本文来自电子发烧友网,作者/程文智。
随着互联网、移动互联网,以及物联网的发展,人类创造的数据量在快速增加,这些海量的数据为AI的发展提供了肥沃的土壤。加上神经网络算法的进步,及CPU、GPU、NPU、FPGA等各种芯片性能的快速提升,极大地提升了计算机处理海量视频、图像等数据的计算能力。也就是说,在算力、算法和数据三要素快速发展的背景下,AI技术的成熟度越来越高,AI产业不断演进,落地应用也变得更加丰富,AI正在与各行各业的典型应用场景相融合。
这些年,可以明显看到AI在智能手机、智能音箱等消费类电子产品,以及互联网应用等To C端的应用场景中大量落地后,开始向工业制造、能源、交通、金融、医疗、教育、零售、汽车等传统To B端行业渗透。
现在的AI技术已经开始渗透进人们日常生活的方方面面了,那么什么样的AI最有前景,最容易被市场所接受呢?其实未来的AI落地应用可能更多的是一些碎片化的市场,能够在性能和成本之间取得良好平衡的应用可能更加有市场前景。
碎片化将增加企业成本
不论是工业制造、能源、金融、还是交通行业,很多应用场景都是需要根据具体的场景做更多定制化的服务,这必然会增加AI企业的成本负担。比如在工业场景中,AI企业需要帮助工厂设计并训练工业级的高性能AI模型,这就需要AI企业大量的成本投入和深厚的技术沉淀,包括多场景海量数据收集、复杂模型的设计和算法训练、以及包括软件框架和硬件系统在内的AI基础设施来支持大规模运算。而且,由于每个工厂制造的产品是不一样的,产线环境也各不相同,开发的解决方案可能只适用于一家客户,成本得不到均摊,自然就会更高。
还有在交通领域,AI需要对特殊的交通事故、道路塌陷、以及火灾等不同场景进行识别、分析、评估损失等,这些都是极其具体的要求。
碎片化的应用场景还可能会带来另一个问题,由于单个场景发生的频次比较低,可用的数据量会偏少。加上每种模型的生产都需要大量的算力和人力,AI行业的人力投入将会增加,相应AI企业的成本也会增加。
当然,这些碎片化的应用场景,也会有一些好处,那就是大部分的客户其实是不懂AI的,他们需要的不是一个AI模块,或者开发包,而是一整套定制化的解决方案,而且,因为这种定制化的方案确实也帮助他们解决了实际问题,因此,他们也更愿意为此类解决方案付费。
AI背后的NPU
所有落地AI应用中,都需要硬件的算力支持,包括目前市场比较火热的自动驾驶。随着汽车中摄像头、毫米波雷达、激光雷达,以及超声波雷达等环境感知传感器的增多,自动驾驶系统收集的传感器数据将会更多,自动驾驶计算芯片需要通过算法处理、汇算这些数据,实现车、路、人等信息融合,对驾驶控制做出决策。而传感器数量的增多,对自动驾驶计算芯片的算力要求将显著提升。
而算力的提升,离不开NPU(Neural-network Processing Unit,神经网络处理器)的支持。它是一类基于DSA(Domain Specific Architecture)领域专用架构技术的专用于人工智能(特别是人工神经网络、机器视觉、机器学习等)硬件加速的微处理器。相比于CPU、GPU,NPU在硬件架构上就是针对AI设计的,非常适合神经网络运算。
NPU与CPU和GPU等通用处理器设计思路不同。通用处理器考虑到计算的通用性,提升的计算能力大部分不能直接转化为神经网络处理能力的提升,比如没有针对MAC运算做专门的提升,而NPU针对神经网络设计,无需考虑神经网络并不需要一些计算单元。相较于CPU擅长处理任务和发号施令,GPU擅长进行图像处理、并行计算,NPU更擅长处理人工智能任务。NPU通过突触权重实现存储和计算一体化,从而提高运行效率。
因此,我们可以在很多支持AI应用的处理器,或者SoC中发现NPU的身影,比如苹果的A15、特斯拉的FSD芯片、地平线的征程系列芯片、OPPO的马里亚纳X芯片等等。除了这些规模较大,性能较高的SoC芯片,其实现在有些MCU产品也开始集成NPU模块了,以满足一些边缘智能应用的需求。
其实,很多支持AI的SoC芯片都是通过集成神经网络IP来实现的,一般来说,神经网络IP会于神经网络算法同步发展,能够进一步扩展,以应对神经网络性能日益增长的需求。
新思科技ARC NPX6 NPU IP
新思科技最近推出了全新的NPU IP核和工具链,以满足神经网络不断发展的需求。同时提供了强大的可扩展性,单个NPU处理器支持从4K MAC到96K MAC的扩展,可以满足不同的应用需求,比如:ADAS,监控,数据电视,摄像头,自然语言处理等等。其ARC NPX6和NPX6FS NPU IP可满足面向AI应用的具有超低功耗的实时计算需求,提供业界最佳性能,并支持最新、复杂的神经网络模型。
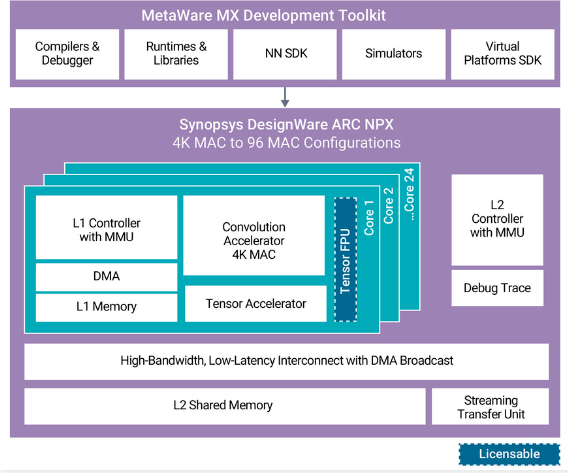
图:ARC NPX6 NPU IP
单个NPU可在5nm工艺中以每秒1.3GHz的速率提供高达250TOPS的算力,或通过使用全新稀疏特征提供高达440TOPS的算力,因此可以提高执行神经网络性能并降低能耗需求;新IP集成了硬件和软件链接功能,支持实施多个NPU实例,在单个SoC上可以实现高达3500TOPS的性能;在神经处理硬件内部提供可选的16位浮点支持,以极大提高层性能,并简化了从用于AI原型设计的GPU向大容量功耗和面积优化型SoC的过渡。
ARC NPX6FS NPU IP是针对功能安全应用的神经网络处理器IP,它满足严格的随机硬件故障检测和系统功能安全开发流程要求,完全符合ISO 26262汽车安全完整性等级(ASIL)D级标准。并且,这些处理器包含全面的安全文档,具有符合ISO 26262标准的专用安全机制,并满足下一代区域架构的混合关键性和虚拟化要求。
此外,为了方便工程师使用,加快产品上市时间,新思科技还提供了全新的DesignWare ARC MetaWare MX开发工具包,该工具包包括了编译器和调试器、神经网络软件开发工具包、虚拟平台软件开发工具包、运行时库以及先进仿真模型。
MetaWare MX提供的单一工具链在MAC资源中自动划分算法以实现高效处理,帮助工程师加速应用开发。另外,对于安全关键型汽车应用,该MetaWare MX安全开发工具包包含了安全手册和安全指南,可帮助开发者满足ISO 26262要求并为ISO 26262合规性测试做好准备。
结语
AI技术正在跟各个细分行业紧密结合,以发挥其优势,在AI技术落地应用越来越多的时候,NPU也变得越来越重要,未来对NPU的需求也将会进一步提升,相信NPU的大时代正在来临。
