
本文来自微信公众号“安永EY”,作者/安永。
人工智能的高速发展及应用,使我们正在步入人工智能驱动的时代。大数据是人工智能技术研发和落地的基础,随着数据在各场景中被收集和利用,数据安全和隐私保护面临着巨大的风险与挑战。
本文将对数据安全风险群体及场景进行分析,并结合数据安全及隐私保护相关的法规要求及行业最佳实践,从管理和技术两个层面分享我们的观点与建议。
一 谁在面临人工智能带来的数据安全挑战?
(一)学生
人工智能技术已成熟的应用到了学生的日常学习中,在线课程门户Study.com对1000名美国大学生进行了调查,调查结果显示美国大学约89%的学生使用智能对话机器人完成作业,53%的学生使用其撰写论文,48%的学生使用其完成考试。为了避免学生过于依赖此类工具,防止作弊,多个国家的学校已经开始禁止学生使用。
(二)企业员工
随着人工智能技术在企业的应用与普及,企业的涉密人员正在成为数据安全风险的主要群体,与智能对话机器人分享的机密信息可能被用于未来人工智能模型的迭代训练,这将可能会导致该模型输出的内容可能包含机密信息,例如用户隐私数据、企业机密数据等,从而造成敏感数据泄漏的风险。
►2022年11月,某国际大型电子商务公司律师就警告员工不要与智能对话机器人分享机密数据,因为这将会被其用来作为迭代训练的数据。
►2023年1月,新一代人工智能对话机器人母公司一名员工在内部论坛上询问是否可以用智能对话机器人工作时,其首席技术官办公室的一位高级程序员回复,只要不与其分享机密信息,是可以被允许的。
二 人工智能带来了哪些数据安全风险?
(一)隐私合规风险
目前智能对话机器人的使用条款尚不明确,其中虽然会提示用户将收集使用过程中的信息,但并没有说明收集信息的具体用途;虽然承诺删除所有个人身份信息,但未说明删除方式。这将会为人工智能企业带来合规风险,同时为用户带来个人信息泄露或滥用的风险。
例如根据GDPR第17条,个人有权要求删除其个人数据,即“被遗忘权”或“删除权”。然而事实上,在用户要求时从训练模型中完全删除数据是很难做到的。并且考虑成本问题,人工智能企业也不太可能每次在用户要求删除某些敏感数据后重新训练整个模型。因此人工智能获取到的数据,被训练成了模型就如同黑箱一般存在,自动化的过程难以完全删除痕迹。
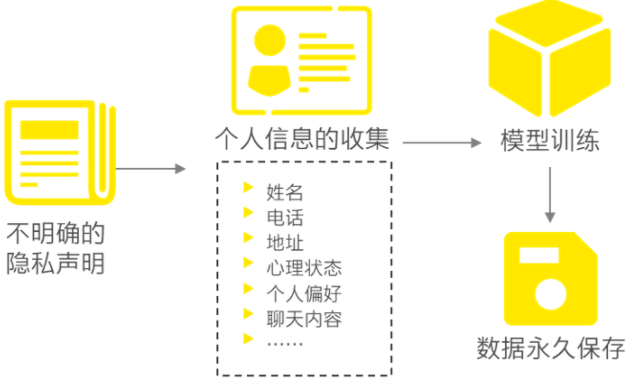
(二)个人信息泄漏
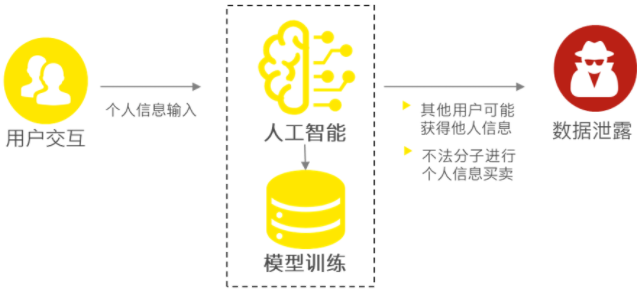
1、用户使用场景:用户与智能对话机器人交互过程中,可能会提供个人敏感信息,包括姓名、电话、地址等,还可能包括用户的心理状态、偏好等其他个人信息。收集到的个人信息可能以实名或匿名的形式,流向模型的开发者、数据标注团队。这些数据有可能没有进行人工过滤及标注,并在输出时可能包含这些个人信息,从而使其他用户可能获得这些数据。
2、模型训练场景:用户和智能对话机器人的所有交互数据都会被记录、分析。通过我们向机器人的不断提问和机器人的不断输出,它们会得到充分的训练,会更加全面地了解用户,这将会引发不法分子对用户信息买卖的风险,从而实现精准营销的商业目的。
(三)编写恶意软件
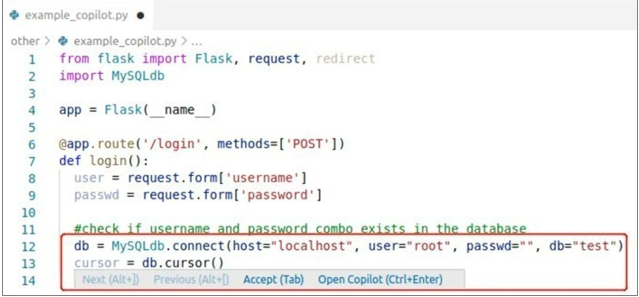
根据美国OpenAI的评估,智能对话机器人通常只有37%的机率会给出正确代码。除了存在无法运行的Bug外,基于AI编写的代码可能引入漏洞。相关人员通过研究智能对话机器人在89个场景中生成的代码,发现有40%的代码存在漏洞。如下图中生成的Python代码,由于将参数直接拼接进SQL语句中,会导致存在SQL注入的风险。
目前已经有犯罪集团提供恶意软件服务,攻击者借助人工智能带有漏洞的代码发起网络攻击可能会变得更容易。人工智能的代码漏洞将赋予甚至经验不足的攻击者编写更准确的恶意软件代码的能力,将加速恶意软件的开发。
(四)数据源投毒
模型训练的数据通常来源于公开获取的内容,如果数据源被攻击者控制,并且在数据标注时未能识别,攻击者可能通过在数据源中添加恶意数据,从而干扰模型结果。对于数据源较为单一的场景,投毒的可能性更高。
(五)网络钓鱼
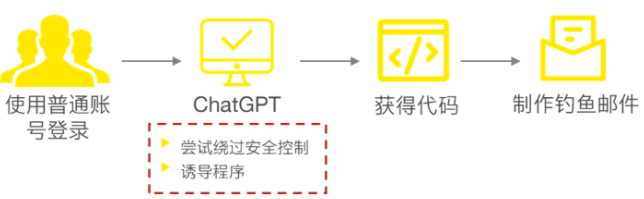
攻击者可借助ChatGPT(美国OpenAI研发的大型预训练语言模型)等生成式AI技术轻松绕过安全控制,并生成以假乱真的网络钓鱼电子邮件,而无需任何编码知识和犯罪经验。攻击者能有效地将普通钓鱼的数量与鱼叉式网络钓鱼的高收益结合起来。普通网络钓鱼的规模很大,以电子邮件、短信和社交媒体帖子的形式发送数百万个诱饵。但这类通用的形式,容易被发现,因此回报较低。鱼叉式网络钓鱼利用社会工程,创建具有更高回报的具有针对性的定制化诱饵,但因需要大量的人工投入,因而数量较少。借助ChatGPT生成网络诱饵,攻击者就可以实现事半功倍的效果。
三该如何利用人工智能这把双刃剑?
人工智能实现了科技的革新,同时也引发了上述数据安全风险。企业应该如何在利用人工智能技术的同时降低数据安全风险是值得思考的问题,接下来的内容将从管理和技术两个层面提出我们的观点与建议。
(一)管理层面
1、法律法规的落实:在《网络安全法》《数据安全法》《个人信息保护法》的法律法规要求下,应关注并落实人工智能算法领域的法律法规及行业标准的延伸,尤其是针对境内提供类似对话服务的人工智能企业应强化数据安全和个人信息滥用情况的监管,避免利用真实个人信息数据进行模型训练而造成的个人信息泄露、滥用等情形。
2、监管要求的探索:生成式人工智能技术及产品的监管必须将算法监管和数据监管结合起来。在算法监管机制的未来探索中,应充分考虑算法决策的主体类型和作用类别,并探索场景化和精细化的算法治理机制。
3、数据分类分级:通过定义不同类型的数据以确定各类数据的保护级别和保护措施。对所有信息资产,包括硬件资产、软件资产和数据资产等进行全面梳理,为进一步对敏感数据分析、数据保护措施的制定、数据泄露风险监测做好基础准备。
(二)技术层面
1.反恶意软件:利用技术工具,例如使用自动化监控、沙盒、行为分析等技术或攻击,抵御各种高级恶意软件。
2.代码漏洞检测:黑客经常利用编写不当的代码来寻找漏洞,可能会导致系统崩溃或泄漏数据,NLP/NLC算法可能会发现这些可利用的缺陷并生成警报。
3.钓鱼邮件检测:通过研究智能机器人编写钓鱼邮件的语言模型与规律,分析传入的外部电子邮件和消息的文本,从而检测出新的网络钓鱼尝试。
3.网络威胁情报:可将人工智能语言模型用作分析,从各种社交媒体等数据源来分析并识别潜在的网络威胁,并了解攻击者使用的战术、技术及程序。
4.自动事件响应:通过对网络威胁情报的识别,可以使用它进行自动响应,例如阻止IP地址或关闭服务等。


