本文来自微信公众号“半导体产业纵横”,作者,丰宁。
传统芯片架构面临着“存储墙”、“功耗墙”及“算力墙”等严峻挑战,它们是什么?存算一体芯片是什么?它又是如何解决这些问题的?
近年来,随着AI应用场景的爆发式增长,AI算法对算力的需求急剧上升,这一增速已显著超越了摩尔定律所预测的硬件性能提升速度。传统的计算芯片,在计算资源、处理时延以及功耗控制方面,逐渐显现出难以满足AI高并行计算需求的局限性。
在智能芯片领域,传统的冯·诺依曼架构以计算为核心,处理器与存储器之间的物理分离导致了大规模数据频繁迁移,这进一步限制了AI芯片的整体性能。因此,传统芯片架构面临着“存储墙”、“功耗墙”及“算力墙”等严峻挑战,难以满足AI应用对于低时延、高能效以及高可扩展性的迫切需求。
针对上述一系列问题,业内给出了一种名为“存算一体”的解决方案。
芯片发展面前的三堵墙
首先一起了解一下什么是“存储墙”。
存储墙指的是内存性能严重限制CPU性能发挥的现象。在过去的20多年中,处理器的性能以每年大约55%速度快速提升,而内存性能的提升速度则只有每年10%左右。长期累积下来,不均衡的发展速度造成了当前内存的存取速度严重滞后于处理器的计算速度,内存瓶颈导致高性能处理器难以发挥出应有的功效,这对日益增长的高性能计算形成了极大的制约。这种严重阻碍处理器性能发挥的内存瓶颈命名为"内存墙",也叫“存储墙”。

存储计算“剪刀差”来源:OneFlow公司,安信证券研究中心
伴随着“存储墙”问题同时出现的,是大量能耗消耗在了数据传输过程中,导致芯片的能效比显著降低,即“功耗墙”问题。
“功耗墙”的问题主要是因为随着计算系统对内存带宽需求的不断增加,以及对更高容量和更快访问速度的追求,传统DRAM和其他类型内存的功耗急剧上升,最终会达到一个无法通过简单增加功率预算来解决的临界点。

这一方面是因为数据从DRAM搬运到CPU需要跨过多个层级的存储层次,包括L1、L2、L3缓存。有研究表明:在特定情况下,将1比特数据从DRAM搬运到CPU所消耗的能量比在CPU上处理这个比特所需的能量还要高几倍到几十倍。
根据英特尔的研究表明,当半导体工艺达到7nm时,数据搬运功耗高达35pJ/bit,占总功耗的63.7%。数据传输造成的功耗损失越来越严重,限制了芯片发展的速度和效率。
“编译墙”问题隐于二者之中,极短时间下的大量数据搬运使得编译器无法在静态可预测的情况下对算子、函数、程序或者网络做整体的优化,手动优化又消耗了大量时间。
过去,凭借先进制程不断突破,这三座“大山”的弊病还能通过快速提升的算力来弥补。
但一个残酷的现实是,过去数十年间,通过工艺制程的提升改善芯片算力问题的“老办法”正在逐步失效——摩尔定律正在走向物理极限,HBM、3D DRAM、更好的互联等传统“解法”也“治标不治本”,晶体管微缩越来越难,提升算力性能兼具降低功耗这条路越走越艰辛。
随着大模型时代来临,激增的数据计算,无疑进一步放大了“三道墙”的影响。
而存算一体技术的出现,是对上述难题的有力回应。
存算一体带来了哪些惊喜
从存算一体技术的原理来看,存算一体的核心是将存储功能与计算功能融合在同一个芯片上,直接利用存储单元进行数据处理——通过修改“读”电路的存内计算架构,可以在“读”电路中获取运算结果,并将结果直接“写”回存储器的目的地址,不再需要在计算单元和存储单元之间进行频繁的数据转移,消除了数据搬移带来的消耗,极大降低了功耗,大幅提升计算效率。
正因此,存算一体技术可以有效地克服冯·诺依曼架构瓶颈。
那么存算一体技术凭借其技术优势,在实际应用中都可以带来哪些效能提升?
存算一体芯片在特定领域可以提供更大算力(1000TOPS以上)和更高能效(超过10-100TOPS/W),明显超越现有ASIC算力芯片。存算一体技术还可以通过使用存储单元参与逻辑计算提升算力,这等效于在面积不变的情况下规模化增加计算核心数。
在能耗控制方面,存算一体技术可以通过减少不必要的数据搬运将能耗降低至之前的1/10~1/100。提升了计算效率、降低了功耗,存算一体自然也能带来更好的成本回报。
存算一体技术的分类
根据存储与计算的距离远近,将广义存算一体的技术方案分为三大类,分别是近存计算(Processing Near Memory,PNM)、存内处理(Processing In Memory,PIM)和存内计算(Computing in Memory,CIM)。
近存计算是一种较为成熟的技术路径。它利用先进的封装技术,将计算逻辑芯片和存储器封装到一起,通过减少内存和处理单元之间的路径,实现高I/O密度,进而实现高内存带宽以及较低的访问开销。近存计算主要通过2.5D、3D堆叠等技术来实现,广泛应用于各类CPU和GPU上。
存内处理则主要侧重于将计算过程尽可能地嵌入到存储器内部。这种实现方式旨在减少处理器访问存储器的频率,因为大部分计算已经在存储器内部完成。这种设计有助于消除冯·诺依曼瓶颈带来的问题,提高数据处理速度和效率。
存内计算同样是将计算和存储合二为一的技术。它有两种主要思路。第一种思路是通过电路革新,让存储器本身就具有计算能力。这通常需要对SRAM或者MRAM等存储器进行改动,以在数据读出的解码器等地方实现计算功能。这种方法的能效比通常较高,但计算精度可能受限。
其中,近存计算和存内计算是目前存算一体技术实现的主流路径。
存储介质的主要选择
存算一体芯片的存储介质主要可分为两大类:一种是易失性存储器,即在正常关闭系统或者突然性、意外性关闭系统的时候,数据会丢失,如SRAM和DRAM等。
另一种是非易失性存储器,在上述情况下数据不会丢失,如传统的闪存NOR Flash和NAND Flash,以及新型存储器:阻变存储器RRAM(ReRAM)、磁性存储器MRAM、铁变存储器FRAM(FeRAM)、相变存储器PCRAM(PCM)等。
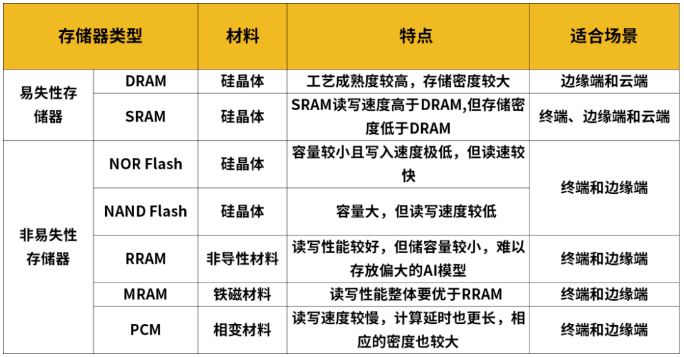
那么,该如何选择合适的技术路径,这些技术路径又有何特点、壁垒和优势呢?
从器件工艺成熟度来看,SRAM、DRAM和Flash都是成熟的存储技术。
Flash属于非易失性存储器件,具有低成本优势,一般适合小算力场景;DRAM成本低,容量大,但是可用的eDRAM IP核工艺节点不先进,读取延迟也大,且需要定期刷新数据;SRAM在速度方面具有极大优势,有几乎最高的能效比,容量密度略小,在精度增强后可以保证较高精度,一般适用于云计算等大算力场景。
在制程工艺方面,SRAM可以在先进工艺上如5nm上制造,DRAM和Flash可在10-20nm工艺上制造。
在电路设计难度上,存内计算DRAM>存内计算SRAM>存内计算Flash。在存内计算方面,SRAM和DRAM更难设计,它们是易失性存储器,工艺偏差会大幅度增加模拟计算的设计难度,Flash是非易失存储器,他的状态是连续可编程的,可以通过编程等方式来校准工艺偏差,从而提高精度。而近存计算的设计相对简单,可采用成熟的存储器技术和逻辑电路设计技术。
除成熟的存储技术外,学术界也比较关注各种RRAM在神经网络计算中的引入。RRAM使用电阻调制来实现数据存储,读出电流信号而非传统的电荷信号,可以获得较好的线性电阻特性。但目前RRAM工艺良率爬坡还在进行中,而且依然需要面对非易失存储器固有的可靠性问题,因此目前还主要用于端侧小算力和边缘AI计算。
存算一体芯片的适用场景
小算力场景:边缘侧对成本、功耗、时延、开发难度非常敏感
中早期的存算一体芯片算力较小,从小算力1TOPS开始往上走,解决的是音频类、健康类及低功耗视觉终端侧应用场景,AI落地的芯片性能及功耗问题。比如:AIoT(人工智能物联网)的应用。
众所周知,碎片化的AIoT市场对先进工艺芯片的需求并不强烈,反而更青睐低成本、低功耗、易开发的芯片。
存算一体正是符合这一系列要求的芯片。
首先,存算一体技术能够减少数据在存储单元和计算单元之间的移动,从而显著降低能耗。例如,传统架构中,大量的数据传输会消耗大量能量,而存算一体架构可以避免这种不必要的能耗,使得像电池供电的物联网设备能够更长时间地运行。
其次,通过减少数据传输和提高集成度,存算一体技术可以降低芯片的制造成本。对于大规模部署的AIoT设备来说,成本的降低有助于更广泛的应用推广。
最后,存算一体芯片还可以大幅提高运算速度并节省空间,而这两项也是给AIoT应用带来助力的两大因素。
大算力场景:GPU在算力和能效上都无法同时与专用加速芯片竞争
目前云计算算力市场,GPU的单一架构已经不能适应不同AI计算场景的算法离散化特点,如在图像、推荐、NLP领域有各自的主流算法架构。
随着存算一体芯片算力不断提升,使用范围逐渐扩展到大算力应用领域。针对大算力场景>100TOPS,在无人车、泛机器人、智能驾驶,云计算领域提供高性能大算力和高性价比的产品。
此外,存算一体芯片还有一些其他延伸应用,比如感存算一体、类脑计算等。
存算一体芯片大规模落地的时刻尚未明确,但这一天的到来值得我们期待。技术的演进从不停止,市场的需求也在不断变化,当各种条件成熟之际,或许就是存算一体芯片大放异彩之时。
