
如今,AI技术面临数个难以攻克的核心挑战。其不仅需要大量数据以提供准确结果,同时也要求我们认真挑选数据内容以避免引入偏见,而且必须严格遵守日益苛刻的数据隐私法规。过去几年以来,围绕这些挑战诞生出一系列解决方案——包括用于帮助识别并减少偏差/偏见的各类工具、用户数据匿名化方案以及用于保证仅在用户同意时收集数据的管理框架等等。然而,每一种解决方案都有着自己的问题与短板。
如今,我们正迎来合成数据这一新兴行业,有望全面破除上述困局。合成数据是指由计算机人工生成的数据,可用于替代自现实世界中采集的真实数据。
合成数据集必须与真实数据集拥有相同的数学与统计学属性,但不可明确指代真实个体。大家可以将其理解为真实数据的一种数字化镜像,能够在统计学层面反映实际情况。如此一来,我们就可以在完全虚拟的场域当中训练AI系统,并更轻松地针对医疗保健、零售、金融、运输乃至农业等各类用例实现数据定制。
由此掀起的革命浪潮正在孕育当中。StartUs Insights去年6月发布的研究结果表明,已经有50多家供应商开发出合成数据解决方案。但在具体介绍领先厂商之前,我们先来了解合成数据能够解决哪些具体问题。
真实数据带来的大麻烦
过去几年以来,人们越来越关注数据集中的固有偏差/偏见如何在无意之间给AI算法带来永久存在的系统性歧视。根据Gartner公司的预测,到2022年,由数据、算法或AI项目管理团队引入的偏差/偏见将在所有错误交付结果中占据85%的比例。
AI算法的激增也引发了人们对于数据隐私的日益关注。为此,欧盟通过GDPR、加利福尼亚州颁布州内隐私法案,弗吉尼亚州最近也着手制定更为严苛的消费者数据隐私与保护条款。
相关法律的出台,使消费者能够更好地控制其个人数据。例如,弗吉尼亚州的新法律向消费者授予访问、更正、删除及获取个人数据副本的权利,同时也允许消费者随时拒绝企业销售其个人数据、或者出于针对性广告发布等目的对个人数据/资料进行算法访问的行为。
通过限制信息访问渠道,个人信息确实得到了有效保护,但这同时也将牺牲算法的预测效果。要获得高准确性AI算法,模型希望数据供应越多越好;而如果得不到充足的数据,则AI优势在实际应用(例如协助医学诊断及药物研究)方面的表现也可能受到影响。
另一种隐私问题解决方案则是消费者信息匿名化。例如,我们可以通过掩蔽或消除身份特征(例如删除电子商务交易记录中的姓名、信用卡号,或者清除医疗记录中的身份内容等)实现个人数据匿名化。但越来越多的证据表明,即使对某一数据源完成匿名处理,对方仍能够利用不慎泄露的其他消费者数据集实现内容关联与还原。实际上,通过合并来自多个来源的数据,即使经过一定程度的匿名化,恶意方仍然能够整理出令人惊讶的清晰身份形象。在某些特定情况下,对方甚至能够直接关联公共来源数据,在无需任何恶意攻击的前提下完成身份定位。
合成数据解决方案
合成数据承诺在实现AI优势的同时,消除各类负面影响。除了将真实个人数据排除在外,合成数据还强调纠正现实场景中产生的种种偏差/偏见,由此实现超越真实数据的素材质量。
除了高度依赖个人数据的应用场景之外,合成数据还有其他多种用途。其一就是复杂的计算机视觉建模,这里往往涉及多种因素的实时交互。我们可以使用由高级游戏引擎合成的视频数据集创建出超逼真图像,用以描绘自动驾驶场景中可能发生的各种事件,由此获得现实场景下几乎不可能捕捉到、或者可能极度危险的图像或视频。这些合成数据集的出现,极大提升并改善了自动驾驶系统的训练效率与效果。
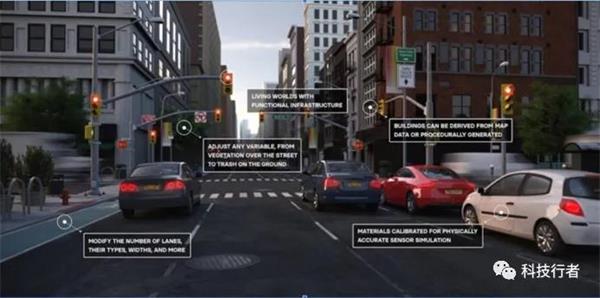
图:使用合成图像训练自动驾驶车辆算法
颇为讽刺的是,用于构建合成数据的主要工具之一,恰巧与创建Deepfake深度伪造视频的工具相同。二者均使用到生成对抗网络,即GAN。GAN的本质在于创建两套神经网络,其一生成合成数据,其二则尝试检测合成数据是否真实。在整个操作循环当中,生成器网络将不断改善数据质量,直到分类器无法找出真实数据与合成数据之间的差异为止。
新兴生态系统
Forrester Research最近确定了多项关键技术,其中就将合成数据列为实现“AI 2.0”的必要因素之一,使其能够从本质上扩展AI的应用可能性。通过更完备的数据匿名化功能以及强大的固有偏差/偏见纠正能力,再加上批量创建以往难于获取的数据,合成数据有望成为多种大数据应用的效率之选。
合成数据还具有其他一系列优势:您可以快速创建数据集,并重复使用这些标记数据实现监督学习。另外,合成数据不像真实数据那样需要清洗与维护,因此至少从理论上讲,这项技术能够节约下大量时间与成本。
目前,市场上已经出现了几家信誉卓著的合成数据厂商。IBM表示其正着力推进数据制造业务,希望通过创建合成测试数据以消除机密信息泄露风险、解决GDPR及其他法规问题。AWS则开发出内部合成数据工具,通过生成的数据集不断对Alexa进行新语种训练。微软还与哈佛大学合作开发一款工具,其中的合成数据功能可以增强各研究部门之间的协作。虽然形势一片大好,但合成数据仍处于起步阶段,市场走向将在很大程度上由新兴企业的发展所决定。
下面,我们整理出一份简单的合成数据行业早期领导厂商清单,具体信息来自G2与StartUs Insights等行业研究组织。
1、AiFi—使用合成数据模拟零售商店与购物者行为特征。
2、AI.Reverie—生成合成数据以训练计算机视觉算法,借此实现活动识别、目标检测与划分。应用范围包括智慧城市、稀有物质示板识别、农业以及智能零售等场景。
3、Anyverse—使用原始传感器数据、图像处理功能以及汽车行业的定制化激光雷达创建合成数据集,借此实现场景模拟。
4、Cvedia—创建合成图像,简化标记、真实与视觉数据的收集流程。这套模拟平台使用多种传感器合成逼真环境,借此创建出丰富的实证数据集。
5、DataGen—室内环境用例,支持智能商店、家用机器人及增强现实等场景。
6、Diveplane—为医疗保健行业创建与原始数据具有相同统计学属性的合成“孪生”数据集。
7、Gretel—为开发人员提供与GitHub数据等效的合成数据集,其中包含与原始数据源相同的洞见。
8、Hazy—生成数据集以增强欺诈与洗钱检测能力,用以打击各类金融犯罪。
9、Mostly AI—专注于保险与金融领域,也是最早创建合成结构化数据的厂商之一。
10、OneView–开发虚拟合成数据集,用于通过机器学习算法分析地球观测图像。
来源丨VentureBeat
编译丨科技行者
