边缘计算面临的一个艰巨挑战是如何处理这样的情况:在不同地理位置的数千个集群上运行的千兆字节数据。这种描述让你想到拥有物联网传感器数据的大型工业用例,但它们并不是唯一重要的优势所在。
边缘计算在很多行业中变得非常重要。银行在用它,在线服务供应商需要它,而健康供应商、电信、公用事业和汽车制造商则使用它。这篇文章介绍了激发边缘计算的需求,这样读者就可以决定边缘设计是否对他们有用。它还分析了边缘的挑战--包括经常被忽视的挑战--并提供了一些在现实世界中行之有效的解决方案。
为什么要使用边缘计算?
边缘计算是一种很有吸引力的(通常甚至是必需的)体系结构选择,由于有限的容许时延、网络故障的潜在风险和法规要求,或者仅仅是对边缘产生的不能划算地将其传输到中心站点的数据规模做出反应等原因,边缘计算便可以在数据源附近进行计算。
边缘计算的广泛采用是由于以下几个因素:
● 由于传感器成本的降低和多样性的增加,它比以往任何时候都更容易获取数据。今天生产的几乎所有产品都内置了更多的传感器和数据通信功能。
● 网络基础设施使得将比特移到边缘的变得更便宜。
● 由于Kubernetes的进步,在核心和边缘集群中管理分布式计算变得越来越容易。
● 加固的硬件可以进行必要的数据过滤和预处理,即使在可能发生在边缘的恶劣条件下也能保持运行。
令人惊讶的是,边缘计算的最大挑战之一不是计算部分。边缘与核心之间的通信几乎是一种普遍的需求。指标和诊断数据需要移回核心计算中心,在某些情况下,数据或模型需要移动到边缘。
架构师和实施者通常假设与核心的通信是很容易处理的,然而事实的情况往往并非如此。
边缘的工作原理是什么?与核心的沟通
下面的实际用例说明了如何解决边缘计算中的挑战,包括与核心的通信。几年前,我们有一个客户,他开发了一个视频流系统。需要边缘计算,以便提供视频内容的系统接近最终用户,以最小化延迟和最大化正常运行时间。我们的客户所构建的系统运行良好,但是他们在构建遥测系统时遇到了麻烦,无法将系统健康状况和客户视频消费的数据传送回核心——这是在出现问题时向核心支持团队发出警报并进行计费所必需的数据。
这个特殊的问题非常具体,但是问题的形式——边缘计算加上从边缘到核心的遥测——对于许多其他行业来说是普遍的。在这个例子中,和通常一样,遥测技术被推迟到项目的末尾;困难被大大低估了。这就是我们的切入点。
我们所做的
为了解决将数据返回核心的典型边缘问题,我们添加了一个分布式数据结构,并使用其消息传输功能创建了一个简单可靠的解决方案。
我们的目标是支持从几十个小型边缘数据中心获取数据,并以合理的低延迟将得到的数据可靠地传输到核心数据中心进行分析和计费。临时网络分区不应影响数据完整性,并且数据应在这些分区被修复后立即传输。该系统还需要尽量减少物理故障造成的停机时间。下图说明了如何使用数据结构来满足这些需求。
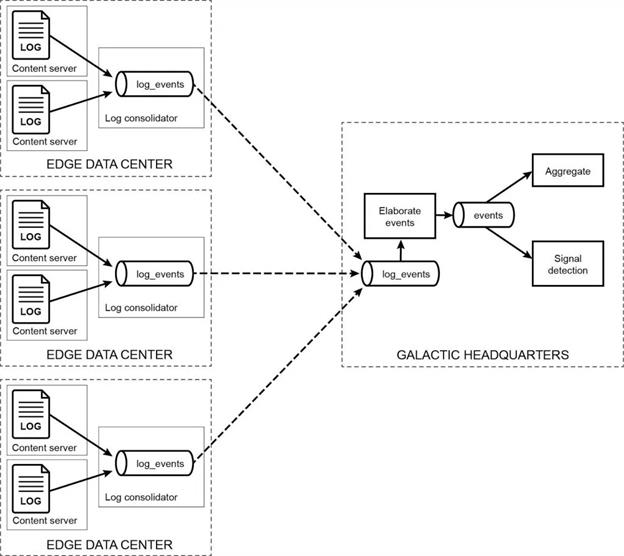
上图所示,数据结构的使用将边缘与核心连接起来,而不需要在任何一边使用复杂的系统。虚线块表示数据中心——包括边缘和核心——并提醒我们数据结构跨越了整个体系结构。深色虚线箭头显示了通过数据结构的消息传输系统(水平圆柱体)从多个边缘位置返回到总部的度量数据流。
在此之前,我们客户的开发人员曾尝试过几种遥测技术的实现,但都没有成功,结果大大落后于计划进度。相比之下,我们基于数据组的设计的传输程序能够非常简单地将消息插入到边缘的消息流中。然后数据结构处理从边缘到核心的所有数据传输。消息流中的主题记录了数据中心名、源机器名、传感器名或事件类型,因此来自所有边缘中心的所有数据都可以合并到单个消息流中,同时仍然允许对数据的任何子集进行分析。数据结构处理静态和动态数据的安全性。
这个设计非常容易实现和操作,并且能很快地使客户的开发人员按计划行事。这种设计在数年内也是非常可靠的。这种最终数据结构设计的一个特别好处是高度的关注点分离。例如,边缘数据采集独立于处理数据的中央程序。数据结构的地理位置完全由管理员指定,管理员现在可以专注于配置数据运动和访问控制,而不关心数据内容。这种关注点的分离意味着在核心和边缘运行的程序可以简单得多,只关注单个问题。这一优势适用于广泛的用例。
我们今天会做什么不同的事情(或不做)?
如果我们今天要设计这个边缘解决方案,我们仍将使用数据结构来传输数据----保留数据结构的优点来处理数据安全、数据移动、复制和高可用性容错等所有方面。但今天,通过使用Kubernetes进行容器编排,我们还将从中央软件的完全云本机实现中受益匪浅。五年前,与Kubernetes现在的位置相比,容器编排还相当原始。
具有适当功能的数据结构为在Kubernetes下运行的容器化应用程序提供数据访问和状态持久性。
补充Kubernetes在编排计算中的角色的数据持久层对于获得云原生计算的全部功能至关重要。数据将比处理它的容器寿命长。
然而,在边缘集群上,我们可能不会有什么改变——至少今天不会。然而,明天可能会是另一番景象。
剩下的挑战:会发生什么?
我们正处于边缘容器编排的关键时期,这一编排非常有用。这使得现在成为边缘计算的一个辉煌时刻。有了真正的边缘编排,就可以在边缘系统上执行比我们在原始设计中能够证明的更高级的处理,并使边缘群集的提供变得更容易。
边缘作为目的地
这个用例突出了数据进入核心的常见边缘问题。但是数据向边缘的出口呢?我们需要向边缘部署人工智能/机器学习模型,向边缘推送状态信息或报告数据,或更新运行在边缘的软件。数据结构可以使所有这些都变得非常简单,同时还可以最小化通过开放互联网访问存储库所带来的安全风险。
让数据双向移动使我们能够真正“在本地行动,但在全球学习”。
安全情况是怎样的呢?
边缘系统的安全性至关重要,因为它们面临着巨大的威胁。至少,不可能形成新的边缘集群,不可能模拟现有的集群,也不可能窃听从边缘移动到核心的数据。理想情况下,这种安全级别是基于某种信任的硅根,这种信任一直延伸到最低的硬件级别。它还应该向上扩展,以便在执行之前对所有OS和容器映像进行验证,并且数据在静止或传输时受到保护,而不需要对应用程序进行任何专门设计。
在安全硬件平台上运行的安全容器执行框架以及默认安全数据结构可以满足这些需求。但是,任何低于这一点的东西都可能会大大降低安全性。
关键的问题
● 比许多人想象的要多的行业需要边缘计算。
● 边缘计算不仅仅是在边缘计算或运行模型;将指标和操作数据拉回到核心是一个几乎无处不在且通常被忽略的需求。
● 一个从边缘到核心的统一数据结构可以处理数据在边缘之间可靠移动的问题。
● Kubernetes已经为核心的容器化计算提供了巨大的好处,在边缘使用Kubernetes的能力正在迅速成熟。
作者:Ted Dunning
Ted是HPE旗下MapR的首席技术官,他拥有着博士学位,是计算机科学专业的作者,着有超过10本专注数据科学的书。他在高级计算领域拥有25项专利。
原文链接:
https://thenewstack.io/using-data-fabric-and-kubernetes-in-edge-computing/
