一、背景介绍
此前,阿里云和滴滴等企业的云服务出现故障,在业界造成比较大的影响。这再次提醒了我们,如果只依赖于单一云服务商,一旦其服务出现问题,将面临重大业务隐患。
随着数字化进程的推进,企业云服务日趋重要。但是,单一云服务商本身也面临各种风险,例如硬件故障、系统升级问题等,都可能导致短期或长期性的服务中断。特别是大规模型企业,其任何一次云服务中断都可能给业务和用户带来极大影响。同时,随着企业业务的扩张,多地域部署也变得十分必要。但如果依赖单一云服务商,就难以满足不同地域和应用规模的需求。因此,未来云服务需要实现跨云能力,这不仅可以提高系统可用性和灾备能力,也更好支持企业跨地域和跨应用场景下的业务发展。
BigInsights智能数据库系统是新一代云原生的数据库,具有多云部署的能力,可以打破了云服务提供商的限制,允许在不同的云上部署BigInsights分布式数据库集群,可彻底解决单一云服务故障对业务的影响,支持多云集群灵活部署,提供高可用性服务,从而完全避免数据丢失的风险,持续为应用程序提供数据库相关服务。
本文介绍了多云部署的BigInsights集群方案,解决单一云部署可能遇到的灾难性问题。此外,它还为企业提供了更大的灵活性,使其能够根据需要在不同的云平台上部署数据库,更好地满足业务需求。
二、技术架构
总体上,BigInsights支持多种架构,可以满足不同业务场景的高可用需求。
(一)跨云复制:
BigInsights可以在不同的云平台上进行部署,从而构建分布式数据库集群。这种架构可以提供高可用性和容错能力,确保即使一个云服务出现故障,数据库服务仍然可以继续运行。
多云复制具有许多好处,其中包括:
1)高可用性:通过在不同的云平台上部署应用程序和服务,可以确保即使一个云服务出现故障,其他云服务仍然可以继续提供服务,从而提高系统的可用性。
2)容错能力:多云部署可以提供更强的容错能力,因为即使一个云服务发生故障,其他云服务也可以继续提供服务,降低了系统发生故障的风险。
3)数据安全性:多云部署可以帮助企业在不同的云平台上备份和存储数据,从而提高数据的安全性和可靠性。
4)避免供应商锁定:多云部署可以避免企业对单一云服务提供商的依赖,降低了供应商锁定的风险,同时也提高了企业在谈判云服务价格和条款时的议价能力。
5)成本优化:通过多云部署,企业可以根据不同云服务提供商的定价和服务质量选择最优的解决方案,从而降低成本。
多云部署,BigInsights跨云复制使用xDCR架构,如下图所示:
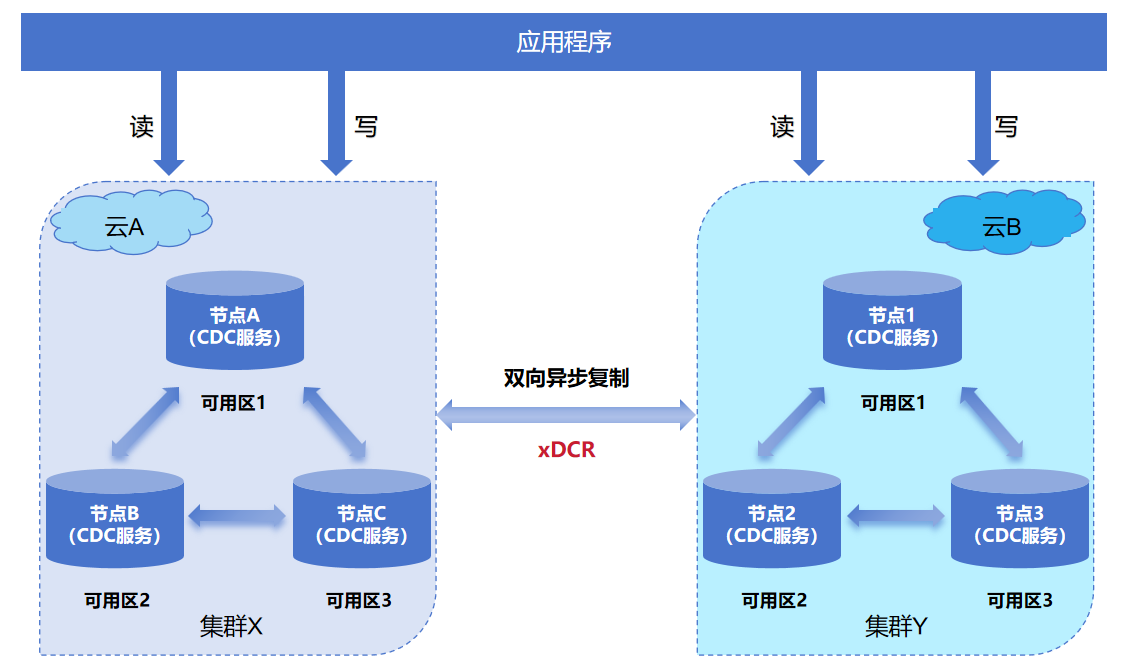
从上图中,在云A和云B两个集群间开启双向复制,写入云A上的集群X(源)的数据会复制到云B上的集群Y(目标)中;同理,写入云B上的集群Y(源)的数据会复制到云A上的集群X(目标)中。
(二)多云同步:
BigInsights还支持在云和云之间进行多云同步,以满足企业的特定需求。这种架构可以帮助企业在保护敏感数据的同时,利用公有云的弹性和灵活性。
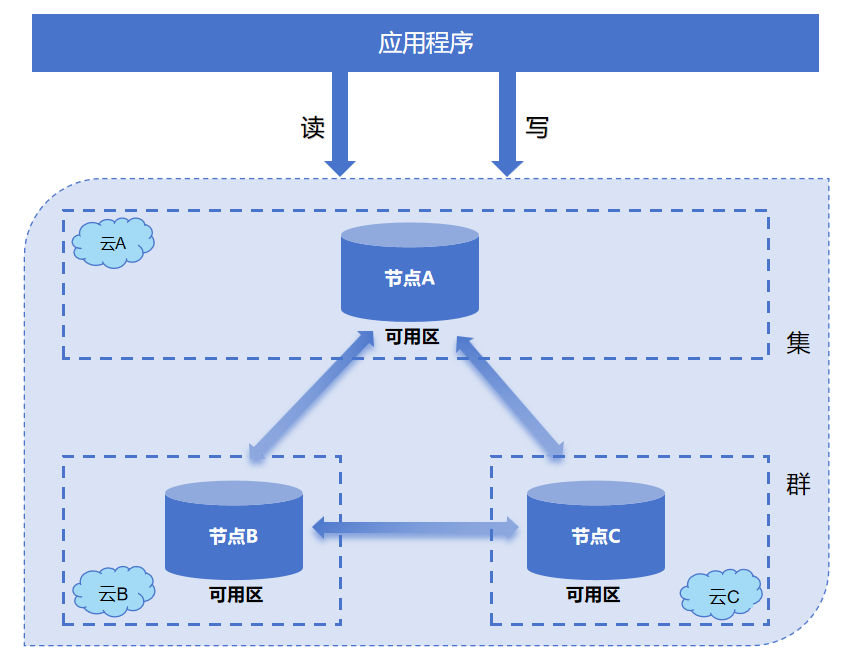
从上图中,有三个不同的云A,云B,云C,可分别在不同的云中,选择地域临近的可用区主机,构建集群。
(三)只读副本:
另外,我们也提供只读副本部署方式,除了基于核心分布式共识的复制外,BigInsights还扩展了Raft,以添加不参与写入但以异步方式获得数据的时间线一致副本的只取副本(也称为观察者节点)。
使用只读副本,可以在一个区域的多个区域或附近区域中复制主集群的数据,数据被异步复制到只读副本。
远程数据中心中的节点可以以只读模式添加,这通常用于某些工作负载无法容忍基于分布式共识的写入延迟的情况。
只读副本部署同时具有许多其它的好处,其中包括:
1)读写分离:主集群提供对业务的主要数据支撑,提供读与写的服务;而只读副本只提供读的服务。
2)读取延迟降低:可以在要运行应用程序的每个区域以及可以接受一点延迟的区域中设置单独的只读副本集群,来提供对不可忍受高延迟的读提供服务,通常可适用于BI(Business Intelligence)的支撑。
从上图中,有三个不同的云A,云B,云C,可分别在不同的云中,云A中的节点A,节点B,节点C,构建主集群,主集群的数据被异步复制到云B中的只读副本A,以及云C中的只读副本B。
(四)跨云分区:
针对于数据,我们还提供了行级地理分区部署方式。行级地理分区允许对用户表中的数据,按行级别,固定到特定的地理位置而进行细粒度控制。
这种部署方式将具有许多其它的好处,其中包括:
1.数据移动到离用户更近的位置,实现更低的延迟和更高的性能。
2.满足数据要求,以遵守《通用数据保护条例》(General Data Protection Regulation,简称“GDPR”)法规。
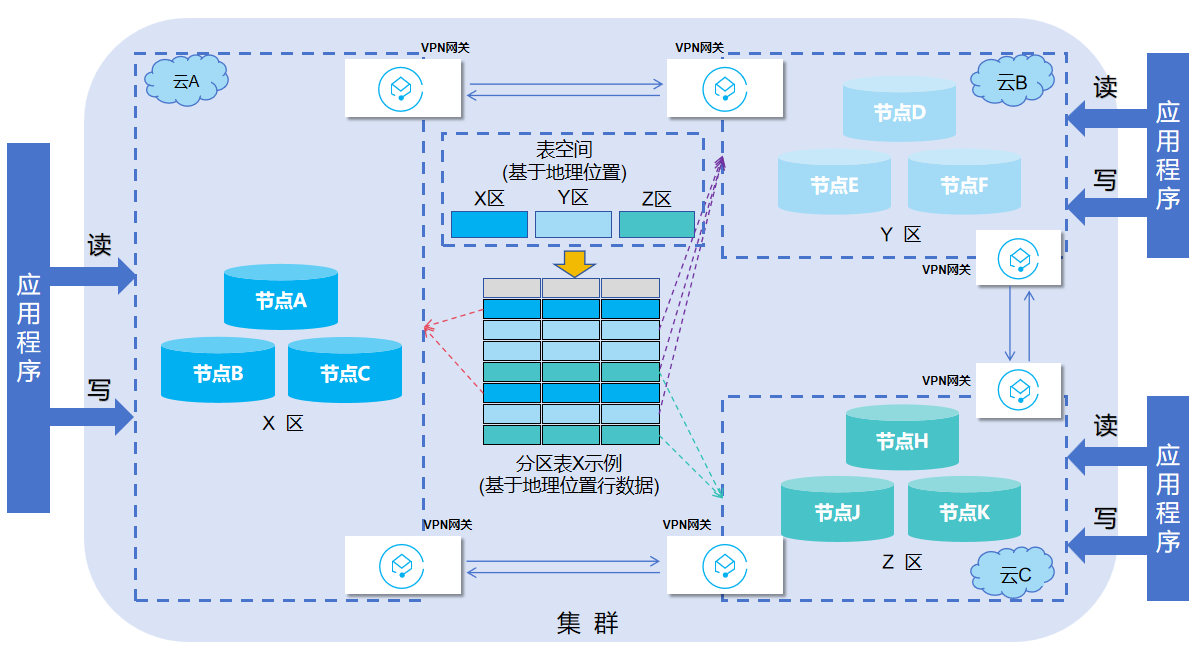
从上图中,有三个不同的云A,云B,云C,可分别在不同的云中,每一个云中各自包含有3个节点,共同构建为一个集群,集群中的数据存储在基于地理位置的分区表中,在这种部署中,用户可以以低延迟访问数据,因为数据位于地理位置较近的服务器上,查询不需要访问地理位置较远的数据。
这些架构可以根据企业的具体需求进行定制和调整,以满足不同的集群部署需求。
三、部署方案
(一)跨云复制xDCR
xDCR是BigInsights提供的一种用于灾难恢复的异步复制方案,架构中包含了CDC服务,它允许在两个集群之间设置一个或多个单向CDC复制流。对于每个复制流,数据都从源(生产者)集群复制到目标(消费者)集群。这种复制是在BigInsights的数据存储引擎级别完成的,可以将源集群中新提交的写入异步复制到目标集群。
在这种架构中,xDCR的设计目的是为了提供一种可靠的灾难恢复解决方案。通过将数据异步复制到目标集群,即使源集群发生故障或不可用,目标集群仍然可以保持数据的完整性和可用性。这种异步复制的方式可以确保数据在不同集群之间的一致性,并提供灾难恢复和数据备份的功能。
当两个集群之间创建的两个单向复制流,每个方向一个(从集群A到集群B,从集群B到集群A),则称之为双向复制。双向复制确保了两个集群之间的数据一致性,并避免了无限循环的问题。在这种设置中,每个集群都充当生产者和消费者,确保了数据在两个集群之间的双向同步。
通过设置双向复制,确保了任何一个集群中写入的内容都将被复制到另一个集群中,从而保证了数据的一致性。同时,由于数据只会异步复制一次,避免了无限循环的情况,确保了数据复制的有效性和可靠性。
综上所述,可以看到,xDCR的方案非常灵活,当一个集群不可用时,另一个集群保存有完整的数据,因此可以对外部应用继续提供完整的数据库服务。这种灵活性使得xDCR成为一种可靠的灾难恢复解决方案,同时也降低了集群之间的依赖性,提高了整体系统的稳定性和可靠性。
但仍然需要注意的一点是:在设置双向复制的两个集群时,选择距离较近的区域可以帮助降低故障切换的延迟,并且有助于减少网络延迟,提高数据传输的效率和性能,从而提高集群的性能;这对于确保数据同步和业务连续性都非常重要。
采用xDCR(双向异步复制架构)的方案通常包括以下主要实现步骤:
1.借助BigInsights提供的命令工具bm-admin,获取集群A的UUID。
2.需要复制的表,需在集群A和集群B中均进行相同的表定义创建,并需借助命令工具bm-admin来获取复制的表ID。
3.借助命令工具bm-admin,及指定源集群与目标集群来建立单向复制。
4.双向复制,重复步骤1到3,仅仅需要做的是,将第3步骤中的源集群作为目标集群,而目标集群作为源集群,即源与目标互换。
(二)多云同步
部署方式类似于普通集群部署,直接配置一个集群的多个节点在不同的云服务器里,多个副本通过RAFT协议数据同步。
(三)只读副本
采用只读副本部署(异步复制架构)的方案通常包括以下主要实现步骤:
1.启动主集群的BMMaster服务。
2.使用bm-admin命令行工具的相关modify_placement_info命令,更改主集群的placement相关信息。
3.使用bm-admin命令行工具的相关add_read_replica_placement_info命令,定义只读副本的placement相关信息。
4.启动主集群的BMServer服务,其中包括在上述第二步骤中的placement相一致的信息。包括有:--placement_cloud placement_cloud
--placement_region placement_region
--placement_zone placement_zone
--placement_uuid live_id
5.启动只读副本的BMServer服务,其中包括在上述第三步骤中的placement相一致的信息。包括有:--placement_cloud placement_cloud
--placement_region placement_region
--placement_zone placement_zone
--placement_uuid read_replica_id
(四)跨云分区
1.方案的集群部署方式类似于普通集群部署,但需要进行以下必要的主要实现步骤:
2.使用CREATE TABLESPACE创建表空间:为要将数据划分到的每个地理位置各自创建独立的表空间,需要定义placement相关信息,其中包括:cloud,region,zone等信息。
3.创建分区表:创建包含地理位置列的基于List分区方式的父表,该地理位置列用于将数据分区到每个地理位置,之后,在父表下为每个所需的地理位置各自创建一个分区表,并将每个分区表分配给第一步中创建的适用的表空间。
四、结语
如果您需要关于BigInsights集群的详细部署信息,可以参考贝格迈思官网、微信公众号或其他相关资源中提供的文章或文档,以获取更多关于部署、配置和最佳实践的信息。在实施混合部署或多云部署时,充分了解各种环境下的最佳实践和安全配置,对确保系统的稳定性和可靠性至关重要。
