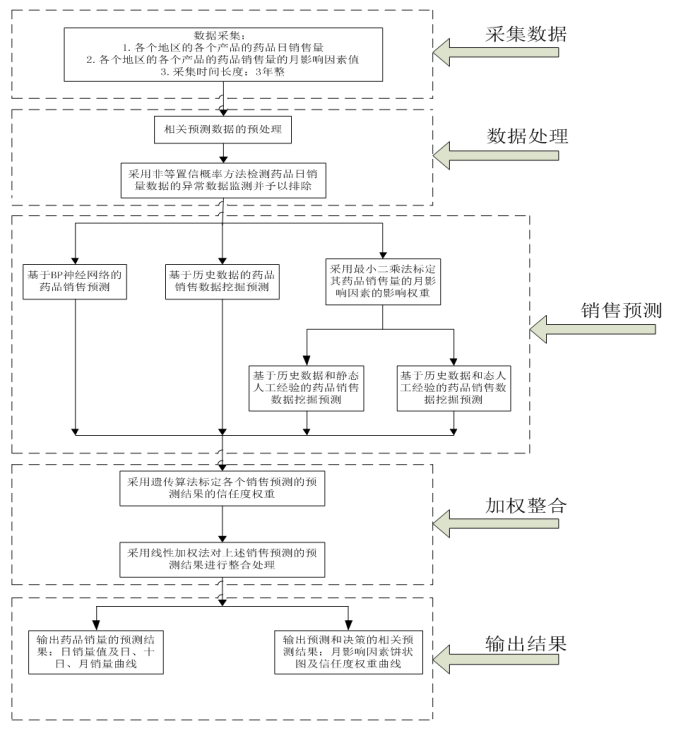
预测模型
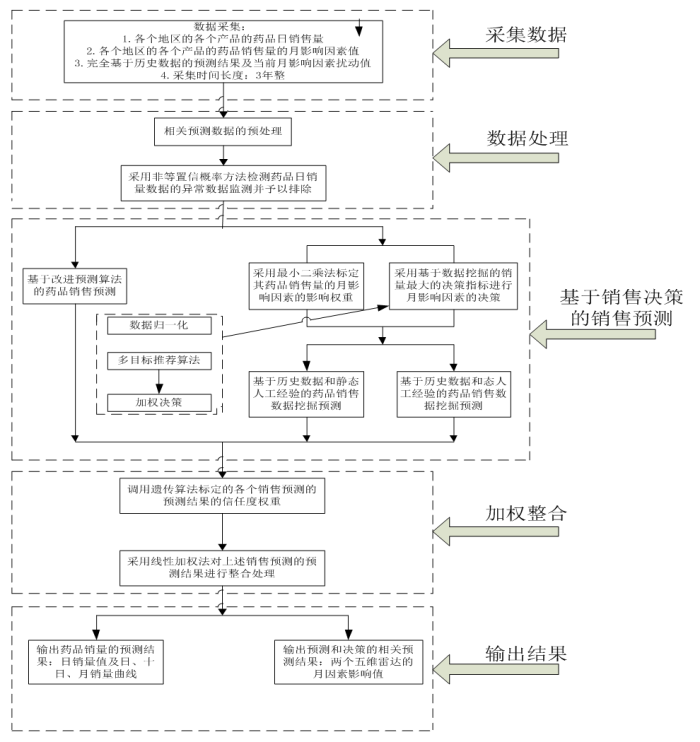
决策模型
(三)项目实现的关键技术
1、信息展示:
包括:GIS地图、热力图(商业)、标签云图、辐射图。
项目可以通过GIS地图及标签云图展示全国销售的全国医院。GIS地图是以可视化和分析地理配准信息为目的,用于描述和表征地图及其他地理现象的一种系统。可以充分展示药企销售医院全国的分布情况,药品详情。通过GIS内容维护,也可以对分布地图上医院进行可视化、汇总、分析、比较并解释分析结果。
商业热力图在项目上的应用,可以通过不同药品的不同省市实时销量展示。热力度常常用来表示地图上的分布密度,也可以简单理解为两维坐标中的数值到颜色的映射图。技术分点可以利用皮尔森相关系数来做恒定,该系数是用来反映两个变量线性相关程度的统计量,使用公式  相关性还可以通过热力度展示出来,这样可以对数据间线性关系有更直观的了解。
相关性还可以通过热力度展示出来,这样可以对数据间线性关系有更直观的了解。
药企医药代表通过对医院的各种赞助活动来拉近企业与医院更好的合作关系。系统也可利用标签云图来实时标准出全国各地企业赞助医药研讨会及各种线下活动。展示出活动的详细举办地点,活动性质信息等。
项目的以上地图都使用E-chat控件,并不同图例通过大屏投放的方式,将企业实时数据按照不同图例展示出来,实时反馈出整个药企服务的医院,药品物流情况,商业重点区域销售数据情况等,更加真实反馈企业全运营情况。
E-Chat大屏展示技术是亿达信息独家扩展开发一项新技术,利用这个技术可以多个方向全面应用。医疗器械物联网结合大屏数据实时展示技术,都将是公司主要研发方向。
2、分析算法:
包括:时序分析、逻辑回归。
采用时序分析、逻辑回归技术,可对收集在数据库中的数据预测未来销量。也可通过调整参数来预测未来销量。
3、基于Hadoop的系统体系结构:
(1)数据源层
本系统采用网络爬虫技术作为数据源层,将在后续内容中进行说明。
(2)数据传输层
数据传输层衔接了数据源层和数据加工层,它的主要责任是将数据从数据源抽取到数据加工层。数据传输方式主要有两种,一种是通过ETL中间件,一种为通过企业应用提供的数据传输接口。一般小规模数据提供数据传输接口,则数据直接通过接口进行传输即可,而大规模数据抽取则通过ETL中间件连接数据库直接抽取数据。
(3)数据加工层
由于数据量过于庞大,数据加工由Hadoop平台执行,实现对海量数据的降维、聚合等,在满足模型分析以及保持数据完整性和准确性的基础上对数据进行简化。
(4)数据存储中心
本文系统的数据存储中心是由Hadoop分布式存储平台与关系型数据库协同工作进行的,搭建Hadoop平台来存储海量数据,处理海量数据并向系统传输数据。数据从Hadoop平台导出到关系型数据库后,由关系型数据库对其进行实时分析或者挖掘,从而保证处理过程中的数据一致性。利用Hadoop与关系型数据库协同工作处理计算任务,把对海量数据的处理和对实时数据的处理分开,使得大规模的数据运算不会对营销系统的运行效率产生影响,同时也使得整个系统更加易于扩展,更加稳定。
(5)数据分析层
数据分析层主要职责是通过已建立的数据模型,对数据存储中心的数据加以分析计算,并将结果展示给用户。数据分析逻辑主要是通过关系数据库的存储过程以及MapReduce计算模型来实现,由于数据规模小的数据集被设计存储在关系型数据库,所以对于这类数据的分析可以通过关系数据库的存储过程实现,而规模大的数据集存储在HDFS,则数据模型需要通过编写MapReduce计算模型实现。
(6)应用层
应用层主要包括用户平台层和业务逻辑层。用户平台层包括企业运营监控平台、企业核心KPI预测引擎和供应链协同平台;业务逻辑层主要处理用户平台的业务逻辑以及通过己建立的数据分析模型,对数据存储中心的数据加以分析,并将结果呈现在决策分析平台。系统管理平台主要用于基础数据的日常维护以及基本功能的管理,管理模块包括人员管理,角色权限管理、系统功能菜单管理等。决策分析平台从业务逻辑层取得业务数据分析的结果,将结果以直观的报表和图表的形式呈现在平台上。
