
本文来自微信公众号“IT时报”,作者/孙妍。
这届618的价格战是大模型打响的。
字节跳动打前阵,BAT前后脚跟进,主力模型降价97%,百万tokens低至1元,大模型卷至“厘时代”,免费,全面免费,永久免费……堪称炸场级别的降价力度已经许久未见,像是重演“百团大战”“O2O混战”“网约车补贴大战”“云项目1元中标”似的,点燃了行业的战火。
8家大模型集体降价
字节跳动和BAT集体入局大模型价格战。据《IT时报》不完全统计,5月以来,已有8家国内外大模型宣布大降价,包括幻方量化、智谱、GPT-4o、字节豆包、阿里通义千问、百度文心一言、腾讯混元和科大讯飞星火等。
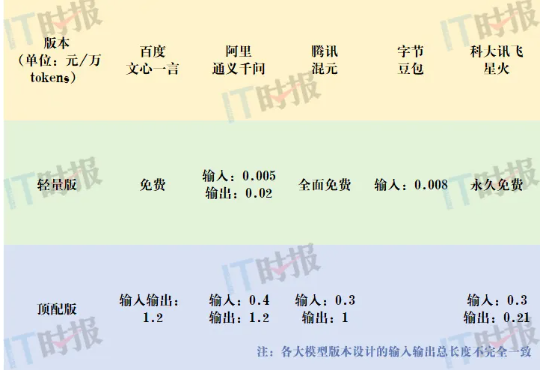
5月15日,字节跳动挑起大模型价格战,豆包通用模型pro-32k版输入价格降至0.0008元/千tokens,豆包通用模型pro-128k版输入价格降至0.005元/千tokens。这意味着,1元就能买到豆包主力模型的125万tokens,大约是200万个汉字,相当于3本《三国演义》。
大模型通常以“元/千tokens”为计费单元,字节豆包将以分为单位的使用成本,直接打到了以厘为单位,真正挑起了价格战。
阿里和百度在5月21日前后脚跟进,阿里通义千问GPT-4级主力模型Qwen-Long的输入价格降至0.0005元/千tokens,直降97%,降价后约为GPT-4价格的1/400,击穿全球底价。这意味着,1元就能买到200万tokens,相当于5本《新华字典》。百度文心一言则直接宣布两大主力模型全面免费且立即生效,分别为今年3月推出的轻量级大模型ERNIE Speed和ERNIE Lite,支持8k和128k上下文长度。
5月22日,腾讯混元大模型全面降价,主力模型之一混元-lite模型价格从0.008元/千tokens调整为全面免费,API输入输出总长度计划从目前的4k升级为256k。混元-standard、具备处理超38万字符超长文本能力的混元-standard-256k以及最高配置万亿参数模型混元-pro三款大模型的API输入输出价格全面降低,最大降价幅度为87.5%。
同一天,科大讯飞推出业界首个“永久免费”的大模型——星火大模型lite,顶配版讯飞星火Max API价格则低至0.21元/万tokens,相比较而言,百度文心一言ERNIE4.0和阿里通义千问Qwen-Max的定价为1.2元/万tokens,讯飞星火顶配版只为百度、阿里的五分之一。
真正让国内大模型神经紧张的是,OpenAI从2023年年初至今,已经进行了4次降价,5月13日发布的GPT-4o不仅实现了性能跃升,价格也下降了50%。
巨头烧钱换数据
“当前大模型的定价已经没办法覆盖成本,但大模型厂商为何还要降价?主要目的是为了收集数据。”在主攻AI Agent的澜码科技CEO周健看来,GPT-4o的策略是对公众免费,对开发者收费降低一半,让公众多用,从而收集多轮对话等交互数据,这比静态数据更能快速提高模型能力,而国产大模型也同样处于“烧钱换数据”的阶段。
以往,LLM类的大模型没有时间概念,但GPT-4o已经解决短时记忆问题,能在对话中感知情绪、跟随指令或被人打断,可以用不同情绪的语音讲故事,不过长时记忆能力和社会智能还是不够。
周健打了一个比方,即使GPT-4o像爱因斯坦一样聪明,它也不能胜任一家上市公司的CFO,因为这个角色需要强大的长时记忆,根据不同沟通总结和分析整个公司的组织结构、权力结构等,所以它现阶段还是一个“缸中之脑”。

图源:unsplash
除了对公众免费以外,OpenAI还在用硬件来收集线下销售、猎头等与客户交流的数据。发布GPT-4o后,OpenAI与美国知名论坛、美股散户大本营Reddit合作,收集社区内容来训练大模型。所以,收集这些真实动态数据的目的,是为了让大模型变得更像人,可以多轮对话、长时记忆、熟知社会交往逻辑。
在上海人工智能研究院高级研发经理徐弘毅看来,大模型打下市场的关键也是数据。当前,大模型的竞争已从算力过渡到优质数据,优质的中文数据十分稀缺,而动态交互数据更显重要。
中文教科书只有英文的十分之一,中文的静态知识数据闭环天然弱于英文,所以只能从动态数据上实现量的突破,只有让真实的人来用,才能收集动态数据。另外,全球70%的数据仅停留在免费公开数据集的层面,要想让大模型掌握专业知识,只能不断吸引各行各业的开发者注入垂直领域的数据集。
低价,无疑是最好的吸引方式。当然,前提是保证相同的质量甚至更快的速度。从去年的GPT-4到今年的GPT-4o,第一个token响应速度快了6倍,但调取价格便宜了12倍。国外厂商以速度博眼球,而国内厂商以价格博市场。不过,也有业内人士和媒体质疑,大模型厂商抛开并发量谈价格“并不科学”,如果不能支持高并发量,就无法保证输出速度和质量。
“大模型集体降价不仅仅是市场策略,更是拐点到来的信号。”曾负责国内首个基于时空数据信用债风险模型的北京市特聘专家杨晓静认为,大模型集体降价的原因有三:首先是基于统筹补贴等政策,云、算力芯片等成本降低带来了技术红利;其次是大模型厂商对规模增长的信心,2024年初,每天国内所有大模型的API调用量不超过1亿次,但预计今年底将有100倍增长;最后是吸引开发者,从而快速向千行百业覆盖,而目前国内AIGC的用户渗透率仅为6%左右。
“字节想通过豆包大模型推火山引擎和云服务,实际上,视频等内容才是掘金之处。”杨晓静也认为,云、算力、大模型、内容、数据是一条链条,打通后就能形成一个生态闭环,这也是巨头烧钱换数据的内在逻辑。
价格战或向C端传导
“百模大战”真正进入实战阶段,据《IT时报》记者观察,此次降价的主体是文本大模型,主要面向开发者和企业,还未传导至C端用户层面。下一阶段,国内大模型可能会迎来C端用户层面和多模态大模型的降价。让C端用户用得起甚至免费用,从而让大模型变得越来越好用。
在国外,OpenAI以性能优势几乎形成了垄断。OpenAI最新推出的多模态大模型GPT-4o目前仅开放了文本和图像功能,但未来将向C端用户全部免费开放。并支持语音和视频的输入输出。
GPT-4o演示
当前,若要在ChatGPT上体验Plus版本,仍要升级到19.99美元/月的会员。据应用智能公司Appfigures统计,ChatGPT的App净收入在GPT-4o发布当天跃升22%,5月21日的净收入达到90万美元,接近该应用日均收入的两倍。
“国内大模型竞争越发激烈,在没有决出绝对胜出者之前,降价趋势不会停止,甚至是指数级下降。”周健认为。
杨晓静也认为,海量用户和庞大的消费者市场还将加速成本下降。
价格战的背后,是中国大模型想要抓住数据和场景的红利,缩短甚至超越美国的大模型发展速度。数据为核、场景牵引是中国在移动互联网、5G弯道超车的“制胜法宝”,那在大模型时代,这条反超路径是否依然可行?
2024年被认为是大模型商业化落地的元年。IDC预测,2026年中国AI大模型市场规模将达到211亿美元,人工智能将进入大规模落地应用关键期。据徐弘毅的观察,国内大模型更倾向于深入应用场景这条路径,靠业务打下基础。
中美的大模型发展差距一直存在争议,有人说差距是一年半,也有人说是半年。近期,斯坦福大学发布的《2024人工智能指数报告》显示,2023年发布的全球149个知名大模型中,美国占61款,中国占15款,据世界第二,追赶速度较快。而中国的人工智能专利数量占60%,领先其他国家。
想要缩短中美大模型发展差距,中国大模型还得要靠应用场景取胜。
降价,会直接调动企业使用大模型的积极性。根据以往开发信用债风险模型和智能投顾的经验,杨晓静做了一个测算,2005年至2022年18年间,A股市场中累积了82.5万份券商公司类研报,若每份以1万字计算,整体约85亿字,相当于3.4亿个tokens。做智能投研大模型的开发者,如果原先通用大模型的价格来调取API,一次需要花费3.4万元,现在只需要花费1700元。
据杨晓静判断,在金融领域,智能客服这个刚需领域将最快看到AI的注入和降价的影响,调用成本降低后,服务的用户规模也将快速提升。
此外,中国是全球最大的工业机器人安装国,安装量占全球50%,中国AI大模型企业应该抓住工业化升级的时机。“AI服务要变得像水电一样易用易得,像5G一样泛在化,才能像5G一样弯道超车,实现全球引领。”杨晓静说道。
