本文来自微信公众号“ruby的数据漫谈”,作者/ruby。
这篇文章介绍了实时数据仓库的基本概念和技术架构,以及最新的实时数仓架构和云原生实时数仓架构的核心能力。实时数据仓库强调数据的即时性和实时性,能够接收和处理实时产生的数据,并将其快速集成和存储,以实现实时分析和查询。实时数据仓库的基本组件包括数据源、实时数据采集、数据存储、数据实时处理和数据服务。最新的实时数仓架构使用实时流处理引擎和HTAP数据库完成流批处理一体的实时数据仓库。云原生实时数仓架构具有实时数据采集能力、分布式数据存储能力、HTAP数据库能力、实时变更自动捕获能力、流批处理能力和云原生的计算资源和存储资源的弹性伸缩能力。
01
什么是实时数据仓库?
实时数据仓库是一种存储、管理和处理实时数据的技术架构。它允许企业在实时或接近实时的情况下进行数据分析、报表生成和业务决策。与传统的批处理数据仓库不同,实时数据仓库强调数据的即时性和实时性。它能够接收和处理实时产生的数据,并将其快速集成和存储,以便实时分析和查询。实时数据仓库通常使用数据复制和流式处理技术,以确保数据的实时传输和处理。之前已经介绍过很三种类型的实时数据仓库的技术架构,都存在一定的缺陷,具体详见《实时数仓&流批一体技术发展趋势》。目前最新的实时数仓架构是有实时流处理引擎和HTAP数据库完成的流批处理一体的实时数仓,该种技术架构是目前实时数仓和流程处理的发展趋势。
实时数仓架构的基本组件有哪些了?
1.数据源:实时数据仓库的数据源可以是各种数据系统,如关系数据库、NoSQL数据库、文件系统、传感器等。这些数据源提供实时生成的数据。
2.实时数据采集:数据采集是指从数据源中实时提取数据并将其传输到实时数据仓库的过程。这可以通过各种技术实现,包括数据复制、流数据处理等。
3.数据存储:实时数据仓库需要有适当的数据存储系统来存储实时生成的数据。常见的存储系统包括HTAP数据库数据库、列式数据库等。
4.数据实时处理:数据处理是针对实时数据仓库中的数据进行分析和处理的过程。一般是流式处理引擎。
5.数据服务:数据服务将分析的结构以多种分析结果的方式提供给BI使用。这可以通过仪表盘、报表、图表、地图等方式实现。
这些组件相互配合,构成了实时数据仓库的基本架构。根据具体的需求和技术选择,实时数据仓库的各个组件可能会有所不同。
对应于该技术架构图如下所示:
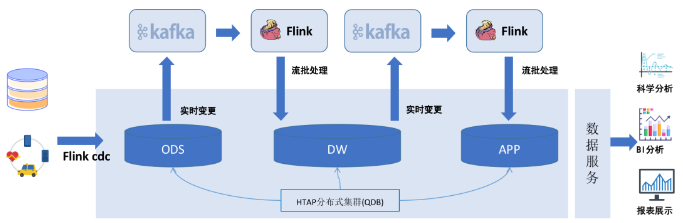
该技术架构主要的优势主要体现在HTAP分布式集群和流批处理引擎flink.将整体的流式处理实时存储和存储在HTAP数据库,即有数据处理实时能力,又具备数据统一存储的分布式架构,另外具备数据统一管理的元数据管理能力和,HTAP数据库需要的ACID事务处理能力,保证数据处理过程中的事务性和数据分析的能力。
02
云原生实时数仓架构核心能力
基于云原生的实时数仓架构的核心能力主要体现在实时数据采集能力、分布式数据存储能力,HTAP数据库能力、实时变更自动捕获能力、流批处理能力,云原生的计算资源和存储资源的弹性伸缩能力。
一、Flink CDC
1、Flink CDC可以与各种数据源进行集成,如关系型数据库(如MySQL、PostgreSQL、Oracle等)、消息队列(如Kafka、RabbitMQ等)以及文件系统等。这使得Flink CDC能够实时采集这些数据源中的增量更新或变化。
2、增量数据抓取:Flink CDC可以通过监视数据库的日志或轮询查询方式,捕获数据源中的增量更新或变化。这使得Flink CDC能够实时获取数据源中的新数据,并按照变化进行处理和传输。
3、Flink CDC提供了容错机制和一致性保证,以确保在数据采集过程中的数据可靠。
二、分布式数据存储能力
由于实时数据仓库需要存储ODS、DW、APP的数据,因此,分布式数据存储通过集群管理存储的数据,按需分配存储的数据库的存储空间,实现弹性伸缩能力。
1.数据分片:将数据分成多个片(shard),并将这些数据片分布存储在不同的节点上。每个数据片包含部分数据,通过使用分片键(shard key)进行数据的分配和定位。
2.数据复制:为了提高数据的可靠性和容错性,分布式数据库会将数据复制到不同的节点上。数据复制可以使用主备模式,其中一个节点作为主节点,其他节点作为备份节点,同步复制主节点上的数据。
3.数据一致性:在分布式环境中,数据一致性是一个关键的问题。分布式数据库通过使用一致性协议(如Paxos或Raft)来确保数据在不同节点之间的一致性。
4.数据分发和负载均衡:在分布式环境中,需要将请求分发到适当的节点上进行处理,并确保各个节点上的负载均衡。分布式数据库使用路由算法和负载均衡策略来实现数据请求的分发和负载均衡。
5.数据恢复和故障转移:当节点发生故障或失效时,分布式数据库能够自动进行数据恢复和故障转移,将受影响的数据重新分配到其他正常运行的节点上。
三、HTAP数据库(Hybrid Transactional/Analytical Processing)
HTAP数据库是即可以支持OLTP又可以支持OLAP能力的数据。需要具备以下能力:
1、ACID事务处理能力:HTAP数据库能够处理大量的并发事务,保证数据的一致性和可靠性。
2、实时分析能力:HTAP数据库可以实时对数据进行分析和查询,不需要将数据从事务处理系统导入到分析系统中。
3、混合工作负载能力:HTAP数据库可以同时支持事务处理和分析查询两种不同的工作负载,而不需要分别使用不同的数据库系统。
4、数据复用能力:HTAP数据库可以将事务处理过程中产生的数据直接用于分析查询,避免了数据复制的成本和延迟。
5、数据一致性能力:HTAP数据库可以保证事务处理和分析查询之间的数据一致性,避免了数据冲突和脏数据问题。
四、实时变更自动捕获能力
实时变更自动捕获能力是指数据库系统能够自动捕获和处理实时变更(real-time change data capture,CDC)的能力。具体来说,它可以实时跟踪和捕获数据库中的数据变更,并将这些变更信息存储到一个特定的位置,以供进一步的处理和分析。实时变更一般是指表的新增、修改、删除的数据动作,而大部分是以日志的形势记录,将该日志自动获取到,推动到固定的kafka Topic中。
五、Flink的流批处理能力
Flink提供了一个高效、容错、分布式的流处理引擎,可以处理实时的数据流。它支持事件时间和处理时间的窗口操作、流水线优化、低延迟的事件处理、状态管理等特性,可以用于构建实时数据处理应用。Flink不仅支持流处理,还提供了强大的批处理能力。用户可以使用Flink的DataSet API进行批处理操作,执行离线的数据分析和批量计算任务。Flink提供了强大的状态管理机制,可以处理大规模的状态(如窗口状态、键控状态),同时保证状态的一致性和容错性。这使得Flink在流和批处理场景下能够高效地管理和处理状态信息。
详细了解可以参见《Flink的高阶API-Table API&SQL》、《Flink通过哪些功能支持实时开发了?》
六、云原生的计算资源和存储资源的弹性伸缩能力
1、弹性和可扩展性:在flink cdc、kafka、分布式存储、flink组件都可以采用云原生的构建和部署方式。云原生部署方式可以利用云计算环境的资源弹性和可扩展性,根据需要自动伸缩应用服务的数量和资源使用。
2、微服务架构:云原生数据服务采用微服务架构,将数据fu无拆分为一组松耦合、可独立部署、可单独扩展的微小服务。这样可以提高应用程序的可维护性、可扩展性和可部署性。
03
与其它实时数仓架构的区别
其它实时数据仓库的架构一般采用的kappa技术架构,如下图所示:
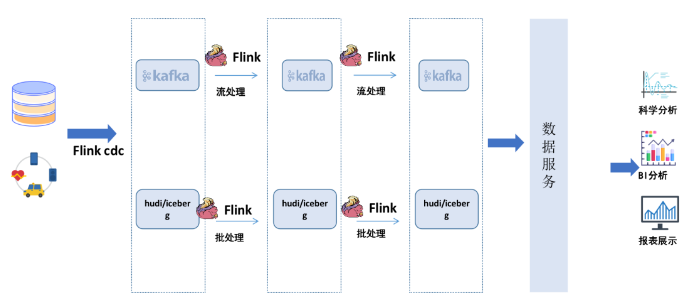
这种架构利用了kappa的技术架构和数据湖的能力确实实现了湖仓一体和流批处理一体,但是它在数据处理上还是采用了2套数据存储流程,主要原因是kafka一般情况下只能存储几天的数据,不能拥有分布式存储这种大批量的数据存储能力。另外kappa技术架构还有以下缺陷:
1、数据的一次性处理、重处理困难:Kappa架构中的流处理系统只会处理实时数据,而不会处理历史数据。这意味着如果需要对历史数据进行分析或处理,就需要使用额外的批处理系统。这可能导致处理数据的复杂性和延迟增加。
2、数据的回溯困难:由于Kappa架构只处理实时数据,当需要回溯之前的数据时,可能遇到困难。因为流处理系统通常仅保留一段时间内的数据,之前的数据可能已被删除或丢失。如果需要对过去的数据进行分析或重现特定时刻的状态,就需要借助其他方式来处理。
3、增加批处理,增加了系统的复杂度:在Kappa架构只处理实时数据,意味着在数据处理过程中难以调试、当数据处理出现问题的时候,难以追踪到具体的数据和逻辑,需要增加批处理流程以实现在流式处理出现问题的时候,采用批处理来弥补错误,这样会造成系统的复杂性。
以上是该架构的一些缺陷,而最新的云原生的实时数仓架构是真正的流批一体架构,不需要维护两套数据处理流程,开发简单,数据追踪容易,统一的元数据管理。大大降低了实时开发的难度和代码维护的难度。
注:ACID事务处理能力是指数据库系统能够满足ACID属性的特性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
1.原子性(Atomicity):事务中的操作要么全部执行成功,要么全部失败回滚,不存在部分执行成功部分失败的情况。如果一个事务中的任何一个操作失败,数据库会自动撤销所有事务执行的操作,将数据库恢复到事务开始之前的状态,保证数据的一致性。
2.一致性(Consistency):事务在执行之前和执行之后,数据库的状态都必须保持一致。这意味着事务必须满足所有定义的数据库约束和规则,不会破坏数据的完整性。
3.隔离性(Isolation):每个事务的执行都是相互隔离的,保证事务之间的相互影响最小。并发执行的多个事务之间不能互相干扰,每个事务都认为它是在独占地使用数据库,避免了数据读取的问题(如脏读、不可重复读和虚读)。
4.持久性(Durability):一旦事务提交,其修改的数据将永久保存在数据库中,即使在系统发生故障时也不会丢失。数据库使用一种可靠的机制来确保数据的持久性,如写入日志文件。
ACID事务处理能力是保证数据库的数据一致性和可靠性的重要特性,能够确保数据库在并发环境下的正确运行和可靠性。
