本文来自微信公众号“AI芯天下”,作者/方文三。
大模型的发展开启了AIGC时代,没有大模型的AI已经是上一代的AI,缺乏竞争力的AI;
技术是AI每次革命性发展的起点,商业应用是发展的加速器,AI的持久发展看商业落地。
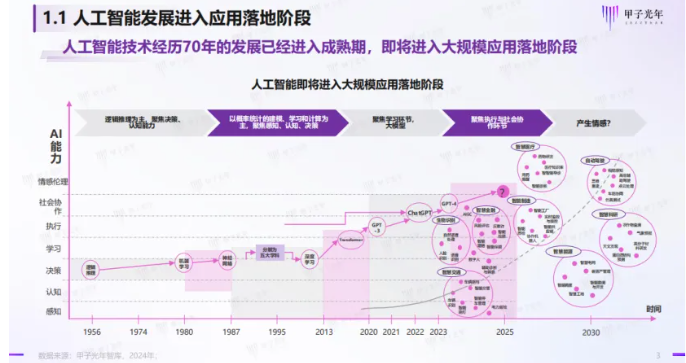
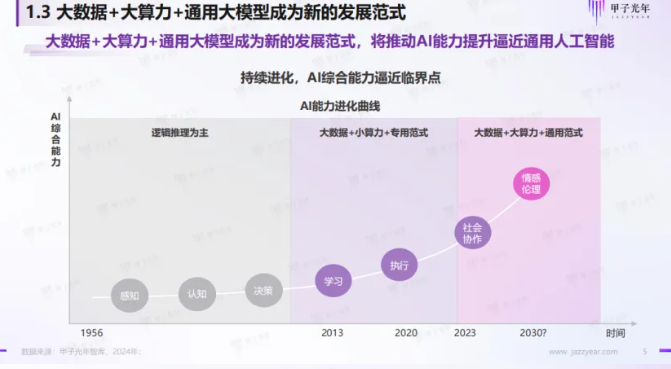
人工智能技术进化出七大核心能力,实现从“解放四肢”到“解放大脑”的升级。
第一阶段AI以逻辑推理为主,AI能力主要聚焦决策和认知;
第二阶段AI注重概率统计的建模、学习和计算,AI能力开始聚焦感知、认知和决策;
第三阶段AI聚焦学习环节,注重大模型的建设,AI能力覆盖学习和执行;
第四阶段则聚焦执行与社会协作环节,开始注重人机交互协作,注重人类对人工智能的反馈训练。
当下正处于第四阶段,这一阶段从2020年开始,代表性事件是GPT-3的发布,突破了以往模型在自然语言处理领域的限制,为语言模型的进一步发展提供了强有力的基础,也为实现智能化的语言交互和人机对话打开了全新的可能性,是人工智能发展的一个关键节点。
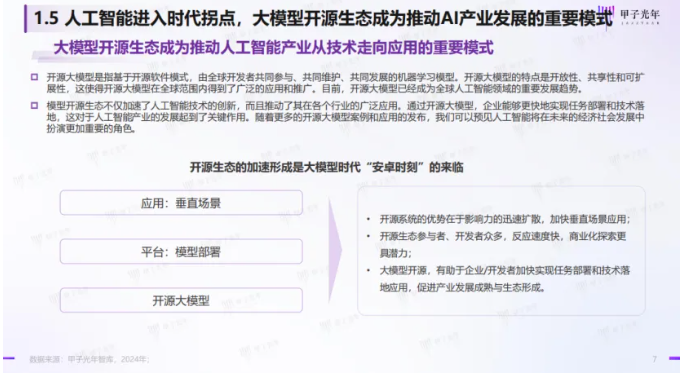
鹏程·盘古模型是全球首个全开源2000亿参数的自回归中文预训练语言大模型,在知识问答、知识检索、知识推理、阅读理解等文本生成领域表现突出。
文心大模型ERNIE是百度发布的产业级知识增强大模型,涵盖了NLP大模型和跨模态大模型。2019年3月,百度开源了国内首个开源预训练模型文心ERNIE 1.0,此后在语言与跨模态的理解和生成等领域取得一系列技术突破,并对外开源与开放了系列模型,助力大模型研究与产业化应用发展。
通义千问的大语言模型已经实现全尺寸开源——包括18亿、70亿、140亿、720亿7个参数,不同规模和尺寸的模型,可拓宽应用场景。
针对大模型技术,国内企业与欧美国家存在差距,主要体现在底层架构设计和硬件技术方面。在底层架构设计方面,国内尚无类似的底层架构,大模型的预训练方面只能“在别人的地基上盖房子”。
在硬件技术方面,美国占据绝对领先地位,我国自研能力不足,对美国进口依赖程度高,存在“卡脖子”风险。
以下是《2024人工智能开源大模型生态研究》部分内容: