前言
随着容器技术的出现,我们开发出的应用程序才可以真正实现开发运维一体化的愿景,因为它比传统虚拟机定义了更具标准化的打包方式及更轻量级的运行状态。当业务很多时,如果我们只在一台主机上部署就不能满足业务的高可用、负载的可扩容性等需求,这时就需要我们在多台主机上部署,因此出现了集群化、分布式等技术。
那我们如何在这些主机上更高效的管理这些容器,并以某些方式暴露所部署的应用服务?这就需要用到容器编排技术了,因此从2014年开始,容器领域就诞生了以Mesos、Docker Swarm及Kubernetes为代表的容器编排系统。在过去这几年间,容器编排技术已经呈现出“三国鼎立”之态势,各有个的用户群体,各有个的活动社区,但2017年至今Kubernetes已经成为真正的领导者。一种新的技术的兴起,注定会带动围绕其出现的其他新技术的崛起,这包括了容器存储、容器网络、容器日志管理及监控告警、CI/CD(持续集成/持续交付)等相关领域的技术,从而构成了我们今天火热的容器生态圈。
在容器编排技术之上,我们为了更好的让开发者使用这个编排系统,就有了容器平台的出现,典型开源代表都包括CI/CD、灰度发布、滚动升级、自动扩缩容、租户管理、安全认证等等功能模块。每一个模块也都涌现出了很多新的技术代表,这些又构成了我们今天大势宣传的云原生技术。
那这么多新技术组合在一起,当我们的容器平台或者部署在其上的业务出现问题时,我们该如何分析、定位并最后排除?这就是一个摆在云容器工作者面前的重要问题。本文将分享一些解决问题的思路、方法,由于容器平台涉及的问题太过宽广,使用的技术涉及知识面也很多,不能一一列举,只能点到为止。
一个问题的解决一般需要经过问题的分析、定位、复现到最后排除与解决等过程。每个过程几乎都环环相扣,只有肯定了前一个过程,才利于后续过程进行,当然这些过程可能会出现相互否定的时候,但经过几番否定后,最终会形成一个确定的方向,即定位出了问题点。再根据我们分析与排查中产生的思路、利用相关的工具及方法等进行问题复现,当问题复现后,问题就基本解决了70%,接下来就是找到解决该问题的方法以及排除它,这个占了30%,至此一个问题就解决了。
在容器平台中,我们除了会涉及操作系统层面的知识,还会涉及容器存储、容器网络、容器日志管理及监控告警、CI/CD(持续集成/持续交付)等相关领域的技术。每个领域都有可能是问题的产生点,只有在分析定位出具体点时,我们才好依据该技术相关工具或者阅读源码来解决它。
分析问题就是需要了解问题发生的时间点,问题发生时的上下文,环境场景等,并分析问题之间的关联关系,应用“简单化原则”,这些都是我们分析问题的基础。
下面我会穿插一个实际案例来分享一下整个排错过程。
问题背景:容器平台上线一年多后,总有很少部分租户称他们的某个业务部署在Kubernetes容器平台后经常会重启,也很少部分租户称某个业务在运行一段时间时会产生大量的`CLOSE-WAIT`,还有租户反馈说某个业务跑着就会hang住。刚开始我们都会让业务开发者先自己找问题,因为这些租户反映的只是偶偶发生,大多数租户没有反映类似问题,我们会理所当然的认为是租户业务自身问题,而非平台问题。当然大多数情况下,还是租户业务本身程序没有写好,或者健康检查配置不当等引起。
1简单化原则
当我们在排查某个问题时,我们可以回想一下,最近发生了哪些问题,这些问题是否相互之间有关联关系,如果可能有关联关系,那么就可以利用现有解决方案进行修复。
我要分享的这三个问题,经过我们排查后,都是同一个问题引起。像这种情况就需要我们进行初步地关联分析,并按照问题发生的难易程度进行排查。
比如,我们可以这样分析,假设这三个问题有关联的话,那么会不会是服务hang住了触发了其它两个?即hang住了,服务自然没法响应客户端的关闭连接,此时就会产生CLOSE-WAIT;另外,如果hang住
了,而业务在K8S平台又配置了live probe保活机制,那么就会触发容器自动重启。这么看来,我们首要解决的就是hang住的问题,但hang有很多原因引起,其实这里并不好排查,顺序可以先调整一下,因为更有可能是CLOSE-WAIT过多,把业务程序打爆,导致程序hang死。所以我们先从CLOSE-WAIT这种比较常见的问题入手,这也是我们遵寻简单原则的地方。
2时间点
问题发生的时间点,可以让我们确定是在低峰还是高峰期发生的。如果是低峰期发生,很大可能是软件自身的重大问题,比如有内存泄漏、CPU使用过高、磁盘IO消耗过大等,因为低峰期流量相对比较低,不容易受外在因素的影响。如果是高峰期发生,很大可能是高并发有问题,配置有问题(比如缓存池设置过小)或者有类似死锁、竞争等产生,甚至涉及到操作系统内核参数的配置问题,这些可能是程序本身的bug。
上面这三个问题,虽不是同一段时间出现的,但我们通过故障事件统计下来,却是比较多的,这几个问题在高低峰都有出现过,所以不好排查是否是业务程序代码问题,最多说是业务代码出错可能性大点儿。
前面我说到了“故障事件统计”这个功能,这里我稍展开一下,这个其实对于容器平台工作人员来说,是一个很重要的功能,它可以帮助我们分析事件类型及其某类事件的统计值,这样方便看出在某个时间段哪些类型的事件比较多,也有利于我们定位事件之间的关联性,如果是平台问题引起,那么就可以迭代平台,进行改进。事件源可以有很多,比如Kubernetes集群本身的话,Kubernetes核心API提供了各种event事件类型,比如Pod启动情况,被调度到哪些物理节点,ReplicaSet扩缩副本数,Pod Unhealthy原因,Node NotReady信息,及与存储卷相关的PV,PVC等众多事件,这些在默认情况下,只在etcd中保存1小时。我们为了分析,可以持久化这些事件信息,比如一周,一个月等,这个可以借助于开源的[eventrouter](https://github.com/heptiolabs/eventrouter)或者阿里的[kube-eventer](https://github.com/AliyunContainerService/kube-eventer),把事件采集到日志系统进行搜索、分析、展示与告警等。在我们的生产环境中,目前就使用了kube-eventer来收集事件数据,并发送到kafka,之后通过日志系统的kafka订阅功能写入后台ElasticSearch和ClickHouse中,并借助现在日志平台进行事件统计与分析。另外,Zabbix等告警平台也会提供一些主机层面或者租户业务程序自定义埋点相关的事件告警,这些我们都可以收集起来,既可以方便查看时间点,也方便做事件统计分析。具体在这里不展开,请自行查阅相关文献。
另外,我们也要注意软件变更时间点,因为很多时候新问题的产生是由于软件变更引起的,比如容器平台软件在添加了新功能后,没有经过完整的集成测试或兼容性等系统测试,就可能会带来新的问题。当一个问题在某个时间点之后才产生,那么我们需要去看这个时间点之前所提交的程序代码,及相关的周边环境变动情况等来确定问题是否和这些相关。
虽然上面这三个问题和软件变更时间点无关,但我们在生产环境中就碰到了一次严重的“内存泄漏”事件。主要的现象就是内存由1.5G左右突然激增到35G大小,由于内存是不可压缩资源,在K8S中以Pod方式部署后,会触发Pod重启,并产生告警。我们注意到2020年3月4号之前,并未出现过该问题,之后才出现的,那么解决此问题的方法就是通过定位软件变更时间点来解决,变更时间点关联了代码提交点,所以我们只要检查2020年3月4号该时间点之前commit过了哪些代码。遗憾的是,刚开始,我们也查看了该时间段提交的代码,却没有发现什么可疑的代码。为什么前面"内存泄漏"打了双引号?就是因为我们最终排查下来,发现其现象是内存泄漏,但本质上却不是,这也是我们暂时通过代码没有发现问题的原因。
平台软件是用golang开发的,像内存泄漏这种事件,一般可以通过pprof这种内存分析工具来定位,网上有很多的教程,这里不对该工具进行展开。我们通过pprof工具获取了平台软件的pprof信息,从heap-pprof的常驻内存情况看,Runtime使用的内存只有1.5G,而系统看到整个进程的RSS内存高达35G,差距非常之大。从发生问题的时间点看,bond0流量突增,可能跟API请求的各个环节有关,涉及到外部系统调用平台API,平台内部调用Kubernetes API,这些请求无论是平台server主动发起还是被动接收,都涉及到非常多的类型转换,比如:json encoding/decoding,平台Server都需要分配相应的内存。如果请求量非常大,可能就会导致内存激增。但是并没有发生内存泄露,也就是说是正常的内存分配,这一点我们从pprof的信息得到了确定,而且被分配的内存也没有被回收,我们看到内存在增长到一定阶段后非常平稳。
那问题来了,为什么会没有被回收,golang中不是都有自带内存回收机制吗?之后,我们带着问题,就去看golang的内存回收原理,并查看了网上相关资料,其中的一篇文章《Go进程的HeapReleased上升,但是RSS不下降造成内存泄漏》(知乎)和我们遇到的现象比较像。所以最终将问题定位到GO Runtime的内存释放机制上,在Go 1.12之前,golang runtime会在未使用的内存上标志成`MADV_DONTNEED`,标记过的内存如果再次使用,会触发缺页中断,并且操作系统会立即回收未使用的内存页。从Go 1.12开始,该标志已更改为`MADV_FREE`,这告诉操作系统它可以根据需要回收一些未使用的内存页面,即内核会等到内存紧张时才会释放,在释放之前,这块内存依然可以复用。这个特性从Linux 4.5版本内核开始支持,显然,`MADV_FREE`是一种用空间换时间的优化。此时,我们再去查看该时间段提交的代码,果然发现有一个commit是在构建平台软件的docker镜像的Dockerfile中修改了Golang的语言版本,从1.11到1.12.9版本。
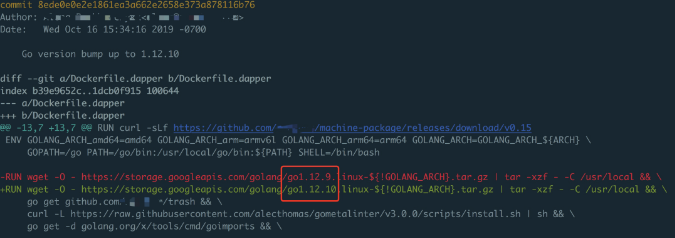
Go 1.12之后,提供了一种方式强制回退使用`MADV_DONTNEED`的方式,在执行程序前添加`GODE-BUG=madvdontneed=1`。即解决这个问题的方法是将平台软件Pod中的YAML进行修改,添加环境变量`GODEBUG=madvdontneed=1`,主动使其及时回收未在使用的内存,以释放内存空间。
3上下文
问题发生时,可以通过查看日志记录,比如某条错误的或致命的日志来查找到对应的程序执行点,这个执行点的前后程序段就是这里所说的代码的上下文,也是软件的上下文。这个与前面软件变更的时间还是有点不同,这个是当发现日志中出现了某条错误日志时,根据该日志对应的代码行来定位的。通过它我们可以分析代码中执行了哪些特定的功能模块,分析问题产生的时机,触发点等,找出一些与问题相关的蛛丝马迹。
4环境场景
环境场景主要指问题发生时,相关的外在环境,比如操作系统的内核版本、docker版本、Kubernetes版本等。如果问题的产生和这些环境相关,那么就需要考虑程序的兼容性场景,我们一般在开源社区中,给开源软件提交bug的时候,也会指定特定的软件环境,就是方便作者分析与定位问题。
