本文来自微信公众号“安全牛”。
一.概述
随着机器学习方法越来越多地应用于网络安全领域的数据分析中,如果模型无意中从训练数据中捕获了敏感信息,则在一定程度上存在隐私泄露的风险。由于训练数据会长期存在于模型参数中,如果向模型输入一些具有诱导性质的数据,则有可能直接输出训练样本[1]。同时,当敏感数据意外进入模型训练,从数据保护的角度出发,如何使模型遗忘这些敏感数据或特征并保证模型效果成了亟待解决的问题。
本文介绍了一种基于模型参数的封闭式更新来实现数据遗忘的方法,这一工作来自2023年Network and Distributed System Security(NDSS)Symposium的一篇论文[3],无论模型的损失函数是否为凸函数,这一方法均可以实现显著的特征和标签数据遗忘的效果。
二.常见的模型数据遗忘方法
目前常用的机器学习数据遗忘方法包括以下几种:可以在删除数据后重新训练,这一方法要求保留原始数据且从头训练较为昂贵。当需要改动的数据并非独立存在,或者存在大量数据需要被脱敏时,通过删除数据来重新训练模型的方法难度也较大。另有研究通过部分逆转机器学习的学习过程[2],并在此过程中删除已学习的数据点,从而满足减少隐私泄露的需求。然而这一方法的计算效率通常较低,且对模型准确性产生一定的影响,所以在实际操作时可行性较低。
此外,研究人员也提出了分片法,通过将数据分割成独立的分区,基于每个分区训练子模型并聚合成最终模型。在分片法中,可以通过仅重新训练受影响的子模型来实现数据点的遗忘,同时其余子模型保持不变。这一方法的缺点在于,当需要改变多个数据点时,重新训练的效率会迅速下降,随着需要删除的数据点数量增加,所有子模型需要被重新训练的概率也显著提高。例如,当分片数量为20时,移除150个数据点就需要对所有分片进行更新,即随着受影响数据点的数据增加,分片法相对于再训练的运行效率优势逐渐消失。其次,相对于移除受影响的特征和标签而言,移除整个数据点会降低再训练模型的性能。
三.设计思路
为了解决这一问题,本文介绍的方法从解决特征和标签中隐私问题的角度出发,将移除数据点转化为模型的封闭式参数更新,从而实现在训练数据中的任意位置校正特征和标签,如图1所示。

图1(a)基于实例的数据遗忘和(b)基于特征和标签的数据遗忘
当隐私问题涉及多个数据点,但仅限于特定的特征和标签时,使用这一方法比删除数据点更加有效。此外,该方法具有较高的灵活性,不仅可以用于修改特征和标签,也可以用于删除数据点替代现有方法。
该方法是基于影响函数(influence function)进行模型参数更新的,这一函数应用广泛,可以用来衡量样本对模型参数的影响程度,即描述样本的重要性。使用影响函数可以在不改变模型的情况下,获得与原模型相似性的度量结果。
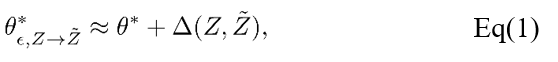
常用的对数据点或者特征的修改包括:数据点的修改、特征的修改和特征的删除。其中,特征的删除会改变模型输入的维数。由于对于一大类机器学习模型而言,将需要删除的特征的值设置为零并再次训练,和将特征删除的训练结果是等价的,因此该方法选择将特征的删除改为将其值设置为零。该方法实现了两种更新的方式:一阶更新和二阶更新。思路是寻找到能够叠加到新模型用于数据遗忘的更新。第一种方式是基于损失函数的梯度,因此可以被应用于任何损失可导的模型,其中τ为遗忘速率。
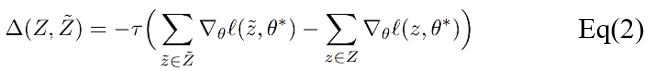
第二种方式包含二阶导数,因此限制了这一方式只能应用于具有可逆Hessian矩阵的损失函数。从技术上讲,在常见的机器学习模型中应用二阶导数更新十分简单,但对于大型模型来说,逆Hessian矩阵通常较难计算。
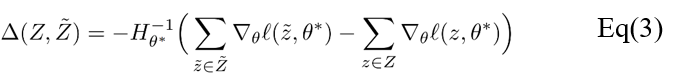
对于具有少量参数的模型,可以预先计算逆Hessian矩阵并存储,随后每次进行数据遗忘操作仅仅涉及简单的矩阵向量乘法,因此计算效率非常高。例如在测试中,已证明从具有大约2000个参数的线性模型中去除特征可以在一秒钟内完成。对于深度神经网络这类复杂模型而言,由于Hessian矩阵较大难以存储,因此可以使用近似逆Hessian矩阵替代。在测试结果中,对具有330万参数的递归神经网络进行二阶更新,所需时间不到30秒。
四.样例展示
对于测试的实例,这一工作均以三个指标来对本文提出的方法进行效果分析:(1)数据遗忘的效果,(2)保证模型的质量,(3)比重新训练效率更高。为了将该方法与已有的机器学习模型的数据遗忘方法进行比较,本工作选取再训练、分片等方法作为基线。
4.1
敏感特征遗忘
该方法首先应用于在真实数据集上训练的逻辑回归模型,包括垃圾邮件过滤、Android恶意软件检测、糖尿病预测等。对于特征维度较多的数据集,比如电子邮件和Android应用数据集,该方法分别选取与个人姓名相关的维度和Android应用中提取的URL作为敏感特征,并从模型中移除整个特征维度。对于特征维度较少的数据集,该方法选择替换选定的特征值,例如对于糖尿病数据集,可以对个体的年龄、体重指数和性别等特征值进行调整,而非直接删除。图2中展示了分别移除或替换100个特征时糖尿病和恶意软件数据集的效果。我们观察到,二阶更新非常接近再训练,因为这些点靠近对角线。相比之下,其他方法不能总是适应分布的变化,从而导致更大的差异。
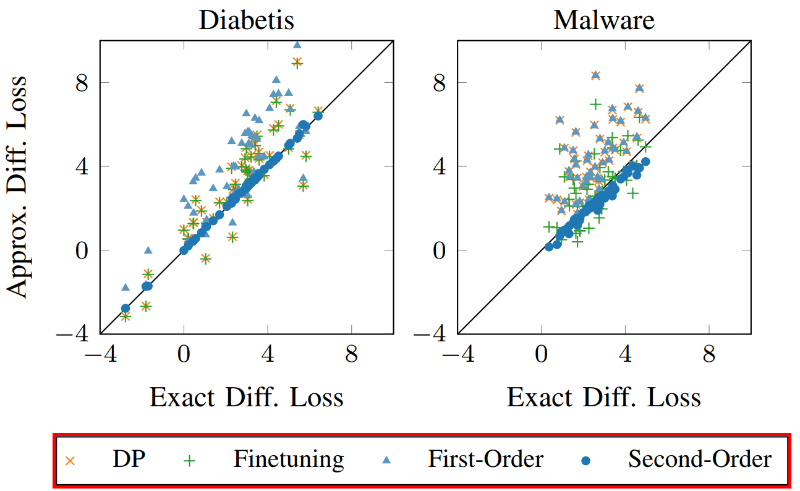
图2受影响的特征数量为100个时,再训练和数据遗忘方法间的损失差异
4.2
无意识记忆的遗忘
已有研究展示部分语言学习模型能够形成对训练数据中稀有输入的记忆,并在应用过程中准确地展示这些输入数据[4]。如果这类无意识记忆中包含隐私等敏感信息,则存在隐私泄露问题。由于语言模型为非凸损失函数,无法从理论上验证数据遗忘效果。此外,因为模型优化的过程存在不确定性且可能陷入局部最小值,所有难以与重新训练的模型进行比较。基于以上限制,这一工作选择使用暴露度量(exposure matric)来评估数据遗忘的效果。
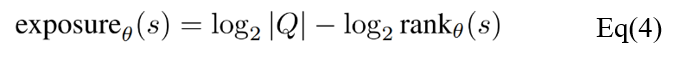
其中s是一个序列,Q是给定字母表的情况下,具有相同长度的可能序列的集合。暴露度量能够描述序列s相对于由模型生成的相同长度的所有可能序列的可能性。如表1所示,对于所有序列长度,一阶和二阶更新方法的暴露值均接近0,即不可能提取出敏感序列。
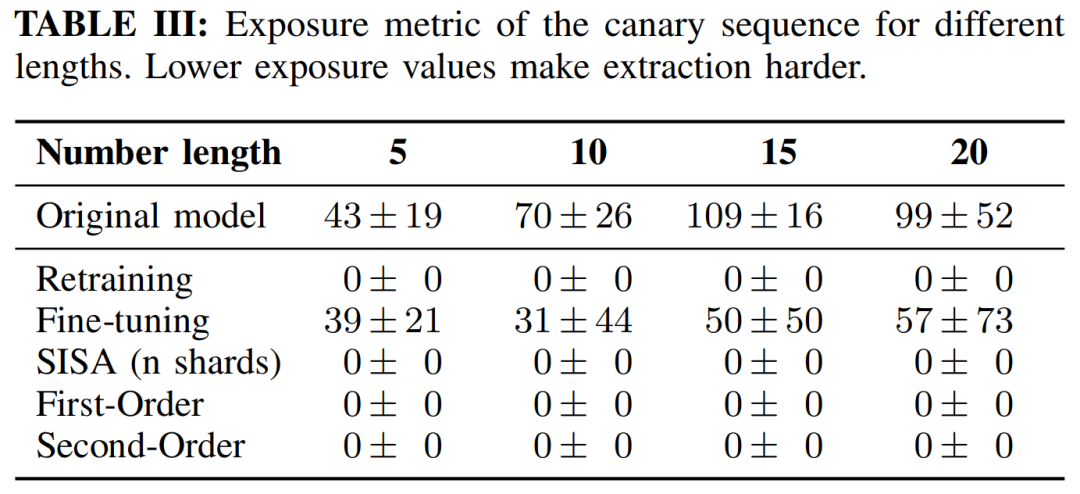
表1不同长度序列的暴露度量(暴露值越低,提取越困难)
五.结论
通过在不同场景下应用这一数据遗忘方法,证明了该策略具有高效准确的优势。对于损失函数为凸函数的逻辑回归和支持向量机等,可以从理论上保证从模型中移除特征和标签。经过在实际操作中的验证,该方法与其他数据遗忘的方法相比,具有更高的效率和相似的准确度,且只需要一小部分的训练数据,适用于原始数据不可用的情况。
与此同时,这一工作中的数据遗忘方法的效率随着受影响特征和标签的数量增加而降低,目前可以有效地处理数百个敏感特征和数千个标签的隐私泄露问题,但是较难在数百万个数据点上实现,具有一定的局限性。此外,对于深度学习的神经网络等损失函数并非凸函数的模型而言,该方法无法从理论上保证在非凸损失函数的模型中实现数据遗忘功能,但可以通过其他方式对数据遗忘的功效进行度量。应用于生成式语言模型时,能够在保留模型功能的基础上消除无意识的记忆,从而避免敏感数据泄露的问题。
参考文献
[1]X.Ling et al.,Extracting Training Data from Large Language Models,in USENIX Security Symposium,2021.
[2]L.Bourtoule et al.,“Machine unlearning”,in IEEE Symposium on Security and Privacy(S&P),2021.
[3]Alexander Warnecke et al.,“Machine Unlearning of Features and Labels”,in NDSS 2023.
[4]N.Carlini et al.,“The secret sharer:Evaluating and testing unintended memorization in neural networks,”in USENIX Security Symposium,2019,pp.267–284
